Кодирование информации
Содержание:
- Собственный велосипед
- Уменьшение размера TrueType шрифтов
- Машинные команды
- Создание текста с нужной кодировкой
- Лучшие сервисы антиплагиата
- Суть кодирования от алкоголизма
- Стандарт Юникод
- Особенности с которыми я столкнулся
- Примеры[править]
- 2.3 Префиксные блочные коды
- Общие сведения о кодировке текста
- Выбор кодировки при открытии файла
- 1.3 Контекст
- Пример
- Способ 2: Online Decoder
- Заключение
Собственный велосипед
Автоопределение кодировки возможно только эвристическими методами, не точно. Если мы не знаем на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы.
Второй критерий
К сожалению для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Уменьшение размера TrueType шрифтов
Файлы шрифтов часто очень объемные по размеру(более 100, и даже 200 КБ), это связано с тем, что они содержат символы, которые соответствуют для многих кодировок. Zlib сжатие уменьшает их, но они остаются достаточно большими. НО все же есть методика, которая поможет еще уменьшить. Методика состоит в том что при преобразовании шрифта Type1 с помощью ttf2pt1 нужно указать кодировку которая Вам нужна, и все символы соответствующие другим кодировкам будут проигнорированы.
Например, шрифт arial.ttf который поставляется с Windows 98 весит 267KB (он содержит 1296 знаков). После сжатия будет 147. Давайте преобразуем его в Type1, сохраняя только символы нужные для кодировки cp1250:ttf2pt1 -b -L cp1250.map c:\windows\fonts\arial.ttf arial
Файлы .map находятся в директории font/makefont/. При исполнении команды будут созданы некоторые файлы в числе которых: arial.pfb и arial.afm. Вес файла arial.pfb до сжатия составлял 35KB, а после 30KB.
Можно пойти еще дальше. Если Вас интересует только некоторые символы из общего количества 217 символов, Вы можете открыть файл с расширением .map и удалить ненужные строки, что соответственно позволит уменьшить вес файла.
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Создание текста с нужной кодировкой
Иногда возникает необходимость создания текстового файла в другой системе кодов. Например, для графического редактора PDF программы Works-6 или других программных продуктов. Редактор Word поможет Вам решить эту проблему. Нужно набрать текст так, как делаете обычно, соблюдая необходимую структуру и требования к набираемой информации.
После создания файла, в главном меню редактора заходим в ФАЙЛ, а далее выбираем СОХРАНИТЬ КАК.В выпадающем окне, кроме возможности определить будущее название файла, будут представлены варианты кодировки файла после сохранения.
Для предотвращения потери информации рекомендовано сохранить файл в обычном формате, а уже потом записать в требуемом.
Нужно учитывать, что существуют программы, которые не поддерживают переноса слов или строк текста. Поэтому, в данном случае, необходимо писать текст, избегая таких переносов.
Еще одна особенность при возникновении трудностей читаемости текста. Это небольшое отличие 2003 версии Worda от версий более поздних. Появился новый формат текстовых файлов – docx. Его отличие не носит вопрос кодировки, в том смысле, в котором мы его сейчас рассматриваем. И информацию такого рода на старой версии не просмотреть, необходимо обновление редактора.
Инструкция
Если у вас нет программы Word, то скачайте ее с официального сайта разработчиков и установите на свой компьютер. Если вы не собираетесь постоянно использовать эту программу, то платить за нее не нужно, вам хватит пробной версии.
Нажмите на нужный файл правой клавишей мышки и откройте подменю «Открыть с помощью», укажите программу Word. Если данной программы нет в списке, то запустите Word обычным способом. Откройте меню «Файл» и выберите команду «Открыть», укажите расположение нужного документа на жестком диске и нажмите «Открыть». Будет предложено несколько вариантов открытия файла, связанных с его нестандартной кодировкой, укажите нужный и нажмите команду ОК.
Подбор кодировки
Далее нужно изменить кодировку и сохранить результат, для этого откройте меню «Файл» и нажмите пункт «Сохранить как». Укажите директорию для измененного документа, впишите новое имя и выполните команду «Сохранить». Загрузится окно атрибутов документа, выберите нужную кодировку и нажмите Enter (наиболее используемой кодировкой является «Юникод»).
Внимательно отнеситесь к сохранению документа, если вы попытаетесь сохранить файл в прежнюю папку с прежним названием, то новый документ заменит собой старый файл
Чтобы сохранить на диске два разных документа, нужно использовать для них разные названия или папки.
При сохранении файла также обратите внимание на его расширение. Если документ в дальнейшем будет открываться с помощью программы Word 2003 года выпуска и более старшими версиями, то используйте формат doc
Если документ нужен для программы 2007 года и более новых версий, то подойдет формат docx. Также стоит помнить, что формат doc открывается как на старых версиях программы, так и на новых, но у них ограниченное форматирование. Стоит понимать, что отображение текстового документа не стандартными символами – это не только признак неизвестной кодировки, возможно в используемом редакторе нет нужного шрифта, в таком случае нужно менять не кодировку, а шрифт.
Лучшие сервисы антиплагиата
Наибольшим доверием пользуются следующие сервисы.
«Etxt Антиплагиат»
С 2015 г. сервис изменил название на AntiPlagiarism.NET.
Etxt Антиплагиат — софт для проверки текста на уникальность.
Система представлена в 2 вариантах:
- Онлайн.
- Автономном. Требуется скачать программу и установить на компьютер. Для работы нужен высокоскоростной интернет. Продукт условно бесплатный: после нескольких сеансов придется заплатить $20.
Недостаток — прерывание работы каждые 30 секунд для набора изображенного на капче кода. Это требует постоянного присутствия пользователя на месте. Онлайн-версия капчи не выбрасывает.
В безвозмездном варианте действуют ограничения: в течение суток проверяется не более 3 000 знаков, для зарегистрированных пользователей — 5 000. В платной версии объем текста не ограничен, но не более 15 тыс. знаков за 1 раз. Стоимость — 1,5 руб. за 1 тыс.
Общий недостаток всех версий Etxt — низкая скорость работы. Текст в 40-45 страниц проверяется 25 минут.
Система не подходит студентам, поскольку ищет совпадения по всей сети. Уникальность работы, в т.ч. добросовестно написанной, окажется ниже установленной преподавателем.
«Киллер Антиплагиат»
Многофункциональный ресурс:
- Проверяет тексты на уникальность.
- Предоставляет доступ к «Антиплагиату ВУЗ».
- Поднимает процент оригинальности материала до заданного пользователем уровня.
Киллер Антиплагиат — специальный сервис, который используют для улучшения уникальности.
Система повышает уникальность путем внесения изменений в машинный код документа (макросы). Текст не редактируется, буквы на латинские не меняются. Стоимость услуги — 5 руб. за страницу.
Пользователь действует в следующем порядке:
- Переводит средства (есть 50 способов).
- Загружает текст.
- Устанавливает в настройках желаемую уникальность. Чтобы работа не вызывала подозрений, рекомендуется устанавливать показатель не более 95%.
- Вводит адрес своей электронной почты.
Аналогичные услуги предоставляет «Антиплагиат.НЕТ».
Antiplagiat.ru
Первый отечественный продукт, название которого стало нарицательным для всех аналогичных систем. Создавался для анализа студенческих работ, поэтому похожие тексты ищет только в банках курсовых, рефератов и т.п. По этой причине не подходит владельцам информационных сайтов.
Antiplagiat.ru — программа для проверки текста на уникальность.
Преимущества:
- Быстрая проверка (около минуты).
- Неограниченный объем текста.
- Удобный интерфейс.
- Объективная оценка уникальности курсовой или реферата, поскольку материал сравнивается только с работами студентов. Antiplagiat.ru покажет более высокий процент уникальности, чем, например, Etxt.
Предлагается 2 вида услуг:
- Платная. Ограничений нет.
- Безвозмездная. Работает только с текстами в формате PDF и TXT. Повторную проверку позволяет сделать только спустя 6 минут после предыдущей.
Для начала работы с Antiplagiat.ru пользователю необходимо пройти несложную регистрацию.
Современный сервис Advego
По характеристикам идентичен Etxt:
- Представлен в 2 версиях — онлайн и автономной.
- Ищет совпадения во всем интернете (не подходит студентам).
- Проверка занимает много времени.
- Автономная версия часто выбрасывает капчу.
- Бесплатный онлайн-сервис позволяет обработать не более 5 тыс. знаков в сутки.
Advego считают одной из лучших среди приложений для проверки уникальности.
В отличие от Etxt, автономная версия Advego является бесплатной.
«Антиплагиат ВУЗ» для студентов
Данный продукт представляет собой модификацию Antiplagiat.ru с расширенным набором функций. Он предназначен для преподавателей, студенты не имеют доступа к системе.
Антиплагиат ВУЗ — самая популярная система проверки в вузах.
Главные отличия от базовой версии:
- Используется более широкий перечень банков готовых рефератов и курсовых.
- Формируется сертификат о прохождении проверки программой «Антиплагиат ВУЗ». Его прикладывают к работе.
Для пользования программой высшее учебное заведение заключает договор с разработчиком. Стоимость лицензии сроком на год составляет 300-350 тыс. руб.
Суть кодирования от алкоголизма
Все методы такого «перепрограммирования» зависимых основаны на развитии негативной реакции на этиловый спирт за счет образования условных рефлексов на соответствующие внешние раздражители. Внушение запрета на алкоголь достигается различными методами – при помощи фармакологического действия лекарственных средств, а также с применением психотерапевтических или физиотерапевтических методик.
Основные задачи любого способа кодировки:
- развитие условного рефлекса отвращения к алкоголю;
- возвращение пациента к полноценной жизни в обществе за время кодирования;
- нормализация всех жизненно важных функций организма;
- восстановление комфортного эмоционального климата в общении с окружающими;
- длительный отказ от спиртного даже после окончания терапевтического эффекта.
Стандарт Юникод
Консорциум Unicode (Юникод) – некоммерческая организация, главной задачей которой являлась разработка стандарта кодирования (стандарт Юникод) с поддержкой наибольшего числа языков и символов служебного характера. Принцип кодирования на основе таблицы сохранился, а таблица (таблица Юникод) была значительно расширена.
Стандарт Юникод предоставляет пользователям таблицу Юникод и способы кодирования символов.
Символы таблицы Юникод являются элементами «универсального набора символов» UCS (Universal Coded Character Set), определенного международным стандартом ISO/IEC 10646. Таблица Юникод каждому символу UCS сопоставляет кодовую точку, которая является номером ячейки таблицы, содержащей символ.
Способы кодирования символов таблицы Юникод, т.е. преобразования номеров ячеек таблицы Юникод в бинарные коды, составляют кодовое пространство, состоящее из трех кодов семейства UTF (Unicode Transformation Format): UTF-8, UTF-16 и UTF-32
UTF-8 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32.
UTF-16 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
Коды UTF-8 и UTF-16 используют разные алгоритмы кодирования набора символов UCS.
Особенности с которыми я столкнулся
Чуть коснусь прелестей и проблем связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Что делать если интерфейс является входным параметром нашей функции? Например если мы принимаем io.Reader, проверить его на nil ведь надо. Проверить на существование переменной типа io.Reader мне удалось только с помощью рефлексии.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы хранящиеся в map пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно быстро давало результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Примеры[править]
Если записать строку ‘hello мир’ в файл exampleBOM, а затем сделать его hex-дамп, то можно убедиться в том, что разные символы кодируются разным количеством байт. Например, английские буквы,пробел, знаки препинания и пр. кодируются одним байтом, а русские буквы — двумя
Код на pythonправить
#!/usr/bin/env python
#coding:utf-8
import codecs
f = open('exampleBOM','w')
b = u'hello мир'
f.write(codecs.BOM_UTF8)
f.write(b.encode('utf-8'))
f.close()
hex-дамп файла exampleBOMправить
| Символ | BOM | h | e | l | l | o | Пробел | м | и | р | |||||
| Код в UNICODE | EF | BB | BF | 68 | 65 | 6C | 6C | 6F | 20 | D0 | BC | D0 | B8 | D1 | 80 |
| Код в UTF-8 | 11101111 | 10111011 | 10111111 | 01101000 | 01100101 | 01101100 | 01101100 | 01101111 | 00100000 | 11010000 | 10111100 | 11010000 | 10111000 | 11010001 | 10000000 |
2.3 Префиксные блочные коды
Для решения проблемы предыдущего примера нам нужно использовать префиксные коды — это такой код, который при чтении можно однозначно раскодировать в нужный символ, так как он есть только у него. Помните ранее мы говорили про азбуку Морзе и там префиксом была пауза. Вот и сейчас нам нужно ввести в обращение какой-то код, который будет определять начало и/или конец конкретного значения кода.
Составим третью таблицу всё для той же строки:
|
Символ |
Количество |
Префиксный код с переменными блоками, бит |
|---|---|---|
|
ПРОБЕЛ |
18 |
000 |
|
Р |
12 |
001 |
|
К |
11 |
010 |
|
Е |
11 |
011 |
|
У |
9 |
100 |
|
А |
8 |
101 |
|
Г |
4 |
110 |
|
В |
3 |
111 |
|
Ч |
2 |
10001 |
|
Л |
2 |
10010 |
|
И |
2 |
10011 |
|
З |
2 |
10100 |
|
Д |
1 |
10101 |
|
Х |
1 |
10110 |
|
С |
1 |
10111 |
|
Т |
1 |
11000 |
|
Ц |
1 |
11001 |
|
Н |
1 |
11010 |
|
П |
1 |
11011 |
Особенность новых кодов в том, что первый бит мы используем для указания размера следующего за ним блока, где 0 — блок в три бита, 1 — блок в четыре бита. Нетрудно посчитать, что такой подход закодирует нашу строку в 379 бит. Ранее при блочном кодировании у нас получился результат в 455 бит.
Можно развить этот подход и префикс увеличить до 2 бит, что позволит нам создать 4 группы блоков:
|
Символ |
Количество |
Префиксный код с переменными блоками, бит |
|---|---|---|
|
ПРОБЕЛ |
18 |
000 |
|
Р |
12 |
001 |
|
К |
11 |
0100 |
|
Е |
11 |
0101 |
|
У |
9 |
0110 |
|
А |
8 |
0111 |
|
Г |
4 |
10000 |
|
В |
3 |
10001 |
|
Ч |
2 |
10010 |
|
Л |
2 |
10011 |
|
И |
2 |
10100 |
|
З |
2 |
10101 |
|
Д |
1 |
10110 |
|
Х |
1 |
10111 |
|
С |
1 |
11000 |
|
Т |
1 |
11001 |
|
Ц |
1 |
11010 |
|
Н |
1 |
11011 |
|
П |
1 |
11100 |
Где 00 — блок в 1 бит, 01 — в 2 бита, 10 и 11 — в 3 бита. Подсчитываем размер строки — 356 бит.
В итоге, за три модификации одного способа, мы регулярно уменьшаем размер строки, от 455 до 379, а затем до 356 бит.
Общие сведения о кодировке текста
Текст, который отображается в виде текста на экране, на самом деле сохраняется как числовые значения в текстовом файле. Компьютер переводит числовые значения в видимые символы. Для этого используется стандарт кодировки.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
-
Откройте вкладку Файл.
-
Нажмите кнопку Параметры.
-
Нажмите кнопку Дополнительно.
-
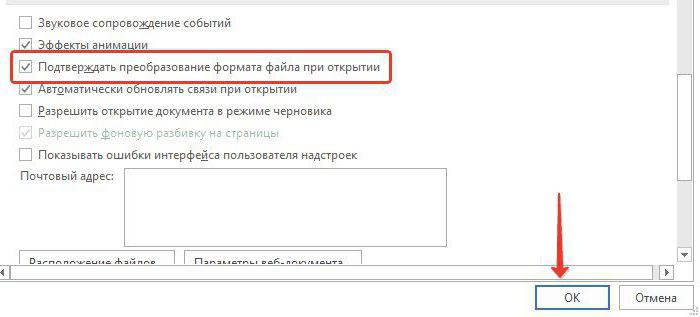
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
-
Закройте, а затем снова откройте файл.
-
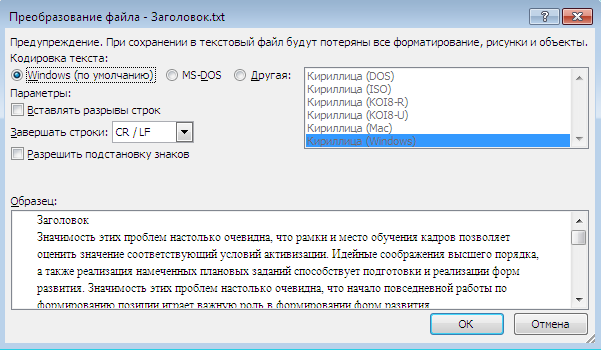
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
-
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
-
Нажмите кнопку Пуск и выберите пункт Панель управления.
-
Выполните одно из указанных ниже действий.
В Windows 7
-
На панели управления выберите элемент Удаление программ.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
-
На панели управления выберите раздел Удаление программы.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
-
На панели управления щелкните элемент Установка и удаление программ.
-
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
-
-
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
-
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
-
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной — звук, видео, текст
Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук — череда дискретных значений о звуковом сигнале, видео — череда кадров изображений, текст — череда символов текста
Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим — час или даже пара недель.
Пример
Давайте посмотрим, маленький полностью рабочий пример. Будет использоваться шрифт Calligrapher, который Вы можете скачать на сайте — http://www.abstractfonts.com/ (сайт, предлагает большое количество бесплатных TrueType шрифтов). Ссылка для загрузки шрифта — http://www.abstractfonts.com/download/52. Первым шагом является генерация AFM-файла:ttf2pt1 -a calligra.ttf calligra
которая дает calligra.afm (и calligra.t1a, который можно удалить). Затем мы создаем файл определения:
require('font/makefont/makefont.php');
MakeFont('calligra.ttf','calligra.afm');
|
Вызов функции даст следующие сообщения:
Warning: character Euro is missing
Warning: character eth is missing
Font file compressed (calligra.z)
Font definition file generated (calligra.php)
Символ Euro отсутствует, так как слишком старый. Другие символы также отсутствуют, однако они нам не понадобятся.
Теперь можно скопировать два файла в директорию и написать сценарий:
require('fpdf.php');
$pdf=new FPDF();
$pdf->AddFont('Calligrapher','','calligra.php');
$pdf->AddPage();
$pdf->SetFont('Calligrapher','',35);
$pdf->Cell(,10,'Enjoy new fonts with FPDF!');
$pdf->Output();
|
Вот что должно получиться в итоге:

Способ 2: Online Decoder
- Воспользуйтесь ссылкой выше или самостоятельно откройте главную страницу сайта Online Decoder, где сразу же активируйте поле для ввода и вставьте туда целевой текст.
Напротив пункта «Раскодировать текст автоматически (рекомендуется)» нажмите по кнопке «Подбор» для запуска процесса распознавания.
Та кодировка, в которую выполнен перевод, отображается второй.
Исходная находится прямо после надписи «Я знаю нужные кодировки». Ее и надо узнать, если речь идет об определении стилистики символов.
Перевод в выбранную конечную кодировку вы видите внизу, можете его изменить или скопировать.
Используйте дополнительные инструменты сайта Online Decoder, если нужно продолжить взаимодействие с другими надписями.
Заключение
Зачем нам знать, как менять кодировку в текстовых редакторах? IDE Visual C++ сама выбирает кодировку. Если вы откроете любой файл с исходным кодом (.cpp или .h) в простом текстовом редакторе, то увидите, что кодировка этого файла — ANSI.
В программах на ассемблере мы тоже будем использовать ANSI — этого требует компилятор. А вот когда будем разбирать скриптовые языки, то файлы с исходниками можно будет сохранять в UTF-8.
Источники
- http://oldshatalov.ghost17.ru/ru/articles/theory/text_editors.html
- https://mb4.ru/text-editors/notepad/146-notepad-change-default-encoding.html
- http://workip.ru/stati/smena-kodirovki-teksta-v-bloknote.html
- https://besthard.ru/faq/kak-izmenit-kodirovku-v-vord/
- https://support.office.com/ru-ru/article/%D0%B2%D1%8B%D0%B1%D0%BE%D1%80-%D0%BA%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B8-%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%B0-%D0%BF%D1%80%D0%B8-%D0%BE%D1%82%D0%BA%D1%80%D1%8B%D1%82%D0%B8%D0%B8-%D0%B8-%D1%81%D0%BE%D1%85%D1%80%D0%B0%D0%BD%D0%B5%D0%BD%D0%B8%D0%B8-%D1%84%D0%B0%D0%B9%D0%BB%D0%BE%D0%B2-60d59c21-88b5-4006-831c-d536d42fd861