Исправляем проблемы с отображением русских букв в windows 10
Содержание:
- Как найти и устранить неполадки
- Что делать, чтобы сменить кодировку в Блокноте по умолчанию с ANSI на другую:
- Суть проблемы
- Как исправить иероглифы Windows 10 путем изменения кодовых страниц
- Как исправить кракозябры и иероглифы в Windows 10
- Что такое кодировка текста и с чем ее едят?
- Помощь Windows
- Решаем проблемы с кодировкой или как убрать кракозябры?
- Редактирование реестра
- Инструкция по изменению кодировки в стандартном блокноте
- Использование реестра, если метод выше не помог
- Редактирование реестра
- На других языках и скриптах
- Текстовые документы
Как найти и устранить неполадки
Решения, которые описаны далее, очень просты, поскольку не потребуют серьезных действий, но причин существует довольно много. Причем можно обойтись без похода в ремонтную мастерскую.
Перезагрузка
Если устройство начало распечатывать иероглифы, то перезагрузку необходимо выполнить в первую очередь. Отключаем ПК и принтер, а после включаем через небольшой промежуток времени.
Вероятно, это незначительная поломка, которую можно решить с помощью этого простого способа. Если это не помогло, то нужно рассмотреть другие возможные варианты.
Использование другого программного обеспечения
Чаще всего непонятный текст вместо русских символов появляется при распечатке с помощью MS Word. Можно попытаться распечатать документ другим программным обеспечением.
Нужно пересохранить текст и открыть программой AdobeReader либо Foxit Reader. Произвести печать также можно в браузере, к примеру, Internet Explorer либо Chrome.
Распечатка изображения
Можно попробовать вместо текстового документа распечатать рисунок. Для чего необходимо:
- Запустить программу, использующуюся для отправки документа на устройство.
- Отыскать меню «Дополнительно».
- Нажать «Распечатать как рисунок», установить галочку.
Теперь устройство напечатает текстовый документ как рисунок. Иероглифы вместо русских букв, вероятней всего, видно не будет.
Изменение шрифта
Причина иногда состоит в шрифте. Устройство его не распознает, а распечатывает иероглифы вместо букв. Можно попробовать просто установить другой шрифт. Тем более это часто помогает, если используется не стандартный шрифт (к примеру, Times New Roman), а другой.
Также можно попробовать такой вариант: запретите подставку CourierNew:
- На панели управления отыщите меню с оборудованием.
- Выберите неработающий принтер.
- Нажмите кнопку «Свойства принтера», зайдите в меню «Параметры принтера».
- Отыщите подстановку шрифта и нажмите «Не подставлять».
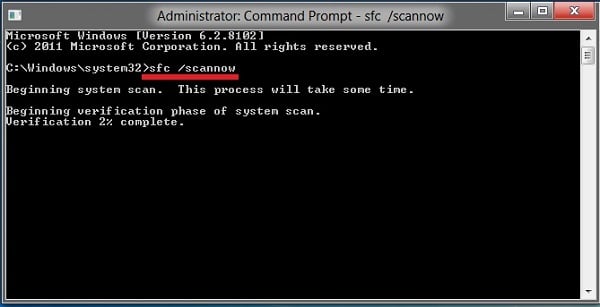
Системные файлы
Иногда причина находится в системных файлах. После их восстановления это сможет помочь исправить проблему:
- Для начала необходимо открыть от имени администратора командную панель. Ввести в ней «sfc/scannow» и нажать «Ок».
- Подождите определенное время. После проверьте, была ли решена проблема.
Установка драйверов
Не редко эта неисправность возникает из-за драйверов. Устройство выдает иероглифы, так как драйверы неправильно установлены либо выдают сбой. Потому можно попытаться их установить заново. Для чего:
- В «Панели управления» нужно зайти в меню «Оборудование и звук» и отыскать неисправный принтер.
- После нажать ПКМ, выбрать «Удалить устройство».
- В «Программах и компонентах» необходимо удалить все программы, которые относятся к работе устройства.
- Затем отыскать диск, который должен идти в комплекте с оборудованием. С него заново установить требуемые программы.
Вредоносное ПО
Надо проверить ПК с помощью антивируса. Проблема может скрываться в этом.
Это главные причины, почему принтер печатает иероглифы, и способы их решения. Обычно этих простых действий вполне достаточно, так как эта неисправность может то появляться, то самостоятельно пропадать.
Что делать, чтобы сменить кодировку в Блокноте по умолчанию с ANSI на другую:
- Открываем Блокнот или создаём новый текстовый документ и потом его открываем в Блокноте
- Меняем кодировку текстового файла
- Сохраняем этот документ (я свой назвал по названию кодировки UTF-8.txt)
- Если не видно расширение файла, то можно его сделать видимым
- Можно сохранить файл и переименовать
- Перемещаем созданный документ в папкуC:WindowsShellNew (сразу создать текстовый документ в этой папке не получится — защита Windows от внесения изменений в системные папки)
- Если папки нет (что мало вероятно), то её нужно создать и также переместить на место: C:WindowsShellNew
- Теперь открываем редактор реестра
- Находим папку HKEY_CLASSES_ROOT / .txt / ShellNew / (она должна быть, если нет, то создаём)
- Создаём строковый параметр :
- С именемFileName
- Со значениемUTF-8.txt (имя того файла, который мы создали в п.3 перенесли в папку C:WindowsShellNew в п.4)
- Радуемся! Ибо это всё =)
Теперь при создании текстового файла с помощью контекстного меню у него будет та кодировка, которая была нами установлена в файле-образце, лежащем в папке C:WindowsShellNew.
Суть проблемы
Как правило, мы можем наблюдать эти кракозябры не в каждой программе. Например, символы, изображённые кириллицей в названии программ, отображены корректно. Но если запустить программу установки дистрибутивов, поддерживающих русский язык, мы получаем неведомую нам «китайскую грамоту».
И, пожалуй, основная проблема кроется в том, что в имеющейся ОС по дефолту отсутствует поддержка кириллических символов. На практике это может значить, что вы инсталлировали английский дистрибутив с установленным поверх него расширенным пакетом русификации. Однако последний не смог решить проблему корректно.
Первое, что пытаются делать пользователи в такой ситуации – переустановка операционки с чистого листа. Однако не все согласятся на такое, ведь кто-то, возможно, намеренно хочет работать с англоязычной средой. И в этой среде кириллические символы по идее могут и должны отображаться корректно.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
- Нажмите клавиши Win+R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра.
- Перейдите к разделу реестраи в правой части пролистайте значения этого раздела до конца.
- Дважды нажмите по параметру ACP, установите значение 1251 (кодовая страница для кириллицы), нажмите Ок и закройте редактор реестра.
- Перезагрузите компьютер (именно перезагрузка, а не завершение работы и включение, в Windows 10 это может иметь значение).
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
- Зайдите в папку C:\ Windows\ System32 и найдите файл c_1252.NLS, нажмите по нему правой кнопкой мыши, выберите пункт «Свойства» и откройте вкладку «Безопасность». На ней нажмите кнопку «Дополнительно».
- В поле «Владелец» нажмите «Изменить».
- В поле «Введите имена выбираемых объектов» укажите ваше имя пользователя (с правами администратора). Если в Windows 10 используется учетная запись Майкрософт, вместо имени пользователя укажите адрес электронной почты. Нажмите «Ок» в окне, где указывали пользователя и в следующем (Дополнительные параметры безопасности) окне.
- Вы снова окажетесь на вкладке «Безопасность» в свойствах файла. Нажмите кнопку «Изменить».
- Выберите пункт «Администраторы» (Administrators) и включите полный доступ для них. Нажмите «Ок» и подтвердите изменение разрешений. Нажмите «Ок» в окне свойств файла.
- Переименуйте файл c_1252.NLS (например, измените расширение на .bak, чтобы не потерять этот файл).
- Удерживая клавишу Ctrl, перетащите находящийся там же в C:\Windows\System32 файл c_1251.NLS (кодовая страница для кириллицы) в другое место этого же окна проводника, чтобы создать копию файла.
- Переименуйте копию файла c_1251.NLS в c_1252.NLS.
- Перезагрузите компьютер.
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
А вдруг и это будет интересно:
Дмитрий, спасибо за полезную статью! Объясните, пожалуйста, зачем вы вставляете пробелы в путях реестра? Это же жутко неудобно, когда хочешь скопировать путь и вставить в окно редактора реестра. К примеру, в статье указана ветка реестра HKEY_LOCAL_MACHINE\ SYSTEM\ CurrentControlSet\Control\ Nls\ CodePage, чтобы вставить и перейти по этому пути, надо предварительно удалить 3 пробела, иначе редактор реестра не опознает его.
Здравствуйте. Сейчас уже не вставляю. Раньше была проблема: при вставке путей без пробелов границы сайта начинали за границы экрана выходить (особенно на телефоне). Сейчас поправил, но в статьях не везде отследил, как замечаю — исправляю. Вот сейчас и здесь поправлю.
Спасибо и с праздником вас!
После изменения языка системы с английской US на русскую крякозябры в текстовых документах исчезли, но проблема частично сохранилась. До изменения языка системы интерфейс и настройки программы USDownloader были полностью в крякозябрах, после изменения стало получше, но проблема полностью еще не решена. Подскажите, что еще можно сделать для решения моей проблемы?
Подозреваю, что автор программы в тех элементах шрифт какой-то использует, который у вас тоже есть, но без наличия кириллических символов. Можно попробовать вообще с разработчиком списаться на тему (вроде там частное лицо, должно идти на контакт).
Статья топчик! Русский язык заработал на Win10 Eng!
источник
Как исправить кракозябры и иероглифы в Windows 10
- Нажмите Win + R и введите control. Система откроет классическую Панель управления.
- На главной странице перейдите в группу Часы, язык и регион – Изменение форматов даты, времени и чисел.
- На открывшемся окне Регион откройте вкладку Дополнительно.
- Нажмите кнопку Изменить язык системы в секции окна Язык программ, не поддерживающих Юникод.
- В открывшемся окошке выберите из выпадающего списка необходимый вам язык, к примеру, Русский (Россия). Нажмите Ок.
- Windows предупредит вас, что необходимо перезагрузить компьютер, чтобы изменения вступили в силу. Согласитесь на перезагрузку сейчас и нажмите Перезагрузить сейчас.
После запуска компьютера текст должен отображаться как положено.
Что такое кодировка текста и с чем ее едят?
Начать хотелось бы с того, что этой статьи могло бы и не быть, т.к. компьютерно-юзательная жизнь автора этих строк протекала вполне себе спокойно и достойно. Но вот в один прекрасный день, шляясь по просторам сети Интернет не со своего ПК, я столкнулся с непонятными явлениями на некоторых сайтах. Заходя на интернет-ресурсы, я видел не привычный нам русский алфавит и красивый понятный текст, а какую-то ересь в виде непонятной последовательности символов. Выглядела она примерно вот так (см. изображение).

Сначала я подумал, что моя любимая Мозилка (браузер Firefox) перегрелась и ей пора вызывать неотложку, но потом начал понимать, что проблема, скорее всего, на стороне ресурса сети и кроется она в неправильно настроенной кодировке. Это действительно оказалось так, и пошаманив немного с бубном, проблемка была оперативно решена. Результатом же всех моих любовных похождений и стал сегодняшний материал. Собственно, поехали разбираться в деталях.
Всю информацию, представленную в цифровом виде и находящуюся в глобальной паутине, нужно рассматривать с двух сторон: первая — со стороны пользователя (красивый и ухоженный текст на экране монитора) и вторая – со стороны поисковой машины (некий программный код, состоящий из различных тегов/метатегов, таблицы символов и прочее).
Если Вы хоть немного знакомы с языком разметки гипертекста (HTML), то должны быть в курсе, что сайт глазами поисковых машин (Google, Яндекс) видится не как обычный текст, а как структурированный документ, состоящий из последовательностей различного рода тегов. Чтобы было понятней, о чем я говорю, давайте взглянем на всеми нами любимый сайт Заметки Сис.Админа” проекта , но не глазами обычного пользователя, а «глазами» поисковика. Для этого нажимаем сочетание клавиш Сtrl+U (для браузеров Firefox и Chrome) и видим следующую картину (см. изображение):
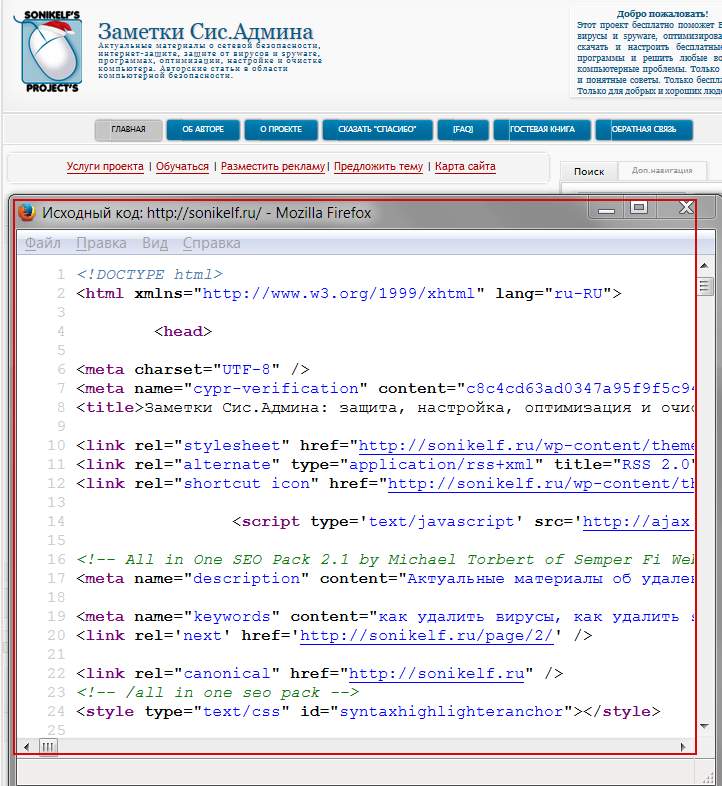
Перед нами машинный вариант sonikelf.ru, вот в таком вот непрезентабельном виде он подается поисковым системам и именно в таком виде они его и кушают. Если бы мы просто взяли и “засандалили” варианты статей из блокнота или Word обычным текстом, машины бы им не то что подавились, они бы даже и есть его не стали. Итак, перед нами главная страница проекта в HTML-виде
Обратите внимание на строку с надписью UTF-8, это не что иное, как пресловутая кодировка текста страницы, именно она и отвечает за формат вывода информации в презентабельном виде, в результате чего через браузер мы видим нормальный текст
Теперь давайте разберемся, почему же происходит так, что порой на экране монитора мы видим кракозябры. Все очень просто, проблема кроется в открытии файла в неверной кодировке. Если перевести на бытовой язык, то допустим Вас послали в магазин за молоком, а Вы притарабанили хлеб, вроде бы тоже съестное, но совсем другой формат продукта.
Итак, теперь давайте разбираться с теорией и для этого введем некоторые определения.
- Кодировка (или “Charset”) – соответствие набора символов набору числовых значений. Нужна для “сливания” информации в интернет, т.е. текстовая информация преобразуется в биты данных;
- Кодовая страница (“Codepage”) – 1 байтовая (8 бит) кодировка;
- Количество значений, принимаемое 1 байтом – 256 (два в восьмой).
Соответствие “символ-изображение” задается с помощью специальных кодовых таблиц, где каждому символу уже присвоен свой конкретный числовой код. Таких таблиц существует достаточно много, и в разных таблицах один и тот же символ может идентифицироваться по-разному (ему могут соответствовать разные числовые коды).
Все кодировки различаются количеством байт и набором специальных знаков, в которые преобразуется каждый символ исходного текста.
Примечание:Декодирование – операция, в результате которой происходит преобразование кода символа в изображение. В результате этой операции информация выводится на экран монитора пользователя.
В общем.. С определениями разобрались, а теперь давайте узнаем, какие же (кодировки) бывают.
Помощь Windows
Вопросительный знак — распространенный символ пунктуации. И его можно вставить в текст по-разному.
Третий способ решения поставленной задачи — это использование таблицы символов Windows. Он не так часто используется в реальной жизни, но имеет место.
Алгоритм действий будет приблизительно таким:
- Зайти в «Таблицу символов». Ее можно найти в «Пуске», в разделе «Стандартные», подпункте «Служебные».
- Отыскать в появившемся меню символ со знаком вопроса.
- Кликнуть по нему несколько раз левой кнопкой мышки.
- Нажать на кнопку «Копировать» в нижней части службы.
- Открыть текст, в котором необходимо поставить знак вопроса.
- Нажать Ctrl + V или ПКМ + команда «Вставить».
Как показывает практика, такой расклад чаще всего встречается при печати более необычных символов. Знаки препинания набираются намного проще посредством клавиатурной панели или специализированных кодов.
Решаем проблемы с кодировкой или как убрать кракозябры?
Итак, наша статья была бы неполной, если бы мы не затронули пользовательско-бытовые вопросы. Давайте их и рассмотрим и начнем с того, как (с помощью чего) можно посмотреть кодировку?
В любой операционной системе имеется таблица символов, ее не нужно докачивать, устанавливать – это данность свыше, которая располагается по адресу: “Пуск-программы-стандартные-служебные-таблица символов”. Это таблица векторных форм всех установленных в Вашей операционной системе шрифтов.
Выбрав “дополнительные параметры” (набор Unicode) и соответствующий тип начертания шрифта, Вы увидите полный набор символов, в него входящих. Кликнув по любому символу, Вы увидите его код в формате UTF-16, состоящий из 4-х шестнадцатеричных цифр (см. изображение).
Теперь пара слов о том, как убрать кракозябры. Они могут возникать в двух случаях:
- Со стороны пользователя — при чтении информации в интернет (например, при заходе на сайт);
- Или, как говорилось чуть выше, со стороны веб-мастера (например, при создании/редактировании текстовых файлов с поддержкой синтаксиса языков программирования в программе Notepad++ или из-за указания неправильной кодировки в коде сайта).
Рассмотрим оба варианта.
№1. Иероглифы со стороны пользователя.Допустим, Вы запустили ОС и в каком-то из приложений у Вас отображаются пресловутые каракули. Чтобы это исправить, идем по адресу: “Пуск — Панель управления — Язык и региональные стандарты — Изменение языка” и выбираем из списка, «Россия».

Также проверьте во всех вкладках, чтобы локализация была “Россия/русский” – это так называемая системная локаль.
Если Вы открыли сайт и вдруг поняли, что почитать информацию Вам не дают иероглифы, тогда стоит поменять кодировку средствами браузера (“Вид — Кодировка”). На какую? Тут все зависит от вида этих кракозябр. Ориентируйтесь на следующую шпаргалку (см. изображение).

№2. Иероглифы со стороны веб-мастера.Очень часто начинающие разработчики сайтов не придают большого значения кодировке создаваемого документа, в результате чего потом и сталкиваются с вышеозначенной проблемой. Вот несколько простых базовых советов для веб-мастеров, чтобы исправить беду.
Чтобы такого не происходило, заходим в редактор Notepad++ и выбираем в меню пункт “Кодировки”. Именно он поможет преобразовать имеющийся документ. Спрашивается, какой? Чаще всего (если сайт на WordPress или Joomla), то “Преобразовать в UTF-8 без BOM” (см. изображение).
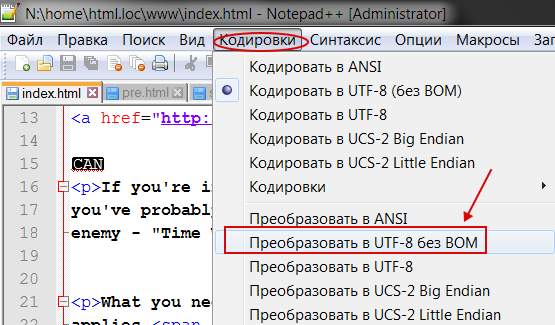
Сделав такое преобразование, Вы увидите изменения в строке статуса программы.

Также во избежание кракозябр необходимо принудительно прописать информацию о кодировке в шапке сайта. Тем самым Вы укажите браузеру на то, что сайт стоит считывать именно в прописанной кодировке. Начинающему веб-мастеру необходимо понимать, что чехарда с кодировкой чаще всего возникает из-за несоответствия настроек сервера настройкам сайта, т.е. на сервере в базе данных прописана одна кодировка, а сайт отдает страницы в браузер в совершенной другой.
Для этого необходимо прописать “внаглую” (в шапку сайта, т.е, как частенько, в файл header.php) между тегами <head> </head> следующую строчку:
<meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″>
Прописав такую строчку, Вы заставите браузер правильно интерпретировать кодировку, и иероглифы пропадут.
Также может потребоваться корректировка вывода данных из БД (MySQL). Делается сие так:
mysql_query(‘SET NAMES utf8’ );
myqsl_query(‘SET CHARACTER SET utf8’ );
mysql_query(‘SET COLLATION_CONNECTION=»utf8_general_ci'» ‘);
Как вариант, можно еще сделать ход конём и прописать в файл .htaccess такие вот строчки:
# BEGIN UTF8
AddDefaultCharset utf-8
AddCharset utf-8 *
<IfModule mod_charset.c>
CharsetSourceEnc utf-8
CharsetDefault utf-8
</IfModule>
# END UTF8
Все вышеприведенные методы (или некоторые из них), скорее всего, помогут Вам и Вашим будущим посетителям избавиться от ненавистных иероглифов и проблем с кодировкой. К сожалению, более подробно мы здесь инструкцию по веб-мастерским штукам рассматривать не будем, думаю, что они обязательно разберутся в подробностях при желании (как-никак у нас несколько другая тематика сайта).
Ну, вот и практическая часть статьи закончена, осталось подвести небольшие итоги.
Редактирование реестра
Откройте любой бесплатный текстовый редактор. Подойдет даже Блокнот, а вот Word – не самый удачный выбор, так как этот редактор зачастую меняет структуру кода, и в результате ниже описанный метод либо вовсе не будет работать, либо сработает но не так.
Далее в текстовом редакторе создайте пустой файл, которому выдадите разрешение .reg. Это разрешение соответствует разрешению реестра Windows 10. Сам файл далее дополним следующей информацией:
Windows Registry Editor Version 5.00
«ARIAL»=dword:00000000
«Arial,0″=»Arial,204»
«Comic Sans MS,0″=»Comic Sans MS,204»
«Courier,0″=»Courier New,204»
«Courier,204″=»Courier New,204»
«MS Sans Serif,0″=»MS Sans Serif,204»
«Tahoma,0″=»Tahoma,204»
«Times New Roman,0″=»Times New Roman,204»
«Verdana,0″=»Verdana,204»
Сохраняемся
У файла может быть любое имя, важно, чтобы у него было указанное выше разрешение. Далее, после того как внутри файла оказалась приведенная выше информация, вам нужно внести изменения в реестр
Для этого используйте простую методику – кликните по файлу таким образом, как будто хотите его открыть. Но не в текстовом редакторе, а именно запустить. Для этого потребуется отменить «Программу по умолчанию» в виде редактора, если вы выбрали редактор.
ОС уточнит у вас, если вы хотите внести изменения в реестр своего компьютера. Соглашайтесь. Конечно, тем, кто переживает больше обычного, можем порекомендовать сделать резервную копию реестра. Для этого опять же не потребуется никаких специальных знаний. Можете использовать CCleaner, чтобы создать копию или резервный файл.
Надеемся, теперь кракозябры и иероглифы на Windows 10 вместо букв если и не перестанут появляться, то вы теперь хотя бы знаете, как с ними бороться. Учтите, что в некоторых случаях виноват все же разработчик утилиты, и даже если вы проделаете все, что описано выше, то все равно не придете к нужному результату. В этом случае, вам лучше скачать другой дистрибутив, возможно не на русском, а на английском. Также можете попробовать запуститься в безопасном режиме, и проверить если там ПО работает как надо. Если да, то тогда у вас есть все шансы исправить ситуацию и в нормальном обычном режиме.
Пожалуйста, Оцените:
Наши РЕКОМЕНДАЦИИ
 Tiworker exe Windows modules installer worker
Tiworker exe Windows modules installer worker  Процесс бездействие системы грузит процессор
Процесс бездействие системы грузит процессор  Что делать с ошибкой сценария на странице
Что делать с ошибкой сценария на странице  Как перевернуть видео на компьютере
Как перевернуть видео на компьютере
Инструкция по изменению кодировки в стандартном блокноте
Его обычно можно найти по следующему пути: «пуск», «все программы», «стандартные». Нашли? Давайте откроем. Если требуется произвести работы с уже существующем документом, то нажимаем «файл», «открыть» и выбираем его.
После написания текста или открытия готового документа в меню «файл» нажимаем «сохранить как».
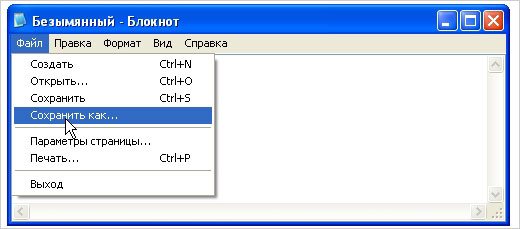
После этого на экране появляется окно, в котором можно выбрать подходящий вариант из представленного списка.
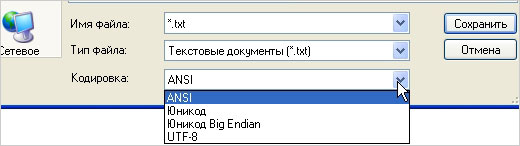
Выбираем подходящий вариант, место сохранения документа и подтверждаем операцию. Вот и всё. Было просто? На самом деле для выполнения нужных работ могут потребоваться лишь считанные секунды.
Использование реестра, если метод выше не помог
Создадим в текстовом редакторе обычный файлик, но дадим ему расширение .reg, дабы впоследствии можно было применить все настройки, хранящиеся в нем. Итак, какое же содержимое reg-файла должно быть?
Как узнать, какая видеокарта стоит на компьютере Windows
Наберем в него ручками или скопируем через буфер обмена следующие значения:
Когда все указанные строки окажутся в reg-файле, запустим его, согласимся с внесением изменений в систему, после чего выполним перезагрузку ПК и смотрим на результаты. Кракозябры должны исчезнуть.
Важное замечание: перед внесением изменений в реестр лучше создать резервную копию (другими словами, бэкап) реестра, дабы вносимые впоследствии изменения не повлекли за собой крах операционки, и ее не пришлось переустанавливать с нуля. Тем не менее, если вы уверены, что эти действия безопасны для вашей ОС, можете этот пункт упустить
Редактирование реестра
Откройте любой бесплатный текстовый редактор. Подойдет даже Блокнот, а вот Word – не самый удачный выбор, так как этот редактор зачастую меняет структуру кода, и в результате ниже описанный метод либо вовсе не будет работать, либо сработает но не так.
Далее в текстовом редакторе создайте пустой файл, которому выдадите разрешение .reg. Это разрешение соответствует разрешению реестра Windows 10. Сам файл далее дополним следующей информацией:
Windows Registry Editor Version 5.00
«ARIAL»=dword:00000000
«Arial,0″=»Arial,204»
«Comic Sans MS,0″=»Comic Sans MS,204»
«Courier,0″=»Courier New,204»
«Courier,204″=»Courier New,204»
«MS Sans Serif,0″=»MS Sans Serif,204»
«Tahoma,0″=»Tahoma,204»
«Times New Roman,0″=»Times New Roman,204»
«Verdana,0″=»Verdana,204»
Сохраняемся
У файла может быть любое имя, важно, чтобы у него было указанное выше разрешение. Далее, после того как внутри файла оказалась приведенная выше информация, вам нужно внести изменения в реестр
Для этого используйте простую методику – кликните по файлу таким образом, как будто хотите его открыть. Но не в текстовом редакторе, а именно запустить. Для этого потребуется отменить «Программу по умолчанию» в виде редактора, если вы выбрали редактор.
ОС уточнит у вас, если вы хотите внести изменения в реестр своего компьютера. Соглашайтесь. Конечно, тем, кто переживает больше обычного, можем порекомендовать сделать резервную копию реестра. Для этого опять же не потребуется никаких специальных знаний. Можете использовать CCleaner, чтобы создать копию или резервный файл.
Надеемся, теперь кракозябры и иероглифы на Windows 10 вместо букв если и не перестанут появляться, то вы теперь хотя бы знаете, как с ними бороться. Учтите, что в некоторых случаях виноват все же разработчик утилиты, и даже если вы проделаете все, что описано выше, то все равно не придете к нужному результату. В этом случае, вам лучше скачать другой дистрибутив, возможно не на русском, а на английском. Также можете попробовать запуститься в безопасном режиме, и проверить если там ПО работает как надо. Если да, то тогда у вас есть все шансы исправить ситуацию и в нормальном обычном режиме.
Пожалуйста, Оцените:
НашиРЕКОМЕНДАЦИИ
COM Surrogate что это Сбой запроса дескриптора USB устройства Не могу удалить файл с компьютера Преобразование GPT диска в MBR без потери данных
В процессе работы в Windows 10 может возникнуть ситуация, когда русские символы в системе перестают корректно отображаться. Вместо них мы видим нечто невразумительное, некие иероглифы или кракозябры, не обладающие каким-либо практическим смыслом. Обычно такое случается, когда неправильно выбрана локаль в региональных настройках.
Частенько это имеет место быть, когда вы работаете с русскоязычными символами в операционке с английской локализацией, поскольку в ней для русскоязычной программы по умолчанию отсутствуют средства обработки кириллицы, да и какого-либо другого языка с нелатинскими символами, будь это греческая, китайская либо японская языковая конструкция. В этой статье я расскажу, как убрать кракозябры в Windows 10, и вместо них работать с корректно отображающимися русскими символами.
Обычно кракозябры отображаются не везде. К примеру, кириллические символы в названиях программ на рабочем столе написаны абсолютно правильно, без ошибок, а вот если запустить на инсталляцию один из дистрибутивов с поддержкой русского языка, то тут же все начинает идти вкривь и вкось, текст становится нечитаемым, и вы буквально не знаете, что делать.
Ниже я расскажу, как избавиться от этой проблемы, решив ее в свою пользу раз и навсегда.
Как выбрать лучшую материнскую плату для AMD Ryzen и на каком чипсете?
Стоит понимать, что вся проблема в том, что в вашей операционной системе изначально отсутствует поддержка кириллицы. Скорее всего, вы установили дистрибутив на английском языке, и поверх него установили расширенный пакет для русификации системы, но это не решает всех проблем. Текст все равно является нечитаемым, а описанная проблема остается и никуда не исчезает.
Первое, что может прийти в голову в данной ситуации — это переставить ОС с нуля на русскую версию, где изначально уже присутствует поддержка кириллических символов. Но предположим, что этот вариант для вас не годится, поскольку вы хотите работать именно в англоязычной среде, где все символы кириллицы отображаются корректно и без багов. Именно о такой ситуации и пойдет речь в моей инструкции, которая в этом случае и придется вам как никогда кстати.
Программы для очистки компьютера от мусора
На других языках и скриптах
Открывающие и закрывающие вопросительные знаки на испанском языке
Открывающие и закрывающие вопросительные знаки
В испанском языке , так как во втором издании Ortografia
наReal Academia Española в 1754, вопросительные требуют как открытие ¿ и закрытие ? вопросительные знаки. Вопросительное предложение, предложение или фраза начинается с перевернутого вопросительного знака ¿ и заканчивается вопросительным знаком ? , как в:
Почему греется айфон: причины и способы устранения
Ella me pregunta «¿qué hora es?» — Она меня спрашивает„Сколько времени? “ «
Вопросительные знаки всегда должны совпадать, но для обозначения неуверенности, а не фактического допроса, опускание вводного допустимо, хотя и не рекомендуется:Чингисхан (¿1162? –1227) предпочтительнее в испанском языке, чемЧингисхан (1162? –1227). Отсутствие начального знака — обычное дело в неформальной письменной форме, но считается ошибкой. Единственное исключение — это когда вопросительный знак сочетается с восклицательным знаком, например:¡Quién te имеет creído que eres? — ‘Кто ты, по-твоему, такой?!’
(Порядок также может быть изменен на обратный: начало с вопросительного знака и завершение с восклицательным знаком.) Тем не менее, даже здесь Academia
рекомендует совпадение знаков препинания:¡¿Quién te имеет creído que eres ?! Открытие знак вопроса в Unicode является U + 00BF ¿ ПЕРЕВЕРНУТОГО знак вопроса (HTML ·
).
На других языках Испании
Галисийский также использует перевернутый начальный вопросительный знак, хотя обычно только в длинных предложениях или в случаях, которые в противном случае были бы неоднозначными. Басков использует только последний вопросительный знак.
Армянский вопросительный знак
| Вопросительный знак на армянском |
В армянском языке вопросительный знак — это диакритический знак, который принимает форму открытого круга и ставится над последней гласной вопросительного слова. Он определен в Unicode в U + 055E ◌՞ АРМЯНСКИЙ ВОПРОСИТЕЛЬНЫЙ ЗНАК .
Греческий вопросительный знак
Греческий знак вопроса (греческий: ερωτηματικό , латинизируется: erōtīmatikó
) выглядит как ; . Он появился примерно в то же время, что и латинский, в 8 веке. Он был принят церковнославянским языком и в конечном итоге остановился на форме, по существу похожей на латинскую точку с запятой . В Unicode , она отдельно кодируются как U + 037E ; ГРЕЧЕСКИЙ знак вопроса , но сходство настолько велико , что точка коды является нормализована к U + 003B ; SEMICOLON , делая марки идентичными на практике. В греческом языке вопросительный знак используется даже для косвенных вопросов.
Зеркальный знак вопроса в скриптах с письмом справа налево
Зеркальный вопросительный знак на арабском и персидском языках
Сервисы google play на android: как обновить и убрать ошибку проверки обновлений
В арабском и других языках, использующих арабский шрифт, например персидский и урду , которые пишутся справа налево , вопросительный знак зеркально отражается справа налево от латинского вопросительного знака. В Юникоде доступны две кодировки: U + 061F ؟ ARABIC ВОПРОС MARK (HTML ·
с двунаправленным код AL: справа налево арабский) и U + 2E2E ⸮ ПЕРЕВЕРНУТЫМ вопросительный знак (HTML· с двунаправленным кодом Другие нейтралов). (Некоторые браузеры могут отображать символ в предыдущем предложении как прямой вопросительный знак из-за проблем со шрифтом или направленностью текста). Кроме того, тана сценарий Мальдивы использует зеркальный знак вопроса: މަރުހަބާ?
Арабский вопросительный знак также используется в некоторых других письмах справа налево: N’Ko и сирийском .
Иврит и идиш также пишутся справа налево, но они используют вопросительный знак, который появляется на странице в той же ориентации, что и вопросительный знак латинского алфавита.
Полный вопросительный знак на восточноазиатских языках
Вопросительный знак также используется в современном письме на китайском и японском языках , хотя и не является обязательным. Обычно он записывается в полноширинной форме на китайском и японском языках в Юникоде: U + FF1F ? ПОЛНОШИРИННЫЙ ВОПРОСНЫЙ ЗНАК (HTML ).
В других скриптах
Некоторые другие скрипты имеют особый вопросительный знак:
- U + 1367 ፧ ЭФИОПИЧЕСКИЙ ВОПРОСНЫЙ ЗНАК
- U + A60F ꘏ ВОПРОСНЫЙ ЗНАК VAI
- U + 2CFA ⳺ КОПТИЧЕСКИЙ СТАРЫЙ НУБИЙСКИЙ ЗНАК ПРЯМОГО ВОПРОСА и U + 2CFB ⳻ КОПТИЧЕСКИЙ СТАРЫЙ НУБИЙСКИЙ ЗНАК НЕПРЯМОГО ВОПРОСА
- U + 1945᥅ ЛИМБУ ВОПРОСНЫЙ ЗНАК
Коренные языки Канады
В Канаде некоторые языки коренных народов используют знак вопроса для обозначения ʔ :
- Чипевян
- Догриб
- Кутенай
- Мускусный язык
- Нутка
- Slavey
- Нитинахт
- Томпсон
- Lushootseed
Текстовые документы
Именно в документах Ворда, Блокнота и т.п. такая кодировка встречается чаще всего. Кодировка – набор знаков, благодаря которым происходит печать текста на определенном алфавите. Теоретически, любой документ сохраняется в различных шифрованиях, но пользователи почти никогда не прибегают к таким действиям. Потому, если Вы видите вместо букв вопросительные знаки и т.п., то маловероятно, что это сделано намеренно. Скорее всего, ввиду системного сбоя у пользователя, создавшего документ, он сохранился не в той кодировки. Кроме того, дело может быть и в сбои на Вашем ПК, в результате чего файл не открывается правильно.
Наиболее часто проблема возникает при использовании Блокнота. Также встречается в файлах php, css, info и подобных текстовых. Гораздо реже в Ворде. Кроме того, путаница с шифрованием встречается в браузере, там Вы также можете увидеть кракозябры вместо русских букв. В последнем случае избавиться от нее особенно трудно.