Key collector
Содержание:
- Почему лучше не участвовать в складчине
- Другие функции Кей Коллектора полезные для директолога:
- Что такое Key Collector?
- Удаление и сокрытие групп
- Как купить со скидкой первую лицензию?
- Группировка
- Что собой представляет key collector?
- Кей коллектор и семантика
- Быстрый сбор СЯ
- Сбор семантики
- Дополнительный анализ семантики
- Создание структуры
- Выделение и отметка фраз
- Сколько стоит Key Collector
- Сбор семантики
Почему лучше не участвовать в складчине
Прежде всего необходимо понимать, что складчина — это объединение людей, которые решили получить максимально низкую цену путем покупки множества лицензий. Это частная инициатива, а не наши партнеры или реселлеры.
Как правило, покупка происходит на один адрес почты какого-то одного человека, который затем распределяет купленные лицензии среди участников складчины.
Владельцем ВСЕХ лицензий в этом случае является тот самый владелец почты, на которую оформляются приобретаемые совместно лицензии.
Вы не сможете купить лицензию вскладчину по скидке, а потом отделить ее на свою личную почту. Для этого потребуется доплата разницы до полной стоимости лицензии (весь смысл участия в складчине теряется), а также согласие владельца лицензии, которым вы пока еще не являетесь.
Таким образом, в случае потери контакта с данным лицом или просто его личным решением освободить себя от каких-либо обязательств перед участниками складчины (или же просто «кинуть» их) последние полностью теряют какие-либо возможности по управлению «своими» (на самом деле — нет) лицензиями.
В этом случае мы никак не можем помочь им восстановить какую-либо справедливость, т.к. это был их осознанный риск и решение доверить свои деньги третьему лицу.
В целях защиты наших конечных клиентов от потери денег и лицензий мы стараемся предотвращать такие складчины, т.к. уже несколько раз их организаторы просто пропадали, и на нас ложилась волна негодования от участников этих складчин. К сожалению, помочь мы им ничем не смогли, т.к. фактическим владельцем и плательщиком денег в нашу сторону был именно организатор. Соответственно, без его согласия никаких операций с его лицензиями мы делать не можем.
Какая вам разница, как мы купили лицензию: напрямую или в складчину?
Свое мнение мы отразили в обсуждении акции по легализации:https://vk.com/wall-62285053_9332
Приведем некоторые наши комментарии для понимания сути процессов, происходящих при покупке в складчину и пропаже ее организатора.
Был пользователь, который на форуме предлагал людям купить программу дешевле, чем продаем мы. При этом он покупал лицензию как «двадцатую» для себя, оформлял на себя, а тем, кто переводил ему деньги, просто передавал файл лицензии. Все лицензии были привязаны на его почту, а не на тех, кому он их передавал впоследствии.
Если нужно было поменять лицензию, люди обращались к нему, и он это производил со своей почты и заново высылал им файл.
Пользователь платит 1 раз и пользуется программой постоянно. Кто купил 6 лет назад и заплатил за нее 700 рублей — тот пользуется программой, обновлениями, саппортом, до сих пор. Никаких доп. «поборов» мы не проводим.
Владельцы складчин предлагают купить программу за 1300-1400 руб., при этом покупая ее у нас за 1200 руб. по накопительной скидке. Пользователь доволен — получил скидку в несколько сотен. Складчик доволен — получил 100-200 рублей прибыли. Мы получили не 1700 руб., а 1200 руб., но при этом пользователя мы обслуживаем также, ни в чем не ущемляя.
До определенной поры мы закрывали на это глаза, но на этой неделе пропал очередной такой организатор складчины, и мы получаем тучу негатива от пользователей, которые купили через него.
Оно нам надо? Мы как оказывали поддержку, так и оказываем, но не имеем никакого права отбирать у владельца складчины лицензии, ведь платил-то нам именно он, и заявка на его почту была.
В результате он пропал, пользователи льют на нас негатив, саппорт вместо развития программы и решения вопросов пользователей по пол дня отписывает в формате «война и мир» ситуацию, объясняя, кто владелец лицензии.
Есть крупная сео-контора. Она покупает, допустим, 20 лицензий на 20 сотрудников. Один из двадцати является руководителем отдела продвижения, он знает софт, он задает нам вопросы, мы на них отвечаем. Далее он обучает остальных 19 сотрудников работе с софтом. В результате мы выдали 20 лицензий и получили нагрузку в службу поддержки, равную 1 пользователю.
Теперь о складчине. Человек купил 20 лицензий, выдал 20 разным людям. В результате мы получили нагрузку на саппорт, равную 20 пользователям, но при этом НЕДОполучили средства на развитие программы.
Мы устали разгребать письма и звонки, которые происходят после того, как организатор ушел в запой/отпуск/офлайн/иной мир.
Другие функции Кей Коллектора полезные для директолога:
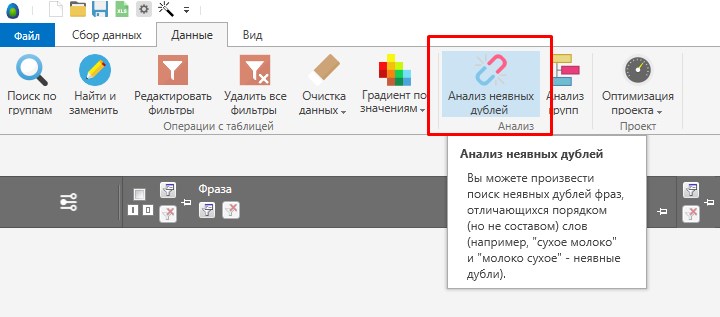
Удаление неявных дублей.
Если перейти во вкладку «Данные», то там будет полезная функция «Анализ неявных дублей», с помощью данной функции вы можете очистить собранное семантическое ядро не только от дублей, но и то неявных дублей. Например: как убрать комнату и как комнату убрать, будут считаться дублями. Программа покажет какие есть дубли, в каких группах, там же есть кнопка «Умная отметка», она автоматом выделяет один из дублей и вы его (или их удаляете), т.е. самостоятельно выделять и удалять дубли не надо, это делается в два клика.
Фильтры.
Каждый столбец в программе имеет самые различные фильтра. Например в столбце «Фразы» по фильтрам можно отыскать нужные ключевые слова, можно найти ключевые слова, которые состоят из определенного числа слов, это удобно при группировки ключей при обходе статуса «мало показов», когда в одну группу помещаются ключи с малой частотностью, но схожие по смыслу и написанию; в столбце «Базовая чистота», можно отфильтровать частотность по любому направлению (все ключи больше или равны 10, или меньше 5 и т.д.).

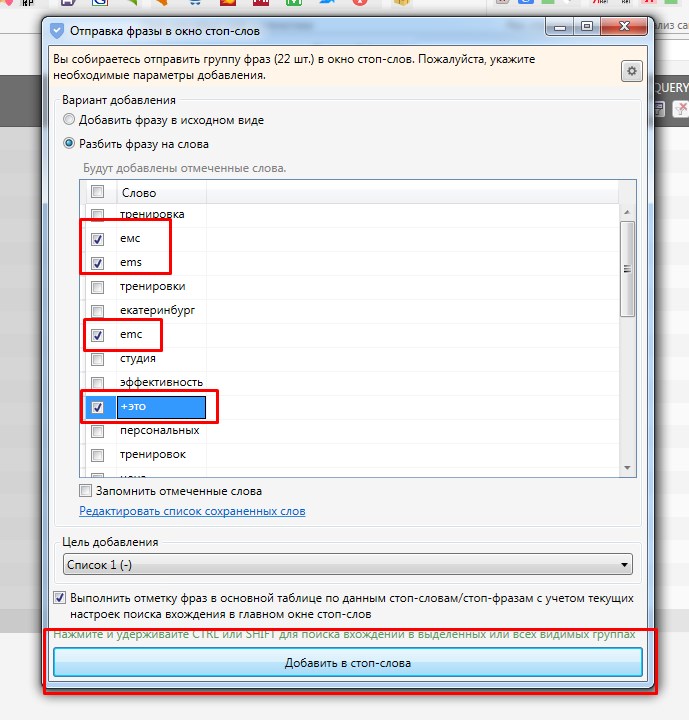
Быстрое составление списка минус слов.
Для того, чтобы максимально комфортно собрать полный список минус слов, достаточно выделить все ключевые слова, кликнуть правой кнопкой мыши на них и выбрать «Отправить выделенные фразы в окно стоп-слов». После этого откроется список со всеми выделенными ключами, где отмечая нужные слова далее их помещаем в список минус-слов.
Режим мульти-группы.
Для того, чтобы выгрузить полученное семантическое ядро в единый эксель файл, или применить на все группы (папки) ключей минус слов и т.д. и т.п. необходимо сначала выделить все папки, и нажать на мульти-группы, и только тогда все папки как-бы объединяться в одну. Например: у вас много папок, и вы хотите выгрузить полное семантическое ядро в один единый файл в формате эксель. Если просто выделить все папки, то в эксель отправиться лишь одна папка, а для выбора и работы со всеми папками, как раз и нужен режим мульти-группа:

Сбор частотности ключевых слов.
С помощью Кей Коллектора можно не только парсить ключевые слова, но и собирать статистику с нужных ключевых слов. Это пригодиться тогда, когда вы делаете искусственную семантику и нужно ключи не спарсить, а просто узнать их частотность.
Для этого выбираем значок «Д», как указано на картинке, выбираем нужное гео именно в открывшейся вкладке и жмем «Получить данные»:

Что такое Key Collector?
Кей Коллектор – это платная утилита, которая повсеместно используется сеошниками и маркетологами. Суть ее состоит в почти полной автоматизации сбора семантического ядра. Приложение тесно интегрировано с Яндекс Директом, Вордстатом, гугловскими сервисами и прочими инструментами, которые поодиночке не выглядят такими практичными.
То есть Key Collector объединяет в себе несколько сервисов, интегрируя их возможности. Это позволяет людям легко и просто парсить запросы с того же Вордстата или Директа, в последствии превращая их во вполне себе обоснованное семантическое ядро.
Как я уже сказал, чтобы пользоваться программой, ее придется купить. Разработчики очень сильно заботятся о сохранении лицензии, поэтому каждая отдельная программа привязывается к одному персональному компьютеру с помощью идентификатора жесткого диска. Следовательно, вы не сможете скачать приложение, чтобы использовать его на нескольких машинах – 1 лицензия для 1 компьютера.
В интернете, конечно, есть взломанные версии, которые якобы предоставляют те же возможности, что и оригинал. Однако стоит учитывать, что через пиратское ПО очень часто распространяются вирусы
Если уж вы не хотите покупать Коллектор, то я бы рекомендовал вам обратить внимание на СловоЁб. Это бесплатное приложение от тех же разработчиков, которое представляет собой урезанный вариант Коллектора
Теперь давайте более подробно рассмотрим возможности программы. Итак, как заявляют разработчики, с помощью Key Collector мы сможем составить более точное семантическое ядро, не прибегая к помощи сторонних специалистов. Нам лишь нужно правильно настроить все параметры и познать некоторые азы.
Надо сказать, что Key Collector не работает с готовыми базами данных, которые требуют постоянные обновления. Он парсит всю информацию в реальном времени через интернет, подключаясь ко все тем же сервисам: Вордстат, Яндекс Директ, Гугл Адвордс и прочим. Такой подход гарантирует вам актуальность всех ключей, которые вы получите на выходе.
Эта программа поможет вам увидеть наиболее популярные страницы вашего сайта, определить верную стратегию продвижения, основываясь на статистических данных. В конечном итоге вы можете выгрузить всю информацию в удобный формат, например, в таблицу Excel.
Я уверен, что купить программу определенно стоит. Если понять, как работать, то это может сэкономить существенную часть финансов и времени. Да и проекты с качественной семантикой будут давать больше отдачи, что также является плюсом.
Удаление и сокрытие групп
Вы можете удалять или скрывать ненужные группы с фразами через контекстное меню или горячими клавишами.
При добавлении фраз (вручную или в процессе парсинга) при использовании режима добавления с пропуском существующих фраз в других группах фразы в скрытых группах будут считаться существующими (несмотря на то, что сама группа скрыта и не отображается в дереве групп), т.е. такие фразы будут пропущены как дубликаты, а фразы в помеченных на удаление группах будут считаться отсутствующими, т.к. такие фразы будут добавлены в таблицу.
Отличие помеченной на удаление группы от скрытой состоит также в том, что при закрытии проекта программа запросит подтверждение на безвозвратное удаление помеченных на удаление групп, когда как скрытые группы так и продолжат существовать в проекте.
Для удаления или сокрытия групп сперва необходимо выделить группы.
Для выделения подряд идущих групп удобно воспользоваться зажатой клавишей Shift и кликнуть сперва по первой, а затем по последней группе в требуемом диапазоне. При необходимости выделить подгруппы некоторых групп воспользуйтесь соответствующей кнопкой в контекстном меню заголовка группы или же на вкладке инструментов «Управление группами».
Восстановление групп
Для восстановления скрытых или помеченных на удаление групп нажмите кнопку в нижнем правом углу панели управления группами, отметьте нужные группы и нажмите «Восстановить».
Как купить со скидкой первую лицензию?
К сожалению, у нас нет практики использования постоянных скидок для первичных лицензией. Однако, вы можете вступить внашу группу ВКонтактеи дождаться раздачи промокодов на первую лицензию.
Если вы ввели промокод, но ссылка на оплату пришла по полной стоимости, это означает, что код уже был активирован или введен неверно.
Как правило, скидка по промокоду не превышает 200-300 руб., а сами промокоды выдаются в ограниченном количестве, нерегулярно, без предварительного информирования и не чаще 1 раза в месяц.
Обращаем ваше внимание, что никто из специалистов тех. поддержки не продает промокоды и не обладает правом выдачи таковых.
Группировка
В Кей Коллекторе можно делать группировку вручную и с помощью автоматического кластеризатора.
Для ручной группировки отметьте нужные ключи и выберите / создайте новую папку для переноса.

Для автоматической группировки воспользуйтесь инструментом «Анализ групп» во вкладке «Данные».

Есть несколько способов группировки и несколько уровней силы кластеризации:
- По выдаче.
- По составу фраз – группировка на основе слов в ключевой фразе.
- Комбинация этих способов.
Для кластеризации в соответствии с выдачей нужно снять ее данные. Для этого подходит инструмент Вычисления KEI.

Ускорить процесс можно с помощью XML-лимитов. Также можно парсить выдачу в несколько потоков, если используются прокси.

Автоматическая группировка в Кей Коллектор не выдаст хороших групп, а наделает массу смысловых дублей, какие бы параметры кластеризации вы ни выбрали. Поэтому такой способ больше подходит для группировки мусорных фраз и дальнейшего их удаления целыми кластерами.
Что собой представляет key collector?
Из слов в названии — кей коллектор — становится понятно: это сборщик ключей. В понимании SEO-шников смыслом программы является собирание ключевых слов для продвижения сайта вверх по списку в поиске
Еще одна особенность «кей», на которую стоит обратить внимание — помощь с определением стоимости сайта и соответствием содержимого ядра. Это приятная, простая и сильная программа для продвижения порталов
- Основные функции программы:
- Подбор ключевой фразы – запроса/запросов;
- Определение стоимости и ценности содержащихся фраз;
- Выявление страницы по релевантности;
- Съем по позициям;
- Советы по перелинковке сайта.
Знакомство с программой Кей коллектор:
Итак, вам для сайта нужна SEO-оптимизация, и вы начали работу. Прежде, чем вы запустите программу и приступите к полномасштабной работе с «кей», разбирая ядро, необходимо узнать и понять ключевые моменты, имеющие отношение к seo и сопутствующим моментам. Без знакомства с ними невозможно работать не только в программе, но и в области SEO в принципе.Для начала знакомства открываем вкладку «Быстрое знакомство с Key Collector».Пункт 1 рассказывает, что система не любит наглые методы продвижения. За это аккаунты, привязанные к Key Collector могут подвергнуться блокировки со стороны поисковых систем.
- Чтобы избежать этих проблем, не следует применять:
- слишком большой поток данных из ядра;
- малые задержки, когда запросы обрабатываются;
- не делать лишние запросы.
Последним правилом нередко пренебрегают люди, только недавно начавшие заниматься продвижением по ключевым словам из семантического ядра. Излишне собирать статистику не стоит: это не только не даст продвижения сайта, но и разрушит всю затею на корню. Подходите к статистике грамотно. Тщательно и внимательно составляйте ее, и вы без труда найдете всю нужную информацию.
Первым шагом будет снять запросы с пустыми и лишними фразами
Также важно убрать такие элементы, как частотность в Wordstat на Яндекс, причем все, что есть. Для этого используют 4-ый метод скоростного сбора на Яндекс.Директ и Google Adwords
В последнем отображается информация о конкурентности запросов, также снятие сезонности у него шустрее, чем у Яндекса.С особым трепетом отнеситесь к пакетам статистики, их надо собирать с двойной осторожностью
- К таковым относят:
- пакетный сбор фраз из различных платформ;
- подсказки с применением перебора;
- статистика агрегаторов ссылок.
Причин такой осторожности достаточно. Зачастую информация из ядра собирается медленно, лимит на запросы маленький, а длится все это мучительно долго из-за большой кучи переходов
Это основные причины важности такой операции
Поэтому делом совести будет дать пару советов начинающему пользователю для наиболее успешного продвижения своего сайта:
- Перебирайте семантическое ядро вручную как можно меньше;
- Создавайте много групп;
- Работайте с ними по несколько сразу;
- Работайте с мультигруппами;
- Почаще применяйте фильтры.
- Удаляйте запросы со стоп-словами, а если без них не получается — сводите к минимуму.

Кей коллектор и семантика
Работа с подбором ключевых вхождений после создания сайта не заканчивается, поэтому ресурс будет полезен не только разработчикам. Продвижение контекстной рекламой, работа с заголовками и многие другие задачи требуют знания частотности.
Бесспорно, Key Collector — лучшая утилита анализа статистики по запросам. Когда начинаешь пользоваться, возникает масса вопросов. Какие прокси использовать, какие кнопки нужные, какие настройки использовать, как собирать статистику, чтоб тебя не заблокировали? Все настроил, через какое-то время заходишь и уже ничего не можешь вспомнить. Заново приходится изучать. Это отнимает много времени, и хочется делегировать работу в надежные руки. С Моабом все становится в разы проще: купил подписку и юзай, без заморочек. Временных лимитов у услуги нет и это большой плюс.
Тем, кто ручками в вордстате сборку делает, совсем не позавидуешь. Там одну капчу запаришься вводить. В Моабе все становится совсем просто. Вносишь список слов и запускаешь процесс. Служба соберет тебе слова на всю указанную глубину, выдаст подсказки, уберет дубли и выдаст все одним файлом. Пользуйтесь.
Быстрый сбор СЯ
Теперь отличная новость: Сборщик и Моаб объединили свои усилия и работают в связке. Свой аккаунт на Mother Of All Businesses вы подключаете к Key Collector и спокойно собираете ядрышко на компьютере. Все настройки Моаба будут применены к вашей программулине, и сбор будет происходить без капчей и проксей.
https://youtube.com/watch?v=AltAH6y-Fl0
Но интеграция это еще не самое интересное! В честь объединения усилий Моаб устраивает акцию: При покупке пакета ПРО, вы получаете лицензию на утилиту в подарок! Блок от MOAB Tools рассчитан на пятьсот тысяч проверок + лицензия На кей коллектор ценой в одну тысячу восемьсот рублей. Предложение действительно интересное. Дополнительным бонусом объявлено о скидках в у партнеров общим счетом почти пятьдесят тысяч рублей.

Список партнеров и скидок на их услуги действительно впечатляет. К примеру, в системе аналитики, автоматизации и управления проектами SEO CRM, а это неплохой старт для развития площадки. Есть в списке скидки на весьма полезные обучающие тренинги, на которых изучается семантика и контекстная реклама. В общем, дополнительные плюшки неплохие. Рекомендую не затягивать, а воспользоваться акцией.
Как подключить Моаб и выполнить быстрый сбор семанитики
Чтобы подключить Моабу к проге от LegatoSoft, нужно выполнить пару несложных шагов. Зарегистрироваться на портале, зайти в раздел API-ключ и нажать на кнопку скопировать. В КК зайти в настройки — парсинг и вставить ключ в строку Токкен. На панели увидите две кнопочки собрать фразы Вордстат и собрать частоты. Первая собирает слова из Яндекс.Вордстата, а вторая служит для подсчета частотности имеющихся фраз через службу.
Взаимодействие происходит в таком порядке. Вы пишете фразу в интерфейсе, эта задача после нажатия кнопки передается на обработку в Tools. КК ждет ответа на поставленную задачу. Как только задание обработается на сервисе, данные тут же поступают на ваш рабочий стол. Ход выполнения задачи отображается на вкладке статистика и в отдельном событийном журнале. Никакой лишней нагрузки на ваш комп и канал Интернет не возлагается.
Если кей коллектор у вас уже есть, то можно не заморачиваться с полным Про, а попробовать любой другой подешевле. Если проги нет, то не раздумывайте, а берите полный набор. Это очень удобно. Как бы вы не старались, а чтобы разобраться с программой у вас уйдет пара дней, или неделя. Воспользовавшись акцией, вы можете сходу начать работу с семантикой, а выигранное время потратить на изучение бонусных программ. Ограничений по времени в этом сервисе нет, полмиллиона ключевиков вам хватит надолго для подпитки своего ядра.
Сбор семантики
Допустим, вам нужно собрать семантическое ядро для рекламы в Яндекс.Директ. Запустите Key Collector и откройте настройки кликом по шестеренке:
Настройки парсинга
Перейдите в раздел «Парсинг» и здесь внесите следующие изменения:
1) На вкладке «Общие» уберите знак плюс в поле «Удалять символы» – в Директе плюсы мы не используем.
2) На вкладке «Yandex.Direct» впишите данные по аккаунту, который нужно предварительно создать специально для парсинга.
Дело в том, что Яндекс лоялен к парсерам, так как с помощью них рекламодатели могут настроить более качественные рекламные объявления. Это с одной стороны.
С другой – рабочий аккаунт использовать ни в коем случае нельзя. Яндекс может его забанить за нарушение правил пользования сервисом (из-за автоматических запросов)
Лучше рискнуть потерять доступ к «фейковому» аккаунту, а не к настоящему.
Важно! Несмотря на то, что аккаунты «фейковые», задавайте им читабельные имена пользователей, чтобы впредь процесс не тормозили капчи Яндекса.
Также обратите внимание на настройки:
- Автоматически перезапускать процесс при ошибке «Сервис недоступен» через 120 секунд. Иногда Yandex.Direct становится временно недоступен. Эта галочка включает повторную попытку собрать статистику.
- Валюта. По умолчанию цены, бюджеты, стоимость клика в рублях. После изменения типа необходимо переоткрыть проект.
3) На вкладке Yandex Wordstat ничего не меняйте – подойдут настройки по умолчанию.
Кратко скажем об основных.
Глубина парсинга – это количество обходов списка слов, которое делает программа для одного ключевика. Соответственно, чем больше раз – тем больше слов и времени идет на обработку. Рекомендованная глубина 2 – так вы сразу получаете результаты парсинга + дополнительную выдачу по каждому из них.
Парсить страниц – сколько страниц в выдаче будет просматривать программа. Максимум в Wordstat – 40, на каждой – до 50 фраз, то есть 2 тысячи результатов по одной фразе. Сервис предлагает такое количество лишь для ВЧ-запросов.
Добавлять в таблицу фразы с частотностями … – задаем диапазон частотностей. Чтобы избежать потери важных ключевиков, используйте фильтрацию в таблицах данных.
Не снимать частотности для фраз с базовой частотностью равной или ниже, чем … – это экономит время, трафик, а также позволяет снизить вероятность получения капчи, исключая из проверки заведомо не интересующие фразы.
Не добавлять фразы для глубинного исследования с базовой частотностью равной или ниже, чем … – это сокращает время на сбор информации за счет игнорирования недостаточно популярных фраз с низкой базовой частотностью.
Считать медиану за последние … месяцев. Программа вычисляет значение по указанному периоду при сборе данных о сезонности.
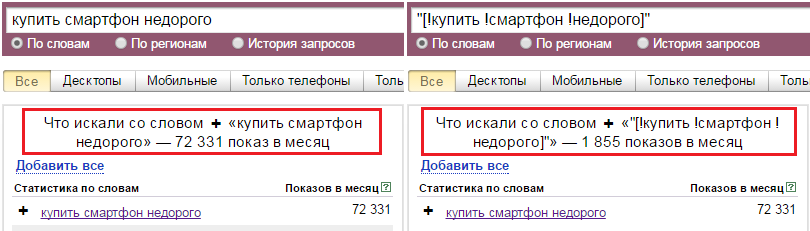
Принудительно очищать знак + из запросов для частотностей « » и «!». При снятии частотностей вида « » и «!», запрос заключается в кавычки. При этом знак +, если это оператор, теряет смысл – его нужно отфильтровать, что и позволяет эта опция. Если это часть запроса, фильтрация не нужна.
Получать статистику через Yandex.Direct. Данная опция позволяет снимать статистику Yandex.Wordstat (кроме данных сезонности) через интерфейс Yandex.Direct. Это резервный режим на случай, если заблокирован доступ к Yandex.Wordstat. Для его запуска нужно прописать доступ к аккаунтам Яндекс.Директа во вкладке «Yandex.Direct».
4) На вкладке «Подсказки» – аналогично.
Внизу окна программы также не забудьте настроить целевые регионы для Вордстата и Яндекс.Директа (или другой системы, для которой собираете семантическое ядро).
На этом настройки парсинга готовы.
С чего начать парсинг
Кликните иконку «Добавить фразы»:
В окно вставьте исходные фразы (маски / базисы ключевых слов):
Рекомендуем подключить автораспознавание капчи, чтобы она не мешала работе Key Collector. Особенно если вы планируете парсить большие объемы ключей. Актуальные цифры по стоимости смотрите в разделе «Антикапча» по ссылкам.
Нажмите кнопку «Начать сбор» в этом окне – и процесс запустится!
Кстати, найти еще больше целевых ключей помогут поисковые подсказки. Собрать их в Key Collector можно нажатием следующей кнопке в верхнем меню:
Затем остается скопировать сюда список маркеров и отметить галочкой поисковую систему, из которой хотите получить подсказки – и сервис начнет сбор.
Дополнительный анализ семантики
Программа Key Collector также позволяет изучить запросы на предмет конкурентности (иногда это называют сложностью запроса) и сезонности, а также разбить на кластеры, что важно уже на этапе создания рекламы. Рассмотрим эти функции.
Оценка конкурентности запросов
Уровень конкуренции запросов зависит от:
- Количества документов в поисковой выдаче по этому запросу
- Количества главных страниц в поисковой выдаче
- Количества точных вхождений ключа в заголовки страниц выдачи.
В Key Collector можно рассчитать этот показатель как в зависимости от количества страниц в выдаче (деление количества страниц на частотность ключевой фразы), так и настроить в формуле все перечисленные показатели.
Для этого найдите функцию KEI и примените её к списку ключей, которые у вас получились в результате сбора семантики.
Найдите в меню такой значок, как показано на скриншоте, и нажмите «Рассчитать KEI по имеющимся данным»:

Можно оставить формулу по умолчанию, а можно установить свою, добавив в настройках «KEI & SERP» нужные колонки:

Соответственно, чем выше значения получатся, тем выше уровень конкуренции поисковых запросов. Значит, по ним рекламируется большее количество рекламодателей.
Оценка сезонности запросов
Если вы работаете с сезонным спросом, важно знать, какую семантику когда использовать.
Инструмент «Сезонность» находится здесь:
Нажмите «Дополнительная статистика», и вы увидите график с данными по частоте использования запроса по вертикали и временной разбивкой по горизонтали:
Для удобства его можно скачать себе на компьютер в csv:
Кластеризация (группировка) запросов
Когда семантика готова и очищена от минус-слов и прочего «мусора», стоит разбить связанные между собой ключи на группы. Чтобы писать объявления не под каждый ключ – а их могут быть тысячи и сотни тысяч, – а для групп.
Key Collector предлагает свой способ группировки, который можно настроить в меню «Анализ групп». Сгруппировать запросы можно, например, по поисковой выдаче, если вы предварительно рассчитали конкурентность запросов с помощью функции KEI.

Процесс группировки может занять до часа. Результаты также можно выгрузить в отдельном файле.
Создание структуры
Результаты группировки могут быть перенесены в проект через создание структуры.
Шаг 1. Нажмите кнопку «Создать структуру» на панели инструментов. Откроется окно параметров выполнения операции.
Шаг 2. Структура может быть создана для помеченных или выделенных групп. Как правило, удобней работать с помеченными группами. находится справа от названия группы, помеченные группы подсвечиваются зеленым цветом (см. скриншот).
Не перепутайте колонку пометки групп и колонку группового статуса отметки фраз внутри группы!
Шаг 3. Выбранные на шаге 2 группы могут быть созданы на корневом уровне проекта или внутри активной группы. Выберите подходящий режим.
Шаг 4. Выберите тип операции: копирование или перенос. При переносе одна и та же фраза может быть перенесена только единожды, т.е. она не будет продублирована во все целевые группы.
Шаг 5. Выберите источник фраз: только отмеченные фразы или все фразы сформированной группы.
Шаг 6. Для достижения эффекта этот шаг нужно выполнять в самом начале перед вызовом инструмента создания структуры. По умолчанию группы создаются в проекте с автоматически сформированными заголовками, однако вы можете переопределить заголовок группы на свой более подходящий. Если несколько групп будут иметь одинаковый заголовок, то их фразы попадут в общую группу с определенным самостоятельно заголовком (дублирования групп не произойдет).
Выделение и отметка фраз
Большинство активных функций в программе выполняют операцию либо для выделенных, либо для отмеченных фраз. Выделение удобней использовать для мелких операций, а отметку — для сложных или комплексных процессов.
Выделение фраз выполнятся путем протяжки курсора с зажатой левой кнопкой мыши в области ячеек или зоны нумерации строк. Поддерживается использование выделения с Ctrl и Shift.
В отличие от обычного выделения статус отметки строк сохранятся в проекте и не меняется даже после перезапуска программы.
Например, вы можете продвигаться по таблице вниз, отмечать запросы, не рискуя при этом случайно сбросить выделение. Выделение запросов может использоваться как вспомогательный функционал (можно массово изменить статус отметки для выделенных фраз).
Сколько стоит Key Collector
Стоимость зависит от того, на каком количестве компьютеров или рабочих мест вам нужно установить и активировать программу.

Допустим, она нужна четырем сотрудникам. Вы покупаете 4 лицензии: первая обходится в 1 800 рублей (при электронном расчете), вторая, третья и четвертая – уже по 1 400 каждая.
P.S. В этой статье мы затронули только те функции сервиса Key Collector, без которых не обойтись при настройке контекстной рекламы. Помимо комплексной работы с ключами Key Collector также работает с содержимым сайта, проводит экспресс-анализ на соответствие семантике и дает рекомендации по внутренней перелинковке.
Сбор семантики
Вот мы и перешли к самому вкусному. Собирать ключи можно из левой и правой колонок Вордстата. Как вы наверняка знаете, в левой показываются запросы с вхождением ключевого слова. В правой же – похожие запросы.

В этом материале мы рассмотрим именно сбор из левой колонки. Итак, нажимаем на красную иконку, после чего у нас открывается такое окно.
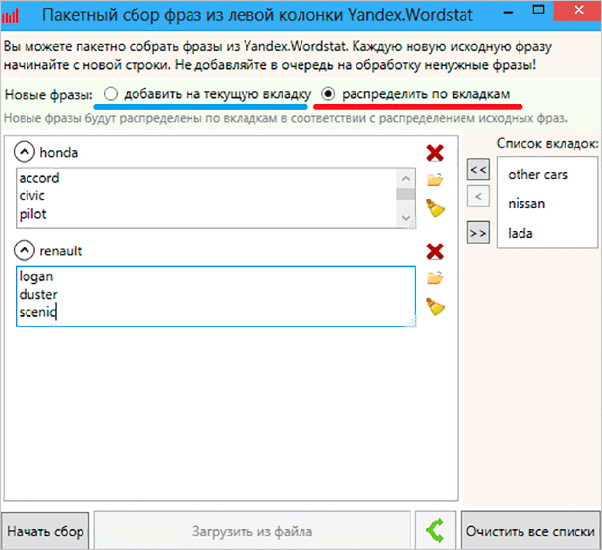
Здесь мы можем ввести все ключевые слова, которые нам нужны. Их можно разбить на вкладки и группы. Ключи можно вводить вручную, а можно просто выгрузить из файла.
После нажатия кнопки “Начать сбор” программа начнет свою работу. В зависимости от настроек и количества ключей этот процесс может занять определенное время. Иногда и по несколько часов. В конечном итоге вы получите список всех ключевых слов и фраз из левой колонки Вордстата.
Далее мы можем снять более точную частотность, потому как та, что будет доступна сразу после сбора, – ложная. Не стоит ей доверять и уж тем более делать какие-то выводы.
При сборе из правой колонки порядок действий тот же самый. Только ключей получится больше, в силу того, что в таблицу попадут все “похожие”.
Частотность
После сбора самой семантики, вы можете собрать частотность. Причем базовая частотность не даст нам особо полезной информации, поэтому нас интересует частотности с вхождением конкретных слов (“ “) и с точным вхождением (“!”)
Для сбора всех видов частотностей мы можем использовать одну кнопку.

Съем более точных частотностей позволит вам получить наиболее правильные статистические данные о количестве запросов в Яндексе. Базовая вариация не отражает истинную суть, и чаще всего при составлении семантического ядра она игнорируется.
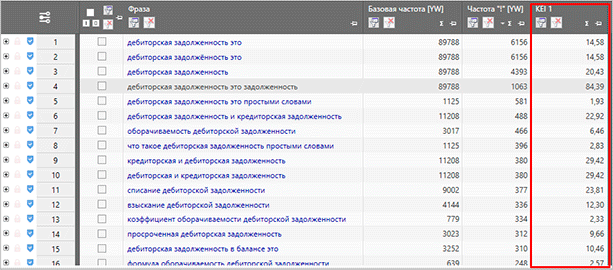
Именно сбор частотности в конечном итоге позволяет вам кластеризовать семантическое ядро по запросам: ВЧ, СЧ и НЧ. Исходя из этих данных, сеошники могут разделять ключи по группам, создавая для каждой отдельной статьи свою небольшую базу из тайтла и нескольких ключевых слов. Далее эта информация передается копирайтерам для написания статей. Сейчас такой способ является наиболее популярным при работе с информационными сайтами.
Сезонность
Сезонные запросы – это ключи, которые актуальны в какое-то время года или в какое-то конкретное время. Если вы собираете семантику для магазина с пляжными товарами, то вам нужно брать в расчет наибольший спрос, а именно в летнее время.
Сбор сезонности позволит вам определить, какие запросы в какое время пользуются наибольшей популярностью. Чтобы собрать эту информацию с помощью Кей Коллектора, найдите в меню иконок кнопку “Сбор ключевых слов и статистики”.
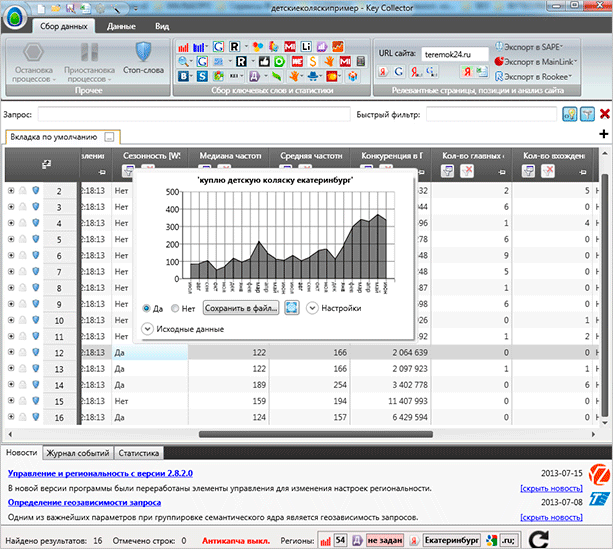
После завершения процесса на примере графика вы сможете увидеть популярность того или иного запроса в какой-то конкретный месяц.

Вы можете получить данные по неделям, а не по месяцам, как это представлено на скриншоте. Для настройки используйте все ту же кнопку “Сбор ключевых слов и статистики”, она раскрывается, там вы и найдете соответствующий пункт.
При необходимости вы можете посмотреть более подробную информацию. Для этого просто кликните на нужной ячейке.