Пошаговая инструкция по сбору семантического ядра
Содержание:
- Распределение семантического ядра: внешняя оптимизация сайта
- Облако запросов — расширение семантического ядра
- Немного теории
- Методика сравнения
- Планировщик ключевых слов Google
- Генерация рекламных текстов для групп объявлений
- Как группировать запросы
- Кластеризовали семантику — что дальше?
- Кластеризация в Rush Analytics
- Очистка семантики от мусора и поиск минус-слов
- Группировка запросов по типу страниц
- Когда нужна группировка ключевых фраз
- Как это работает?
- SpyWords
- Методы кластеризации
- Группировка методом Альфа/Бета
- Зачем делать кластеризацию?
- Just-Magic
- Кластеризация ключевых слов сайта
- Зачем нужны сервисы кластеризации?
Распределение семантического ядра: внешняя оптимизация сайта
Теперь кластеры нужно проанализировать и распределить по посадочным (целевым) страницам вашего сайта. Если есть похожие по смыслу кластеры — не нужно создавать под них отдельные страницы и тем самым плодить дублированный контент. Отбираем из них самый частотный кластер и его используем. Не пытайтесь также распределить на одной странице сразу несколько кластеров — это не приведет к успеху, придерживайтесь структуры и правила: каждый кластер = отдельному URL на сайте.
Когда вы уже определились с URL-страниц для своих кластеров, нужно подготовить техническое задание, чтобы распределить ключевые слова с точки зрения SEO-оптимизации. Переходим в инструмент Текстовый Анализатор SEO и создаем в нем под каждый кластер отдельный проект. Добавляем ключевые слова и запускаем проект. Текстовый Анализатор проанализирует тексты сайтов-конкурентов из выдачи ТОПа и сгенерирует ТЗ, которые дальше вы можете отправить копирайтеру.
Отдельно про функционал Текстовый Анализатор мы рассказывали в предыдущих материалах:
- Базовое руководство по Текстовому Анализатору
- Статья «Работаем с Текстовым Анализатором»
- Видеоруководство по Текстовому Анализатору
- Вебинар по Текстовому Анализатору
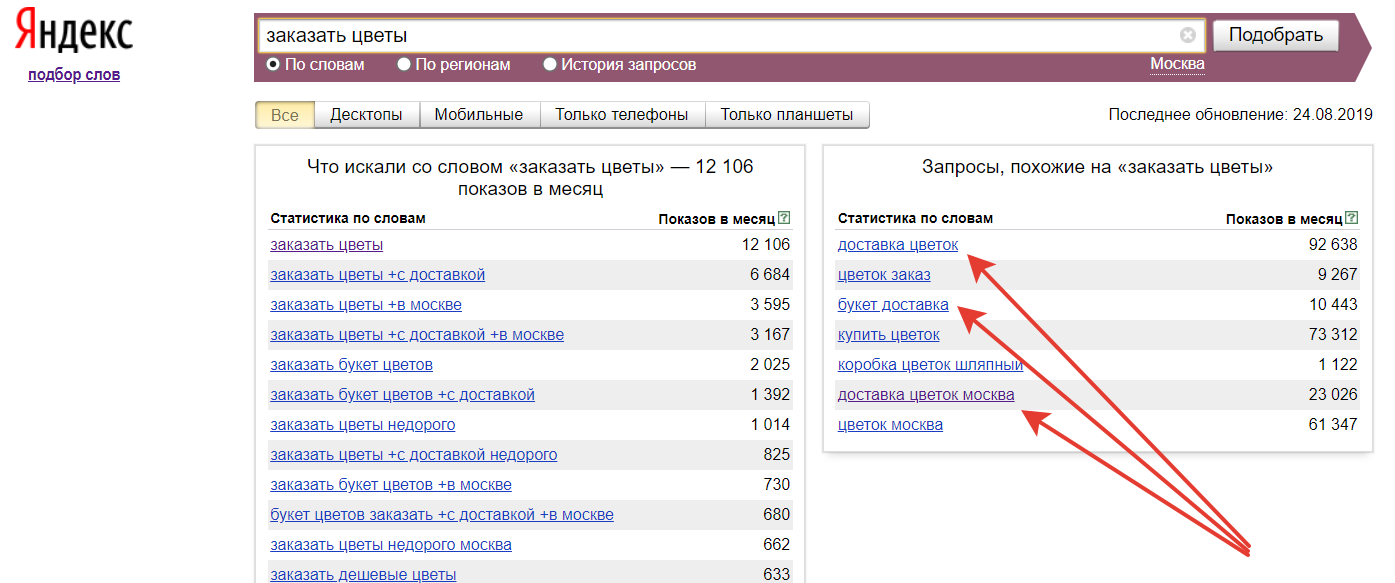
Облако запросов — расширение семантического ядра
Облако запросов — это все ключевые слова, полученные парсингом поисковых подсказок и Яндекс Wordstat по маркерным запросам.
По нашему опыту эффективнее всего получать расширения запросов из поисковых подсказок Яндекса + поисковые подсказки Google и левой колонки Яндекс Wordstat.
Почему?
Не потому, что в Rush Analytics есть парсинг только Яндекс Wordstat и поисковых подсказок 🙂
Потому, что эти источники семантики: а) Обладают максимальной полнотой б) Подсказки изначально трастовый источник семантики т.к. сам Яндекс исправляет орфографию и добавляет в подсказки ТОЛЬКО реальные запросы пользователей. Что нам и нужно.
Часто задаваемые вопросы по сбору облака запросов
Q: У меня есть база Пастухова, есть аккаунт в SeoPult и Sape — там тоже есть ключевые слова — чем они плохи?
A: Если говорить о готовых базах данных (например, База Пастухова), то плохи они вот чем а) непонятно откуда взяты эти запросы — реальные ли это запросы или же это «кривые» запросы горе-оптимизаторов б) Большинство запросов в готовых базах данных банального сгенерированы или уже потеряли актуальность.
SeoPult и Sape можно использовать, чтобы прикинуть свои маркеры — иногда там можно найти интересные ключевые слова
Таким образом, проще собрать свежие и актуальные ключевые слова для своей тематики, чем «копаться в мусоре».
Поверьте — все пригодные запросы этих баз данных есть в Яндекс Wordstat и поисковых подсказках. Мы проверяли.
Итак — у нас есть 2 потенциальных источника семантики — Яндекс Wordstat и поисковые подсказки.
Формируем финальное облако запросов:
Финальное облако запросов будет включать в себя:
а) Ключевые слова, собранные с левой колонки Wordstat
б) Ключевые слова, полученные из поисковых подсказок
Т.е. вам нужно объединить 2 массива данных (2 файла), которые мы получили из поисковых подсказок и из Яндекс Wordstat.Не забудьте проверить частотность собранных подсказок по Wordstat — это пригодится вам в дальнейшей работе.
Здесь вы должны иметь от нескольких тысяч до нескольких сотен тысяч целевых ключевых слов + знать их частотность по Wordstat. Уже на данном этапе понятно, что собранная база ключевых слов в 10-50 раз превышает то, что имеют конкуренты 🙂
Немного теории
Вебмастера используют два принципиально разных подхода к кластеризации:
- По составу ключевых фраз. Запросы объединяют в группы на основе анализа входящих в них слов.
- По поисковой выдаче. Для каждого запроса находят ТОП выдачи и устанавливают порог совпадения – например, 50%. Те ключи, по которым в ТОП выдачи совпадет хотя бы половина страниц, объединяют в одну группу. Порог совпадения можно взять любой, анализировать можно любое количество результатов выдачи: ТОП-3, ТОП-5, ТОП-10, ТОП-20.
Второй метод кластеризации – на основе анализа выдачи – более популярен, чем первый:
Первые 6 сайтов считают кластеризацию синонимом группировки на основе поисковой выдачи. У 4 сайтов это видно уже в сниппете, оставшиеся (2-й и 6-й) пишут об этом на страницах.
Что выбрать?
Сторонники группировки ключей по поисковой выдаче игнорируют две вещи.
Во-первых, у каждой поисковой системы свои алгоритмы ранжирования. Посмотрите, как выглядит поисковая выдача для фразы «что такое кластеризация запросов» для пользователей Яндекса из Москвы:
Сравним ее с выдачей Google, приведенной ранее.
Кластеризация запросов по ТОП выдачи означает, что мы сосредоточимся на продвижении сайта только в одной поисковой системе.
Во-вторых, в ТОПе появляются новые сайты и поисковая выдача меняется. Следовательно, через небольшое время кластеризация перестанет соответствовать ТОПу выдачи и нам придется по-новому группировать ключи и переписывать контент на сайте.
Кластеризация запросов по составу фраз решает обе проблемы.
Методика сравнения
Суть сравнения сервисов в следующем: выбрать идеально кластеризованный список запросов – эталонное ядро. Сравнить результаты кластеризации каждого сервиса с эталонным.
Важно было хорошо составить такое эталонное ядро. Поскольку у нас контентный проект и большая часть контента – это вопросы и ответы пользователей, то материала для сбора статистики по проекту предостаточно
Было взято ядро на 2500+ ключевых фраз, которое отслеживается уже много месяцев. Из него выбраны только запросы вышедшие в топ-5 Яндекса. И из них взяты только те которые имеют релевантной страницу одного из широких разделов (категория вопроса, тема вопроса, категория документа, страница с формой «задать вопрос»), а не узкую страницу вопроса с ответами. Запросы были сгруппированы по релевантной странице. Оставлены только группы в которых более чем 4 запроса. В итоге получилось 292 запроса разбитых на 22 кластера.
Забегая вперед скажу, что сравнивались результаты кластеризации по Московской выдаче Яндекса и без геопривязки. Региональная московская выдача показала себя лучше, поэтому далее будем говорить про нее.
Планировщик ключевых слов Google
Для создания эффективного рекламного объявления очень важно подобрать ключевые слова, которые привлекут внимание целевой аудитории. Компанией Google реализован простой инструмент создания рекламных кампаний в поисковой сети – эффективный планировщик ключевых слов
Возможности планировщика ключевых слов Google:
- Подбор ключевых слов и словосочетаний для определения наиболее подходящих вариантов;
- Оценка предполагаемой эффективности перечня ключевых слов;
- Определение бюджета рекламной кампании на базе расчётных ставок для каждого ключевого слова;
- Формирование рекламного плана;
- Формирование статистики по трафику, а также прогнозов по трафику.
Стоимость: сервис бесплатный.
Генерация рекламных текстов для групп объявлений
Когда мы подготовили документ со структурой, время писать тексты. Мы по умолчанию генерим варианты текстов объявлений под Google и Яндекс, они будут находиться на отдельных вкладках в XLSX-файле с результатом.
-
Переходим в сервис «Генерации текстов», выбираем файл, нажимаем «Отправить в Пекло».
Вы попадете на блок настройки генерации рекламных текстов:
-
Выбираем количество текстов на группу объявлений. Минимально рекомендуем добавлять два варианта, чтобы Google Ads и Яндекс.Директ могли тестировать разные версии объявлений внутри одной группы и выбирать лучшую. Это необходимо для качественной рекламной кампании.
-
Изучите детальные настройки. По умолчанию заданы логичные настройки, однако вы можете настраивать инструмент под себя.
Всегда и по умолчанию для Заголовка 1 в тексте объявлений используется ваше ключевое слово. Это необходимо для получения высокого CTR.
Также существует поверье, что если в заголовке каждое слово писать с заглавной буквы, то CTR будет выше — тестируйте.
Есть несколько вариантов, как поступать, если ваше ключевое слово не помещается в Заголовок 1. Мы советуем переносить ваш ключ в Заголовок 2 (если фраза заканчивается «… в Москве», то перенос будет вместе с предлогом) и позже уже вручную допиливать тексты объявлений по ситуации.
Если вы указываете частотность ключевых слов, то для Заголовка 1 алгоритм подберет самое высокочастотное слово. Как правило, они самые корректные и без ошибок. Так, тексты сгенерируются качественнее.
-
Настраиваем Заголовок 2. Логика простая: сколько текстов на группу объявлений вы настраиваете, столько вторых заголовков и задавайте. Здесь можно отобразить либо самое сильное УТП, либо бренд или слоган компании.
-
Настраиваем Заголовок 3 для Google Ads. Так как Заголовок 3 не всегда отображается, вводите сюда менее важные варианты текстов — смысл объявления не должен теряться, если этот заголовок не покажется.
-
Настраиваем Описания для текстов объявлений. Это важный момент в создании текстов объявлений. Лучше задать 7–9 вариантов УТП. Чем больше вариантов разной длины, тем лучше наш алгоритм сможет их сочетать и адаптировать под ограничения рекламных систем по символам.
Не указывайте 2–4 варианта УТП с длиной ≈80 символов: система не сможет их комбинировать и сгенерировать тексты. Если у вас есть готовое описание, лучше вставьте его в финальном документе в Excel.
-
Добавьте варианты призывов к действию. Основа Описания для объявлений — это предыдущий блок с УТП. Призывы к действию добавляются в конце объявления после УТП. Добавляйте несколько вариантов разной длины. Но именно призывы к действию рекомендуем делать максимально краткими.
-
Задаем URL сайта. Здесь просто вставляйте ссылку, которая будет вести на главную страницу.
В будущем мы планируем сделать инструмент для автоматической настройки отображаемых URL и для подбора финальных URL, если у вас многостраничный сайт. Благодаря этому разные группы объявлений будут вести на разные страницы.
-
Отправляем в Peklo и смотрим на результат.
Результат будет выглядеть примерно так:
На листе PekloTool Data будут собраны все введенные тексты для заголовков, описания, призывы и т. д. На отдельных листах — Google и Yandex — тексты, соответствующим требованиям рекламных систем.
Что нужно сделать, чтобы доработать получившиеся тексты:
-
Найти слова на кириллице и заменить их написание латиницей. Например, найти «бмв» и заменить на BMW.
-
Если часть ключевого слова попала в Заголовок 2 и он получился коротким, можно через формулу =ячейка&» добавочный текст» дополнить этот заголовок и протянуть по всем таким заголовкам. Пример:
-
Текст в Заголовках 1, которые не выглядят привлекательно, заменить на дефолтный текст или отредактировать.
После доработок рекламная кампания будет готова к загрузке в аккаунты. Для этого понадобятся программы Google Ads Editor и Директ Коммандер.
Как группировать запросы
Чтобы понять, как распределять ключевые слова по отдельным страницам, нужно сгруппировать запросы. Для этого надо создать семантические кластеры.
Чаще всего, ключевые слова из кластеров первого и второго уровней определяются еще на этапе мозгового штурма. Для этого просто нужно хорошо разбираться в своем продукте или ориентироваться на структуру сайтов-конкурентов. Семантика остальных подуровней определяется на этапе детального составления семантического ядра и его кластеризации
Еще одно важное условие — каждая группа запросов последнего уровня должна соответствовать одной потребности пользователя. Например, покупка конкретного вида детского белья
Используем Словоёб с уже известной нам функцией быстрого фильтра. С его помощью можно легко отсортировать фразы по категориям для дальнейшего внедрения на посадочных страницах.
1. Введите в поле быстрого фильтра базовое ключевое слово, которое может станет названием для категории/подкатегории/посадочной страницы (например, бренд детского постельного белья «Непоседа») и нажмите Enter.
2. Выделите нужные фразы и скопируйте их.
3. Удалите отмеченные строки правой кнопкой мыши.
4. Создайте в правом меню новую группу (например, с названием «Непоседы»).
5. Для добавления только что выбранных фраз в эту группу, перейдите во вкладку «Данные» — «Добавить фразы».
6. Вернитесь к прежнему списку нажатием клавиши Enter в поле поиска быстрого фильтра.
7. Повторите эту процедуру с другими запросами. Ключевые фразы автоматически выстроятся в алфавитном порядке, благодаря чему можно легко удалить лишние слова или выделить похожие фразы в отдельную группу.
Группировка вручную требует много времени (особенно в том случае, если семантика достаточно широкая). Для автоматизации этого процесса можно использовать платные Key Collector, Rush-Analytics, Just-Magic, или бесплатный скрипт Devaka.ru. Часто приходится объединять некоторые группы запросов. Например, такие:
Согласитесь, создавать две отдельные категории под фразы «красивое белье» и «стильное белье» неразумно 🙂 Для понимания важности фраз для каждой категории/посадочной страницы, скопируйте их в Планировщик ключевых слов Google в раздел «Получение статистики запросов и трендов»:
Так вы проверяете популярность (частотность) поискового запроса. В целом все поисковые запросы делятся на:
- ВЧ-запросы (высокочастотные).
- СЧ-запросы (среднечастотные).
- НЧ-запросы (низкочастотные).
- Микро НЧ-запросы.
При этом нет точных цифр, по которым можно с уверенностью сказать, что запрос принадлежит к определенной группе. Все зависит от тематики сайта. В одних тематиках фраза с частотностью 1000 запросов в месяц может быть низкочастотной (фильмы, музыка), в других — 200 запросов уже может быть признаком высокочастотной фразы (финансовая тематика). Соотношение этих групп: Наиболее высокочастотные запросы впоследствии вписывайте в метатеги. А под низкочастотные оптимизируйте страницы сайта. Как правило, они очень низкоконкурентны, и достаточно провести качественную работу с текстами, чтобы вывести соответствующие страницы в ТОП.
Читайте, как привлечь целевой трафик на сайт с помощью формирования максимально широкого семантического ядра.
После всех этих манипуляций вы получите подробную структуру сайта, состоящую из ключевых фраз для:
Кластеризовали семантику — что дальше?
Важно понимать, что ни один сервис кластеризации не обеспечит идеального результата. Необходимо анализировать полученные кластеры, экспериментировать с точностью кластеризации, удалять некоторые фразы, проверять посадочные URL
Тем не менее без автоматизации процесс группировки ядра затянется на дни или даже недели, и полученный результат не позволит учесть особенности поисковых алгоритмов.
Инструмент кластеризации от PromoPult — это отличное подспорье для вебмастеров и оптимизаторов, особенно с учетом цены, которая в 3-5 раз ниже, чем у конкурентов. Также вы можете бесплатно попробовать инструмент в действии, доступно 100 запросов.
Кластеризация в Rush Analytics
У нас есть модуль кластеризации и 3 типа кластеризации:
По Wordstat. Самый простой и менее затратный по времени с точки зрения оптимизатора метод. Идеально подойдет для ситуаций, когда мы не знаем о структуре сайта практически ничего.
1) В Excel загружаете в одну колонку ключевые слова, в другую — частотность по Wordstat, и отправляете на кластеризацию.
2) Мы сортируем весь список по убыванию: наверху получаются самые частотные слова (обычно самые короткие).
3) Алгоритм работает так: мы берем первое слово, пробуем привязать к нему все остальные слова, группируем. Все, что привязалось, вырезаем, делаем сортировку заново и опять повторяем эту итерацию.
4) Из списка ключевых слов мы получаем набор кластеров.
По маркерам
1) Мы знаем маркерный запрос (основной запрос страницы или несколько запросов, под которые она продвигается).
2) Мы берем список ключевых слов, в колонке справа единицами отмечаем маркерные запросы, и нулями — все остальные запросы.
3) Мы берем маркерное ключевое слово и пытаемся привязать к нему остальные ключевые слова и сгруппировать в кластеры
Здесь важно, что в этом алгоритме маркерные слова, которые мы пометили единичками, никогда не будут связаны между собой. Мы не будем пытаться их привязать
Комбинированная кластеризация
Этот алгоритм совмещает в себе два предыдущих
1) Мы загружаем ключевые слова, отмечаем «маркер/не маркер» и частотность.
2) Привязываем к маркерным запросам все слова, которые мы можем привязать.
3) Берем ключевые слова, которые остались не привязанными, и группируем их между собой по Wordstat.
4) Все остальное откинется в «некластеризованные».
5) В итоге — структура, которую мы уже знаем. Также получится автоматическая кластеризация всех остальных ключевых слов, что поможет нам расширить структуру. Все эти типы кластеризации есть в Rush Analytics.
Какие еще есть инструменты на рынке?
Из достойных, кроме Rush Analytics, можно выделить сервис JustMagic, где есть и Hard и Soft кластеризация. Сервис разработал Алексей Чекушин.
Это все, что вам нужно знать о кластеризации, чтобы начать работу по группировке ключевых слов.
Используйте кластеризацию и экономьте свое время. К тому же, люди часто ошибаются, процент ошибок оптимизатора — порядка 15%. Доверьте рутину роботам — не нужно разбирать это руками.
Хорошие статьи в продолжение:
— Как сделать семантическое ядро сайта — пошаговое руководство
— Подбор ключевых слов для англоязычного сайта — пошаговое руководство
Очистка семантики от мусора и поиск минус-слов
Это отдельный инструмент, который помогает очистить первичный список ключевых слов и сразу получить список минус-слов для рекламной кампании.
Внимание: инструмент работает только для зарегистрированных пользователей. Он простой и быстрый:
Он простой и быстрый:
-
Вставляем весь список ключевых слов и нажимаем «Начать работу».
-
У вас появляется рабочая область, где вы, кликая по нерелевантным словам, выделяете все фразы с ними, слева автоматически будет создаваться список минус-слов.
-
После нажатия на кнопку «Получить список рабочих слов» система выведет все слова за исключением тех, что содержат в себе минус-слова.
В итоге вы можете быстро очистить свои ключевые слова от мусора, скопировать очищенный список в рабочий документ и перейти к группировке ключевых слов. А собранные минус-слова позже добавить в качестве минус-слов на уровне кампании, группы объявлений или аккаунта.
Также есть удобная функция «Найти словоформы выбранных слов». C ее помощью в загруженной семантике можно найти выбранные минус-слова в других падежах, множественном и единственном числах
Для Google Ads важно прописывать минус-слова во всех числах и склонениях
Группировка запросов по типу страниц
Основные типы страниц:
- главная — слова и фразы, которые в целом дают характеристику сайту, например: клиника пластической хирургии Киев;
- категории/подкатегории товаров и услуг — общие запросы под товары и услуги, например: липофилинг цена, липосакция киев;
- карточки товаров/услуг — группировка запросов, соответствующих конкретному товару или услуге, например: липофилинг губ, липофилинг слезных борозд;
- информационные страницы (блог/статьи) — страницы, которые будут отвечать на конкретный информационный запрос, например: что нельзя делать после инъекций ботокса;
- другие страницы сайта.
Когда нужна группировка ключевых фраз
Главная причина для группировки, которая влияет на результат — это достижение максимальной релевантности.Другая причина, косвенно влияющая на результаты — это гибкое и удобное управление аккаунтом.
Собственно, в процессе группировки мы решаем, какие фразы объединять в одну группу, а какие оставлять в разных.
Оговорюсь, что мы сейчас говорим о группировке внутри одной кампании. Распределяйте фразы по разным кампаниям с отдельными бюджетами и KPI, если у вас разные:
- категории или подкатегории товаров;
- бизнес-направления;
- регионы таргетинга;
- языки;
- массивы фраз с явно отличающимся перформансом (например, коммерческие и информационные запросы).
Зачем объединять фразы в группы:
- для назначения общих ставок;
- для агрегации статистики;
- для донесения общих сообщений;
- для объединения общих интентов;
- для тестирования объявлений при помощи их ротации.
Соответственно, разделение по разным группам происходит по обратным причинам от тех, что перечислены в списке причин для объединения.
Зачем разделять фразы по разным группам:
- чтобы назначить свои ставки;
- чтобы разделить статистику;
- чтобы донести разные сообщения;
- для разных интентов;
- чтобы разделить аудиторию для показа разными списками ремаркетинга.
Напомню, что под интентом мы подразумеваем и товар/услугу, которая нужна пользователю.
Поэтому, например, дом из сруба и дом из сендвич-панелей — это решения для разных интентов, а значит, и групп.
Давайте подробнее остановимся на причинах объединения и распределения по группам, а именно на агрегации/разделении статистики и назначении общих/разных ставок.
Зачем агрегировать или разделять статистику
Мы не можем достоверно оценивать ключевые фразы или объявления по недостаточному количеству наблюдений (кликов).
Когда данных на уровне ключевых фраз мало, переход на уровень выше (на уровень группы), позволяет принимать статистически более достоверные результаты. На основании этих данных мы принимаем решения о дальнейшей судьбе сущностей, прогнозируем результаты, назначаем ставки исходя из этих результатов.
Но объединять статистику также нужно с учетом схожести интента и перформанса: в целом не стоит прогнозировать конверсию и назначать ставку на платья, ориентируясь на статистику конверсионности курток.
Ключевая фраза (и запрос, по которому она сработала) квартиры Харьков: CR 1% при CPC 1 грн, 300 кликов.
Ключевая фраза аренда квартир долгосрочно Харьков: CR 4% при CPC 2 грн, 200 кликов.
Ключевая фраза купить квартиру Харьков: CR 2% при CPC 3 грн, 300 кликов.
Средний CR — 2,1%, CPC — 2 грн.
Очевидно, что это разные по намерению запросы, пути совершения покупки (или аренды), а у нас на сайте может быть хороший выбор в одной категории и плохой в другой. Поэтому статистику по аренде и продаже стоит разделить.
Конечно, за недостатком данных лучше хоть какая-то статистика, чем ее отсутствие. Поэтому применяются разные статистические методы прогнозирования.
Это отдельная даже не тема, а область знаний. Наиболее полно в сфере контекстной рекламе она раскрыта в этих материалах:
Зачем назначать ставки для разных групп
Момент очевидный, но все-таки. Так как ключевые слова объединены в группы согласно некоторым общим свойствам, то эти группы будут показывать свой перформанс. То есть разные коэффициент конверсии, цену клика на аукционе и все остальное. Соответственно, следует задать разные ценность клика и ставки, необходимые для занятия нужной позиции.
Как это работает?
Сервис в режиме онлайн производит сканирование результатов выдачи в выбранной поисковой системе, определяет, по каким запросам находятся одинаковые URL-адреса. В методе «Пиксель Тулс» — дополнительно исключает из анализа ресурсы, которые, скорее всего, не соответствуют вашему сайту и ранжируются не по общей формуле релевантности, будут исключены и результаты, найденные с помощью алгоритма «Спектр».
Время обработки зависит от количества поисковых запросов, но в целом, результат получается довольно быстро.
При скачивании в предложенном названии файла указывается метод обработки, сила группировки и дата.
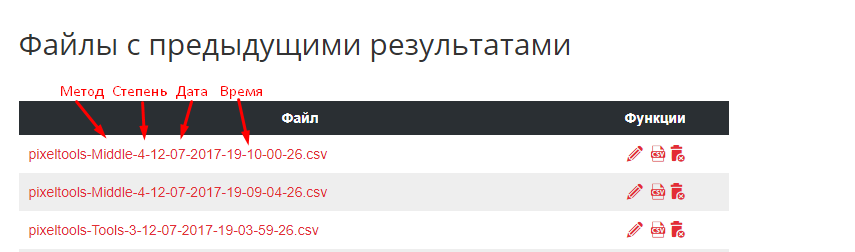
В файле результатов доступна нумерация фраз в той очередности, в которой они были добавлены, что позволяет в любой момент отсортировать файл как в исходном варианте.
Также в нем присутствуют столбцы «Группа» и «Релевантный URL на сайте». Релевантный документ определяется даже в случаях, когда сайт находится за пределами ТОП-100 результатов выдачи, и он часто является оптимальной посадочной страницей для данной группы.
Дополнительно выводится количество главных страниц в выдаче Яндекса или Google, что позволяет понять, какую страницу лучше продвигать. Если по большому количеству разных запросов много главных страниц в выдаче, то для оптимального продвижения рекомендуется создавать поддомены.

Еще один столбец — текущая позиция вашего сайта, которая показывает, насколько осмысленно менять релевантную страницу по данному поисковому запросу. Если сайт уже в ТОП-3, то понятно, что менять стратегию продвижения на текущий момент нет необходимости.

Столбец «Количество запросов в группе» позволяет быстро понять, какие группы требуется дополнительно разбить, а какие — наоборот, объединить.
Путем простого форматирования в Excel можно преобразовать файл в таблицу и отсортировать по любым интересующим нас свойствам: релевантному URL, количеству главных страниц либо по количеству запросов в группе.
Это позволяет довольно быстро понять, как классифицировать запросы. Например, если два запроса ассоциированы в одну группу, при этом у них разные релевантные страницы и по ним обоим по 9 или даже 10 из 10 главных страниц в выдаче, соответственно, по обоим запросам желательно продвигать именно главную.
С помощью этого инструмента файл оптимального распределения по посадочным страницам формируется буквально в несколько кликов.
SpyWords
Сервис SpyWords позволяет определить нишу своего сайта, подобрать нужные ключевые слова, а также отслеживать показатели конкурентов.
Возможности SpyWords:
- Определение перспективных продуктов и ниш для запуска рекламы;
- Определение перечня конкурентов по конкретному запросу;
- Анализ конкурентов по контексту и поиску;
- Определение списка ключевых слов конкурентов;
- Просмотр преимуществ, которые конкуренты указывают в рекламе;
- Получение семантического ядра по заданному ключевому слову;
- Получение семантического ядра конкурентов.
Тарифы:
|
Период |
Business |
PRO |
Unlim |
|
12 месяцев (3 бесплатных месяца) |
312 долларов |
387 долларов |
780 долларов |
|
6 месяцев (1 бесплатный месяц) |
173 доллара |
215 долларов |
434 доллара |
|
1 месяц |
35 долларов |
43 доллара |
87 долларов |
|
1 сутки |
7 долларов |
9 долларов |
18 долларов |
Методы кластеризации
Кластеризация запросов производится по SERP (search engine results page) – странице результатов поиска.
Есть два метода кластеризации:
- Soft-кластеризация – это попарное сравнение выдачи по всем запросам. Запросы объединяются в кластер, если получается заданное количество одинаковых результатов.
- Hard-кластеризация – более сложное сравнение результатов поиска. Выдача сравнивается не только попарно, но и между всеми запросами внутри кластера. Объединение в группы происходит при таком же условии.
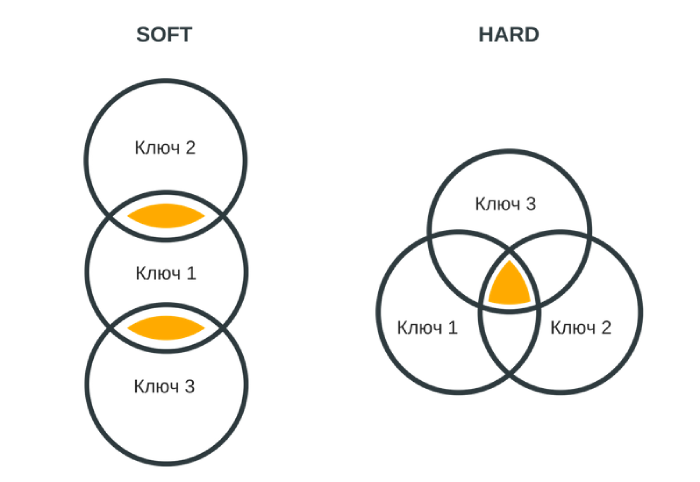 Схемы этих двух методов кластеризации запросов
Схемы этих двух методов кластеризации запросов
После soft-кластеризации получается слишком широкая семантика, включающая множество нетематических запросов. В итоге такое семантическое ядро нужно дольше чистить и приводить в порядок. Hard-кластеризация же дает более точный результат.
Группировка методом Альфа/Бета
Разновидность SKAG-группировки, которую разработал и описал в своей книге «Контекстная реклама, которая работает» ведущий мировой эксперт по Google Ads Перри Маршалл. Она заключается в том, что из работающей бета-кампании выбираем фразы, которые принесли больше всего конверсий, и переносим их в точном соответствии в новую альфа-кампанию. В бета-кампании такие ключи заносим в список минус-слов.
Далее мы делаем это регулярно — выбираем наиболее эффективные ключи из старой кампании и в точном соответствии переносим в новую.
Мы создали 10 групп объявлений, в каждой из которых — один ключ в точном соответствии
Когда применять
Способ подходит для сложных ниш, когда важно искать пути наращивания конверсий при оптимальных расходах. Плюсы:
Плюсы:
- Постоянно пополняя альфа-кампанию высокоэффективными фразами, мы наращиваем общее количество конверсий.
- Выделяя больший бюджет на альфа-кампанию с конверсионными фразами, мы можем максимизировать результат.
Минусы:
- Фраза, которая показала хороший коэффициент конверсии в бета-кампании, может «просесть» в альфа-кампании. С увеличением бюджета и количества кликов коэффициент конверсий может снизиться.
- Нужно регулярно переносить конверсионные фразы в альфа-кампанию и делать минусовку в бета-кампании. При большом количестве ключей это трудоемко.
Зачем делать кластеризацию?
Почему тренд кластеризации на рынке уже около полутора лет? Почему это важно и как это поможет?
Экономия времени. Кластеризация — замечательная технология, которая поможет сократить рутину при работе с группировкой семантического ядра. Если обычный специалист по семантическому ядру разбирает 100 000 ключевых слов, отделяя их на группы, порядка 2-3 недель (а то и больше, если сложная семантика), то кластеризатор может это разделить в порядке очереди примерно за час.
Позволяет избежать ошибки продвигать разные запросы на одну страницу. В Яндексе есть классификаторы, которые оценивают коммерческие запросы. Например, выдача по информационным запросам и коммерческим — совершенно разная. Запросы «блеск для губ» и «купить блеск для губ» никогда не получится продвинуть на одну страницу.
1) По первому запросу («блеск для губ») стоят сайты информационной тематики (irecommend, Википедия). Под этот запрос нужна информационная страница.
То есть под разные запросы нужны разные типы страниц. Частая ошибка отимизатора — когда он продвигает все вместе на одну страницу. Получается так, что половина семантического ядра выходит в ТОП-10, а вторая половина никак не может туда попасть. Кластеризатор позволяет избежать таких ошибок.
Для того чтобы так не происходило, нужно изначально правильно сгруппировать запросы по типам страниц по выдаче.
Just-Magic
Сервис Just-Magic – это, прежде всего, автоматизация SEO для опытных сеошников.
Возможности Just-Magic:
- Работа с семантикой (подбор семантики для сайта, расширение семантического ядра, распределение запросов по сайту, подбор запросов на основании Яндекс Метрики и др.);
- Анализ текста и оптимизация страниц сайта по перечню запросов, а также распознавание всех вхождений, которые известны поисковой системе;
- Работа с небольшими текстовыми фрагментами и умение отличать фрагменты от больших текстов;
- Работа во всех зонах документа;
- Кластеризация запросов по нескольким порогам, по тематическим группам, а также применение кластеризации для текстового анализа;
- Пословный анализ теста на соответствие тематичности запроса;
- Формирование списка релевантных слов для нового текста.
Тарифы:
- Чатланин – 1 тыс. рублей в месяц;
- Эцилоп – 2,5 тыс. рублей в месяц (доступ к API);
- Жёлтые штаны – 5,0 тыс. рублей в месяц (доступ к API, многопользовательский режим);
- Малиновые штаны – 10,0 тысяч рублей в месяц (доступ к API, многопользовательский режим, ВИП-поддержка).
Кластеризация ключевых слов сайта
Именно последний шаг в создании семантического ядра вызывает много вопросов. Дело в том, что первые этапы (кроме первого) более менее автоматизированы. Не нужно много усилий, чтобы провести сбор запросов и сделать их анализ. А вот этап группировки ключевых слов требует от веб-мастера максимум временных и умственных затрат. Поэтому и возникают различные ошибки. Наша с Вами задача — их не допустить!
Что такое группировка ключевых слов
Группировка (или кластеризация) ключевых слов — это процесс распределения поисковых запросов одной тематики (группа запросов) для продвижения одной страницы. Почему одной? Ответ Вы найдете в моем практическом мануале о каннибализации поисковых фраз.
Другими словами, с помощью этого этапа найденные словосочетания формируем в отдельные смысловые группы. Каждая группа внедряется только на свою продвигаемую страницу и решает одну задачу (общую для всех запросов этой группы):
Таким образом, все запросы группы соответствуют главной теме конкретной целевой страницы. Все они раскрывают цель конкретного документа сайта с той или иной стороны.
Более детально о понятии кластеризации семантического ядра Вы можете изучить в этом посте. В нем Вы найдете историю появления этого вида seo-работы, увидите наглядный пример по группировке запросов.
Еще под кластеризацией поисковых запросов понимается автоматизированный сбор фраз путем взаимодействия сервиса со страницами в поисковых выдачах. Об этом я подробнее расскажу, когда речь пойдет об одноименной услуге Топвизора.
Что дает грамотная кластеризация ключей для сайта
- видение будущей полноценной структуры нового сайта (или старого);
- путеводитель по темам, которые интересны пользователям из поиска;
- понимание текущего спроса на товары/услуги в конкретной нише;
- план seo-продвижения (какой контент формировать в первую очередь);
- для проведения правильной перелинковки веб-ресурса;
- для формирования длинного хвоста поисковых запросов;
- материал, из которого видны запросы для оптимизации страницы.
Поясню один важный момент. Кластеризация в группы дает колоссальную возможность использовать все ресурсы для привлечения максимального поискового трафика! Не делая группировку поисковых запросов, мы тем самым отсекаем свой сайт от освящения тем, которые нужны пользователям из Яндекса и Гугла.
Об этом подробно можно прочитать в статье о создании современного МФА сайта (основана на докладе Алесандра Люстика, автора программы Key Collector).
Что сулит неправильное распределение ключевиков
Итак, не имея распределенных групп по большой теме, владелец веб-ресурса не видит полноту всей картины продвижения. Это самая большая проблема, которая возникает при игнорировании этапа кластеризации (или ее неполноценного совершения).
Но даже наличие этого шага в Вашем плане продвижения не может гарантировать Вам достижения всех назначенных seo-задач. Это может произойти из-за ошибок, которые возникают при группировке запросов на целевые страницы. Вот проблемы, которые дает неправильное распределение ключевых слов:
- появление дублей в индексах поисковых систем (за счет каннибализации);
- потеря или не получение мест в первой десятке поисковой выдачи;
- потеря денег, затраченных на формирование «лишнего» контента;
- ухудшение поведенческих факторов, не достижение поставленных целей.
Как говорил один известный киношный персонаж «Картина маслом». По-другому тут и не скажешь. В современном поисковом продвижении нельзя делать «чуть-чуть» или оставлять что-то на потом. Все нужно выполнять вовремя и со смыслом. Кластеризация семантического ядра — это тот этап, после которого на скелет сайта нанизывается «мясо» (контент). И здесь любая ошибка превращает seo-раскрутку сайта в настоящий апокалипсис. Проблемы возникают там, где их не ждут.
Зачем нужны сервисы кластеризации?
В один кластер должны быть объединены только такие запросы, которые имеют хорошие шансы выйти в топ-10 поисковых систем с общей релевантной страницей. То есть, если по двум запросам в выдаче все страницы сайтов разные и нет пересечений, то следует относить их к разным кластерам. Также и наоборот: если два запроса возможно продвинуть на одной статье, то не следует разносить их на разные кластеры, чтобы не писать лишнего – бюджет на контент не резиновый.
Общая схема составления ТЗ на написание SEO-статьи следующая:
Сбор семантики – статистика поисковых систем, базы семантики, внутренняя статистика проекта;
Кластеризация автоматическая – сервис или программа для кластеризации по подобию топов;
«Посткластеризация» ручная – обработка того что не удалось кластеризовать автоматически;
Приоритезация – определение важности полученных запросов в каждом кластере;
Оформление ТЗ для копирайтера – лемматизация, LSI и различные указания для написания статей, по статье на каждый кластер.
Вот именно для второго пункта нужно было выбрать самый подходящий сервис автоматической кластеризации. Для этой цели я провел сравнительный анализ самых известных, на мой взгляд, сервисов.