Что значит заспамленность в антиплагиате
Содержание:
Термины и определения
|
Термин |
Определение |
|---|---|
|
Сервис |
Онлайн инструмент работы с текстовыми документами с пользовательским интерфейсом на web-сайте. |
|
Заимствование |
Фрагмент текста проверяемого документа, совпадающий или почти совпадающий с фрагментом текста источника и не оформленный в соответствии с правилами цитирования, без приведения полной библиографической информации об источнике. |
|
Самоцитирование |
Фрагмент текста проверяемого документа, совпадающий или почти совпадающий с фрагментом текста источника, автором или соавтором которого является автор проверяемого документа. |
|
Цитирование |
Фрагмент текста проверяемого документа, совпадающий или почти совпадающий с фрагментом текста источника и оформленный в соответствии с правилами цитирования, с полной библиографической информацией об источнике. Также к цитированиям относятся общеупотребительные выражения, библиографический список, фрагменты текста, найденные в источниках из коллекций нормативно-правовой документации. |
|
Процент заимствования |
Доля всех найденных заимствований по отношению к общему объему документа в символах. |
|
Процент самоцитирования |
Доля всех найденных самоцитирований по отношению к общему объему документа в символах. |
|
Процент цитирования |
Доля найденных цитирований по отношению к общему объему документа в символах. |
|
Процент оригинальности |
Доля фрагментов текста проверяемого документа, не обнаруженных ни в одном источнике, по которым шла проверка, по отношению к общему объему документа в символах. |
|
Отчет |
Результат проверки текста на наличие заимствований:
|
|
Доля в отчете |
Отношение объема заимствований, которое учитывается в рамках данного источника, к общему объему документа. Eсли один и тот же текст был найден в нескольких источниках, учитывается он только в одном из них. |
|
Доля в тексте |
Отношение объема заимствованного текста по данному источнику к общему объему документа. Доли в тексте по источникам не суммируются. |
|
Блоков в отчете |
Количество блоков заимствования из источника с учетом пересечений всех найденных источников. |
|
Блоков в тексте |
Количество блоков заимствования из источника без учета других найденных источников. |
|
Модуль поиска |
Программный модуль, реализующий поиск заимствований. Модуль использует поисковый индекс или специальный вычислительный алгоритм для построения отчетов. В системе может быть несколько модулей. После получения доступа к нескольким модулям поиска предоставляется возможность проводить проверки, строить как отдельные отчеты, так и единый отчет по всем модулям поиска. Некоторые модули выполняют поиск по специализированным базам данных со слепками текстов документов-источников, но получение доступа к выбранному модулю поиска не означает получение доступа к полным текстам документов, которые может найти этот модуль. В получаемых отчетах будут указаны ссылки на документы (их названия также будут даны), а при просмотре текста источника, в нем будут приведены совпадающие с проверяемым документом фрагменты. |
|
Браузер |
Программное обеспечение, позволяющее пользователям просматривать страницы сайтов интернета, а также получать доступ к файлам и программному обеспечению, связанным с этими страницами. Например, Internet Explorer, Google Chrome и т.д. |
|
Текстовые метрики |
Семантические характеристики для каждого загружаемого документа. |
Загрузка студенческой работы
Загрузить студенческую работу можно несколькими способами:
- загрузить в задание;
- загрузить по коду задания;
- загрузить по коду задания без регистрации.
Важно! Вы не можете удалить загруженную вами работу. Если вами был загружен неверный документ, обратитесь к вашему преподавателю.
В системе действует ограничение на количество символов в одном документе
Документы, содержащие более 2 миллионов символов, не проверяются. При загрузке таких документов в кабинете отобразится сообщение об ошибке.
Для загрузки студенческой работы в задание необходимо, чтобы ваш преподаватель предоставил доступ к заданию. Задание, к которому был предоставлен доступ, отображается в списке ваших заданий. В противном случае, обратитесь к вашему преподавателю.
Чтоб загрузить студенческую работу в задание, нажмите на кнопку «Загрузить в задание» и выберите файл. В открывшемся окне выберите нужное вам задание, при необходимости укажите название для вашей работы. По умолчанию название работы будет присвоено по названию исходного файла.
Важно! Сервис поддерживает самые распространенные текстовые форматы файлов: pdf (с текстовым слоем), txt, html, htm, docx, rtf, odt, pptx. Размер загружаемого файла не должен превышать 100 Мб
Формат doc не поддерживается для загрузки студенческих работ. Данный формат значительно устарел и возможны проблемы при извлечении текста документа. Переконвертируйте документ в один из доступных форматов: docx или pdf.
Окно загрузки работы в задание
Далее нажмите на кнопку «Продолжить», документ добавится в кабинет и отправится на проверку. В строке с заданием, в которое был добавлен документ, вы увидите добавленный документ, дату загрузки и результат проверки.
Чтобы загрузить студенческую работу по коду задания, который сообщил вам преподаватель, нажмите на кнопку «Загрузить по коду задания», выберите документ для загрузки и введите код задания, при необходимости измените название для вашей работы. Затем нажмите «Продолжить».
Окно с параметрами загрузки по коду
Важно! Если до этого вы не загружали работы ни в одно задание и сейчас производите загрузку по коду задания, то ваша работа будет отправлена преподавателю на подтверждение. Результаты проверки на заимствования вашей работы вы увидите только после подтверждения
Вы можете загрузить работу без регистрации на сайте, если знаете код задания и в сервисе разрешена самостоятельная регистрация студентов.
Важно! Если Вы не вошли в сервис и вам недоступна страница «Студентам», то проверьте вашу почту. Вам должно прийти письмо с регистрационными данными для входа в сервис
Форма загрузки студенческой работы на странице «Студентам»
Дополнительные поля для заполнения при загрузке по коду задания
Документ отправится в кабинет преподавателя, которому принадлежит задание. До тех пор, пока преподаватель не подтвердит вашу работу, в графе «Отчет» будет стоять символ «работа проверяется», в графе «Оценка» — статус «не подтверждена». После подтверждения преподавателя, вы увидите результаты проверки.
Строка с работой без подтверждения
Как поисковые системы реагируют на спам в текстах?
С появлением первых поисковых систем не было четко определенных алгоритмов семантического анализа, релевантность веб-страницы определялась в основном мета-тегами «keywords» и «description», что позволяло манипулировать SERP’ом (от Search Engines Result Page — результаты поисковой выдачи). Таким образом, количество не качественных сайтов, а также сайтов, которые использовали дублированный, украденный контент росло. В итоге, SERP захламлялся, а пользователь не получал точных результатов. Поисковики решили изменить эту ситуацию и ввели специальные фильтры, которые «зачищали» поисковую выдачу от спамных сайтов. Таким образом, в ТОП начали попадать только страницы, которые соответствуют поисковой оптимизации.
Какие же существуют фильтры поисковиков? Давайте остановимся на этом подробнее.
Текстовые фильтры Яндекса
- Фильтр «Переспам» — появился, по словам некоторых оптимизаторов, еще в 2010 году и коснулся текстов сайтов. Оптимизаторы дали ему свое имя — «Ты спамный». Фильтр задевал длинные, не релевантные, «водяные» тексты-портянки, которые не имели четкой структуры, насыщенные большим количеством ключевых слов — писались не для людей, а поисковых ботов. Сайты, который попадали под фильтр резко теряли позиции (на 10-30 ступенек).
- Фильтр «Новый» — является усовершенствованным алгоритмом «Переспама». Внимательный к сайтам с чрезмерно долгим и заспамленным Title, а также злоупотребление тегами выделения слова в тексте — <b>, <u>, <strong>, <em> и <i>, которые применяются некоторыми оптимизаторами для искусственного поднятия частоты ключевого слова на странице.
- Фильтр «Баден-Баден» — является фактически сборной версией всех предыдущих антиспам-фильтров Яндекса. Был запущен 22 марта 2017. Его особенность — искусственный интеллект, который способен распознавать человеческую речь. Его задача — полностью и окончательно избавиться от спамных сайтов и сделать SERP более информативным и релевантным.
Текстовые фильтры Google
- Фильтр «Панда» — по некоторым данным появился еще в 2011 году, а может и раньше. В отличие от «Пингвина», который наказывал за ссылочный спам, Панда проверяла их на дублированный и не оптимизированный контент. Сайты, которые копировали контент с других ресурсов, или публиковали бессмысленный, малоценный контент, насыщенный рекламой — подвергались жесткой фильтрации.
- Фильтр «Колибри» — его название происходит от скорости и точности птички колибри. Запущен 26 сентября 2013. «Колибри» стал вестником глубокого семантического анализа с применением искусственного интеллекта, который постепенно внедрялся в Google. «Колибри» точно понимает логику поискового запроса пользователя, естественную человеческую речь, учитывая контекст и значение отдельных слов, с акцентом на разговорный стиль. Колибри еще называют — «понимающим алгоритмом». Таким образом, веб-разработчикам и авторам было рекомендовано оптимизировать свои сайты, используя естественное сочетание слов, например LSI-ключевые слова.
Какие характеристики отражает сервис
В отчете приводятся следующие показатели:
- Уникальность.
- Процент цитирования. Отражает объем текста, взятого из официальных источников: Конституции РФ, Трудового, Семейного, Уголовного кодексов и т.д.
- Ссылки на самые похожие документы и процент совпадения с ними.
Поздние версии сервисов оценивают и стилистику текста, приводя дополнительные показатели.
Уровень заспамленности
Другое название показателя — тошнота.
Тошнота текста — это количество повторений ключевых слов.
Различают 2 ее вида:
- Классическую. Сервис подсчитывает, сколько раз каждая единица речи встречается в тексте. Из результата вычисляет квадратный корень.
- Академическую. Число повторений делится на количество всех слов в тексте и умножается на 100%. Этот показатель еще называют частотностью.
Классическая тошнота не учитывает объема текста, поэтому чаще используется академическая. Если она не превышает 3-5%, произведение считается соответствующим нормам русского языка (удобочитаемым).
Водность текста
Характеристика отражает процентное содержание слов, не несущих полезной информации.
Таковыми, например, являются:
- Местоименные наречия.
- Союзы и предлоги.
- Междометия.
- Частицы.
- Обращения.
- Вводные конструкции.
Водность текста — процент содержания в нем ничего не значащих слов.
Качественным считается текст с «водностью» 10-15% (норма — до 60%). Некоторые ресурсы определяют данный показатель как процентное соотношение единиц речи, не несущих смысловой нагрузки, к информативным, т.е. «обезвоженному» тексту.
Смешанные слова и измененные буквы
О замещении кириллических литер аналогичными по начертанию латинскими уже говорилось. Другой способ повышения уникальности состоит в перестановке букв. Он основан на том обстоятельстве, что читатель воспринимает выражение целиком, а не по литерам. Легко понять, что текст «По рзеузльаттам илссоевадний одонго анлигсйокго унвиертисета» значит «по результатам исследований одного английского университета». При этом скорость чтения не снижается.
Системы антиплагиата выявляют смешанные слова и отмечают их как неверно написанные. Их количество отображается в отчете отдельной строкой. Таким образом, несмотря на высокий показатель уникальности, скрыть факт манипуляций не удастся.
Как совершенствовался алгоритм проверки
Первая версия программы была простой и легко поддавалась обману. Например, буквы кириллицы «а», «в», «с», «х», «р» и другие замещали латинскими, имеющими тот же вид. Визуально текст не менялся, но для компьютера набор знаков становился уже другим, и он не был способен выявить плагиат.
Буквы кириллицы замещали латиницей.
Учитывая это, разработчики выпустили новую версию продукта, и данный способ перестал действовать. Программа распознавала замену букв и сообщала об этом в отчете. Но и ее можно было обмануть, меняя порядок слов там, где это не режет слух. Тогда принцип работы антиплагиата еще больше усложнили. Кроме описанной проверки по шагу шингла, он стал сравнивать весь текст, определять наиболее повторяемые отрывки и т.д. Подробных сведений об этом нет, поскольку алгоритм хранится в секрете.
Таким образом, между пользователями и разработчиками ПО ведется соревнование. Первые придумывают новые способы обмана программы, вторые реагируют на это выпуском новых, более сложных версий.
Как измерить «воду»
Обычно в техническом задании к статье указан сервис, по которому нужно проверять водность. Но если такой информации нет, это не значит, что можно лить сколько вздумается. Ответственный автор проверяет любой свой информационный текст по ключевым SEO-параметрам: уникальности, тошноте, водности, заспамленности (это не касается рекламных текстов, в них важны другие качества).
Эти онлайн-сервисы позволяют измерить количество воды в тексте бесплатно и без регистрации:
- Text.ru
- Advego
- Istio
- Главред.
В каждом из них свои списки стоп-слов, алгоритмы вычисления и как результат — различные критерии оценки текста. В таблице: нормы по воде на каждом из этих сервисов.
| Сервис | Водность | ||
| Нормальная | Повышенная | Высокая | |
| Text.ru | до 15% | до 30% | больше 30% |
| Advego | 55-75% | до 100% | |
| Istio | 30-60% | до 100% | |
| Главред | от 0 до 10 баллов в зависимости от количества лишних слов и стилистических ошибок |
Чаще всего заказчики запрашивают проверку водности по Text.ru и Advego. За годы работы с текстами я ни разу не встречала заказа с проверкой по сервису Istio. Но кто знает, возможно, именно вам повезет
Разберем подробнее каждый из этих сайтов на примере уже знакомого вам текста о нюансах выбора арендного жилья.
Text.ru
Поле для текста расположено сразу же на главной странице сайта. Просто вставляете и нажимаете кнопку Проверить на уникальность.
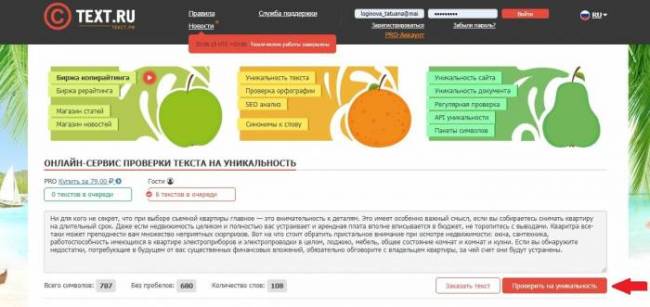
На странице результатов анализа, справа, будет собрана вся информация о тексте: уникальность, количество символов и слов, количество ошибок, процент заспамленности и воды. Показатели окрашиваются разными цветами: нормальные — зеленым, повышенные — желтым, высокие — красным.
Если кликнуть по вкладке SEO-анализ текста и под полем для текста выбрать пункт Вода (нужно включить глазик), то программа подсветит стоп-слова синим.

Водность — 21% (цвет желтый — повышенный уровень). Наглядный пример того, что формальные цифры водности не всегда адекватно отражают реальность: процент не зашкаливает, а смысл текста при этом сильно разбавлен.
В отредактированном варианте воды на 10% меньше (теперь цифры зеленые — водность в норме).

А если вам нужно предоставить результаты проверки кому-то еще (например, заказчику), то спуститесь чуть ниже поля с результатами, нажмите на кнопку Открыть доступ для всех, скопируйте ссылку из поля Ссылка на проверку и отправьте ее человеку.

Advego

Водность нашего исходника — на верхней границе нормального диапазона.

Список зафиксированных в тексте стоп-слов находится чуть ниже на странице результатов анализа — от них-то и нужно избавляться в первую очередь.
В отредактированном тексте воды меньше:

Проверить текст на водность можно только онлайн — программа-антиплагиат от Адвего (Advego Plagiatus) проверяет лишь на совпадение слов и фраз с другими текстами.
Istio
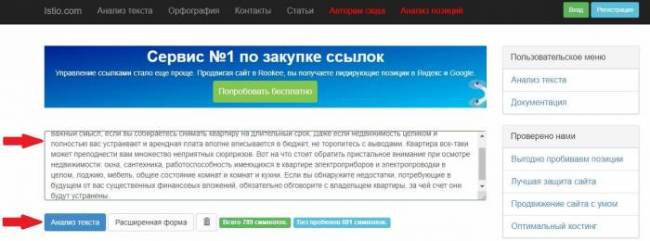
А вот так выглядит страница результатов проверки. Чтобы увидеть список зафиксированных в тексте стоп-слов, нужно кликнуть по вкладке Со стоп-словами.
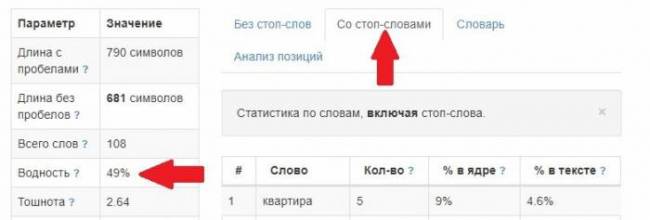
Результат после редактирования:
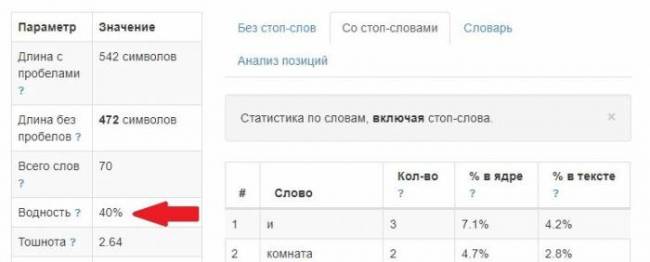
Алгоритм сервиса посчитал, что водность в первом варианте текста вполне себе в пределах нормы. Хотя объективно это не соответствует действительности. Может, поэтому Istio так непопулярен среди заказчиков?
Главред
Главред оценивает текст наоборот — чем он водянистее, тем меньший балл (от 1 до 10) выставит алгоритм.
Вам нужно просто вставить текст в поле и… всё. Нажимать ничего больше не нужно, программа тут же начинает проверку и через пару секунд выдает результат (внизу страницы):
- балл
- общее количество слов, знаков, предложений
- количество стоп-слов
- основные проблемы текста.
В самом тексте словесный мусор подсвечивается оттенками оранжевого. А если навести курсор на такое слово, то справа от поля ввода будет описана суть проблемы, пример ее решения и советы, что полезно будет автору прочесть конкретно об этой проблеме текста.
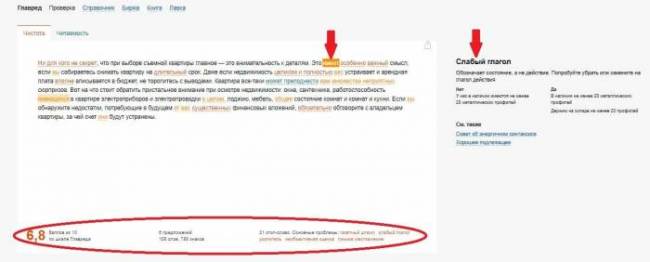
Текст получил 6,8 баллов, цифры оранжевые — текст так себе. А вот результат проверки отредактированного текста:
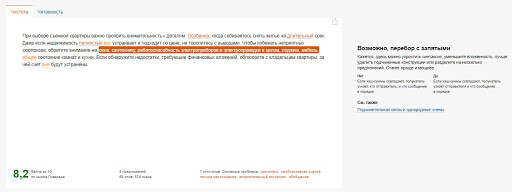
Теперь 8,2 балла, цифры зеленые — это хороший результат. Кстати, сам создатель Главреда Максим Ильяхов говорит о том, что не нужно стремиться вылизать текст до 10 баллов — результат, скорее всего, будет несъедобным. Оценки в 7-8 баллов вполне достаточно, чтобы получить полезный и интересный, но при этом человеческий текст.
Лучшие сервисы антиплагиата
Наибольшим доверием пользуются следующие сервисы.
«Etxt Антиплагиат»
С 2015 г. сервис изменил название на AntiPlagiarism.NET.
Etxt Антиплагиат — софт для проверки текста на уникальность.
Система представлена в 2 вариантах:
- Онлайн.
- Автономном. Требуется скачать программу и установить на компьютер. Для работы нужен высокоскоростной интернет. Продукт условно бесплатный: после нескольких сеансов придется заплатить $20.
Недостаток — прерывание работы каждые 30 секунд для набора изображенного на капче кода. Это требует постоянного присутствия пользователя на месте. Онлайн-версия капчи не выбрасывает.
В безвозмездном варианте действуют ограничения: в течение суток проверяется не более 3 000 знаков, для зарегистрированных пользователей — 5 000. В платной версии объем текста не ограничен, но не более 15 тыс. знаков за 1 раз. Стоимость — 1,5 руб. за 1 тыс.
Общий недостаток всех версий Etxt — низкая скорость работы. Текст в 40-45 страниц проверяется 25 минут.
Система не подходит студентам, поскольку ищет совпадения по всей сети. Уникальность работы, в т.ч. добросовестно написанной, окажется ниже установленной преподавателем.
«Киллер Антиплагиат»
Многофункциональный ресурс:
- Проверяет тексты на уникальность.
- Предоставляет доступ к «Антиплагиату ВУЗ».
- Поднимает процент оригинальности материала до заданного пользователем уровня.
Киллер Антиплагиат — специальный сервис, который используют для улучшения уникальности.
Система повышает уникальность путем внесения изменений в машинный код документа (макросы). Текст не редактируется, буквы на латинские не меняются. Стоимость услуги — 5 руб. за страницу.
Пользователь действует в следующем порядке:
- Переводит средства (есть 50 способов).
- Загружает текст.
- Устанавливает в настройках желаемую уникальность. Чтобы работа не вызывала подозрений, рекомендуется устанавливать показатель не более 95%.
- Вводит адрес своей электронной почты.
Аналогичные услуги предоставляет «Антиплагиат.НЕТ».
Antiplagiat.ru
Первый отечественный продукт, название которого стало нарицательным для всех аналогичных систем. Создавался для анализа студенческих работ, поэтому похожие тексты ищет только в банках курсовых, рефератов и т.п. По этой причине не подходит владельцам информационных сайтов.
Antiplagiat.ru — программа для проверки текста на уникальность.
Преимущества:
- Быстрая проверка (около минуты).
- Неограниченный объем текста.
- Удобный интерфейс.
- Объективная оценка уникальности курсовой или реферата, поскольку материал сравнивается только с работами студентов. Antiplagiat.ru покажет более высокий процент уникальности, чем, например, Etxt.
Предлагается 2 вида услуг:
- Платная. Ограничений нет.
- Безвозмездная. Работает только с текстами в формате PDF и TXT. Повторную проверку позволяет сделать только спустя 6 минут после предыдущей.
Для начала работы с Antiplagiat.ru пользователю необходимо пройти несложную регистрацию.
Современный сервис Advego
По характеристикам идентичен Etxt:
- Представлен в 2 версиях — онлайн и автономной.
- Ищет совпадения во всем интернете (не подходит студентам).
- Проверка занимает много времени.
- Автономная версия часто выбрасывает капчу.
- Бесплатный онлайн-сервис позволяет обработать не более 5 тыс. знаков в сутки.
Advego считают одной из лучших среди приложений для проверки уникальности.
В отличие от Etxt, автономная версия Advego является бесплатной.
«Антиплагиат ВУЗ» для студентов
Данный продукт представляет собой модификацию Antiplagiat.ru с расширенным набором функций. Он предназначен для преподавателей, студенты не имеют доступа к системе.
Антиплагиат ВУЗ — самая популярная система проверки в вузах.
Главные отличия от базовой версии:
- Используется более широкий перечень банков готовых рефератов и курсовых.
- Формируется сертификат о прохождении проверки программой «Антиплагиат ВУЗ». Его прикладывают к работе.
Для пользования программой высшее учебное заведение заключает договор с разработчиком. Стоимость лицензии сроком на год составляет 300-350 тыс. руб.
Неработающие способы уникализации текста в 2020 году
Некоторые методы уже не работают из-за фикса багов разработчиками. Попытки повысить уникальность текста такими способами — лишняя трата времени, не дающая необходимого эффекта.
Замена русских букв на английские
Вариант не используется уже несколько лет. В отличие от греческого алфавита, сервисы проверки уникальности научились определять подмену кириллицы на латиницу. Фраза будет подсвечена как неуникальная независимо от используемой раскладки.
Сервисы проверки уникальности умеют определять подмену кириллицы.
Отбеливание текста
Между словами или как часть фраз вставляются символы, набранные шрифтом белого цвета. Встречается вставка больших фрагментов случайных символов между абзацами.
Метод неэффективен, т. к. случайные символы системы проверки на плагиат научились игнорировать. Шрифт белого цвета становится виден при выделении текста, поэтому при пристальном изучении легко определить некачественную работу.
Подмена основных словосочетаний синонимами
Способ неудачен, поскольку часто используется копирайтерами при написании статей для веб-сайтов. Все возможные словосочетания и замены синонимами давно использованы и проиндексированы поисковиками. Единственный действенный метод — подобрать оригинальный синоним, который ранее никто не публиковал.
Вставка микротекста
Как и в случае с буквами белого цвета, символы, набранные мелким шрифтом, можно обнаружить при детальном анализе работы. Самый простой способ — выделить весь текст, чтобы он изменил цвет.
Вставку микротекста можно обнаружить только при детальном анализе работы.
Замена знаков препинания
Знаки препинания больше не учитываются поисковиками и системами проверки на плагиат. Имеют значение только слова, несущие смысловую нагрузку. По этой же причине неэффективна вставка точек или запятых белого цвета вместо пробелов.
Перестановка слов и предложений
Если менять местами слова во фразе или предложения внутри абзаца, уникальность не повысится, а уловить смысловой посыл фразы читателю может оказаться сложно. Такой способ раньше работал, но алгоритмы проверки уникальности с тех пор изменились.
Разбивка предложений
Ни разбивка длинных предложений на несколько небольшого размера, ни объединение их в одно не повышают уникальности текста. Слова остаются те же, за исключением добавленных частиц или союзов.
Принцип работы антиплагиата
После загрузки текста сервис действует следующим образом:
- Формирует фрагмент из нескольких первых слов. Их количество называют шагом шингла. Оно задается в настройках.
- Направляет эту строку в поисковые ресурсы в виде запроса.
- Получает в ответ ссылки на сайты и отмечает те из них, где данный текст полностью повторяется.
- Формирует новый фрагмент, смещаясь на 1 единицу речи. Далее пп. 2 и 3 повторяются.
Например, проверяется работа, начинающаяся словами: «Технология дробления горных пород включает в себя…». Пусть шаг шингла в настройках равен 3. Тогда первый запрос будет иметь вид: «технология дробления горных». Следующей в поисковик отправится фрагмент «дробления горных пород» и т.д.
Метод шинглов.
Если число сайтов, где строчка точно повторяется, превысит заданный в настройках предел (пользователь не может его изменить), она признается неуникальной и выделяется цветом. Ресурс с наибольшим числом совпадений будет указан как возможный источник, откуда были скопированы подсвеченные отрывки.
Таким образом, возможны следующие ситуации:
- Статья или курсовая написана своими словами, но из-за большого количества штампов, клише, общепринятых фразеологических оборотов получает низкую уникальность. Этому особенно подвержены тексты на популярные узкоспециализированные темы, например юридические или медицинские. Приводимые в них профессиональные понятия сложно выразить по-другому так, чтобы работа не резала слух.
- Сдавая работу, студент получил высокую уникальность, но проверка преподавателем спустя несколько дней показала низкий процент. Причина в том, что за это время в сети были опубликованы материалы с похожими фрагментами.
- Показатели уникальности одного текста в разных программах антиплагиата отличаются. Это зависит от особенностей алгоритма и настроек, например, шага шингла. Из-за несовершенства технологии или сбоя в работе поисковой системы одна программа может выдать 100%, а через 5 минут для того же текста — 75%.
Уникальность зависит также от того, какой задан шаг шингла. С его уменьшением число совпадений увеличивается, и процент оригинальности статьи падает. При шаге 3 любой добросовестно написанный текст окажется наполовину подсвеченным.