40+ бесплатных сервисов и инструментов для работы с контекстной рекламой
Содержание:
- Программы для сбора семантического ядра
- Как создать семантическое ядро?
- 7Search
- Пошаговый алгоритм работы с сервисом:
- Yandex Wordstat Assistant
- Как правильно настроить Словоеб
- Виды семантических ядер
- Как пользоваться парсером Wordstat от Click.ru
- Сервисы для группировки ключевых слов
- Как группировать запросы
- Составление масок для парсинга
- Букварикс
- Ключевые идеи статьи
- Подбор ключевых слов для сайта (Семантическое ядро)
- Правильный подбор ключевых слов
- Какой вариант выбрать
Программы для сбора семантического ядра
Словоеб — это бесплатный аналог KeyCollector, но с множеством урезанных функций, позволяет собирать ключи через Wordstat, определять частотность и собирать поисковые подсказки. Отключена выгрузка результатов.
KeyCollector — мощный многофункциональный инструмент для работы с семантическим ядром, является обязательной программой для всех специалистов по SEO и контекстной рекламе. Стоит всего 1800 рублей.
Настройки KeyCollector
Настройка парсинга Yandex.Direct
В самом верху настроек, вам необходимо будет ввести логин и пароль от аккаунта в Яндекс. Желательно сделать для этого новый аккаунт, не используйте свой рабочий аккаунт.
Настройка парсинга Поисковой выдачи
Крайне желательно использовать XML, если он у вас есть. Это сильно сократить время сбора данных.
Создаете новый проект в программе и перед началом парсинга выбираете необходимый вам регион, например, Москва и область, сохраняете изменения.
Как создать семантическое ядро?
Формирование семантического ядра — это комплексный процесс, включающий анализ тематики и структуры сайта, работу со специальными сервисами и программами, редактирование базы ключей вручную. Есть два основных принципа создания СЯ:
- подбор максимального количества ключей и дальнейшей очистки;
- подбор точных ключевых фраз с самого начала с последующим расширением базы.
Мы обратились к нескольким SEO-экспертам, чтобы узнать, какой подход они предпочитают.
Тарас Гуща, СЕО в SEO.UA, склоняется к первому методу:
Лучше много ключей и потом чистить. Потому как иногда можно упустить весьма стоящие ключевые фразы. Нам как профессионалам продвижения сайтов надо давать клиентам максимальный результат. Поэтому каждая ключевая фраза, которая может конвертировать потенциальную аудиторию в клиента, очень важна.
А вот Катерина Золотарева, Founder & CEO в Site24, считает, что в зависимости от выбранной стратегии можно использовать оба подхода:
Если проект небольшой или в сложной для формирования семантики нише, например, технологические услуги, то однозначно надо собирать все и даже больше, потом вычеркивать нерелевантное, а околотематические ключи отправлять в блог.
Также имеет смысл глубоко заниматься семантикой, если проект уже имеет позиции, трафик, а стандартные базовые ключи и так уже включены в метатеги и текст. Тогда глубокая проработка семантики поможет вам значительно улучшить видимость и трафик.
Этапы создания семантического ядра
Создание СЯ можно разделить на три этапа.
- Выбор подхода для создания СЯ.
Есть несколько стратегий того, как можно собрать семантического ядро. Их применяют в зависимости от того, имеет ли ресурс структуру или только находится в процессе разработки, какой у него уровень оптимизации, какие позиции по ключевым словам он занимает и т.д..
- Сбор запросов с помощью специальных инструментов.
Сервисы подбора ключевых слов дают возможность охватить максимальное число запросов и поисковых подсказок. Для лучшего результата стоит задействовать инструменты для анализа семантики конкурентов.
- Формирование СЯ из общей базы запросов.
Этапы преобразования облака тематических запросов в семантическое ядро включают два основных этапа:
- очистка базы ключей от ненужных запросов;
- кластеризация путем деления семантики на группы.
Также в процессе анализа ключей можно отделить минус-слова. Кластеризация базы запросов предшествует распределению ключевых фраз по URL. В следующих разделах мы рассмотрим все этапы разработки семантического ядра подробно.
Подходы при создании семантического ядра
Рассмотрим стандартные схемы для создания баз ключей. В зависимости от конкретного случая можно использовать один из подходов, приведенных ниже, или же индивидуальную стратегию.
ПЕРВЫЙ ПОДХОД — ФОРМИРОВАНИЕ СТРУКТУРЫ НОВОГО САЙТА НА ОСНОВЕ СЯ.
- Исследование рыночной ниши/торговой линейки/брифа клиента.
- Определение списка основных запросов (seed keywords).
- Сбор максимального количества фраз для каждого основного ключа.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Очистка полученного списка запросов от дублей и мусорных фраз (при наличии списка минус-слов).
- Автоматическая кластеризация через SE Ranking.
- Окончательная очистка запросов.
- Создание структуры сайта по разделам, категориям, страницам на основе кластеризации.
ВТОРОЙ ПОДХОД — СБОР СЯ ПОД ГОТОВУЮ СТРУКТУРУ САЙТА
- Анализ структуры и разделов сайта.
- Определение списка основных запросов.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Сбор максимального количества релевантных ключевых фраз для запросов из п. 2 и 3.
- Очистка от мусорных и нерелевантных фраз.
- Разделение собранных запросов под существующие категории и страницы.
ТРЕТИЙ ПОДХОД — ОБНОВЛЕНИЕ СЕМАНТИЧЕСКОГО ЯДРА ДЛЯ САЙТА.
- Анализ существующей семантики сайта.
- Поиск «слабых мест»: сбор актуальных запросов в тематике, изучение поисковых подсказок, анализ конкурентов для определения недостающих ключей.
- Создание списка упущенных запросов и распределение их по разделам, категориям, страницам.
7Search
Ранее 7search.com гордо называлась одной из наиболее крупных сетей PPC-рекламы. Некоторые специалисты пользуются ей до сих пор. Но это является скорее исключением, чем правилом. Система имеет простой и удобный функционал подбора ключей. Результаты основаны на своих данных рекламной сети, которые она имеет в достаточном количестве.
Даже людям, предпочитающим работать с «Планировщиком ключевых слов», советуют пользоваться сторонними инструментами. В некоторых случаях это позволяет существенно расширить или сузить семантику ресурса и занять более высокие позиции в выдаче.
Пошаговый алгоритм работы с сервисом:
Создание задачи. Чтобы создать задачу, необходимо перейти во вкладку Wordstat и нажать «Создать новую задачу»
Шаг первый: Поисковая система и регион.
Здесь необходимо ввести название задачи (обязательное поле). Можно ввести любое название, часто бывает удобно вводить название сайта, чтобы в будущем легко найти нужную задачу.
Выберите регион.
Шаг второй: Настройки сбораЗдесь есть два чекбокса от выбора которых, будет зависеть тип задачи:
Сбор ключевых слов из левой колонки Wordstat
Сбор частотности (популярности ключевых слов)
Во вкладке «Сбор ключевых слов из левой колонки Wordstat», где вы указываете количество страниц выдачи Wordstat, по которым пройдет робот. Чем глубже идет робот – тем больше ключевых слов можно получить — «Парсить страниц»
Так же вы можете выбрать «Сбор ключевых слов с правой колонки». В такому случае вы соберете ключевые слова с левой и правой колонки Wordstat Сбор частотности (популярности ключевых слов)
Вы указываете необходимый вам тип частотности
Также здесь есть возможность не собирать частотности ниже заданного предела.
В парсинге вордстата используется умный алгоритм, он обходит ограничения в 7 слов, которое есть при парсинге через Яндекс.Директ (парсинг через Яндекс.Директ использует большинство оптимизаторов при работе в кей коллекторе).
Шаг третий: «Ключевые слова и цена».Загружаем запросы.
Можно загрузить списком либо через файл. Поддерживаемые форматы файла: xls, xlsx. Необходимо указать столбец, из которого должны браться данные, а также учитывать или нет первую строку.
Функционал стоп-слов позволит отфильтровать ваш список и сэкономить время и средства. Вы можете воспользоваться готовым списком стоп-слов — выбрать стоп-слова по тематикам и нужный вам регион.
«Эксперт опции» позаботиться о том, что бы вы не потеряли нужные слова
Обращаем внимание, что по умолчанию применяется символьное соответствие — т.е. стоп-слово «бу» удалит слова и фразы содержащие в себе сочетания букв «бу» — «бублик, бу холодильник, бумага» и т.д
Если выбрать фразовое соответствие стоп-слово «бу» удалит только слово / сочетания слов со словом «бу» — «бу холодильник, купить холодильник бу, бу», но не «бумага, бумеранг» и т.п.
Затем нажимаем «Создать новую задачу».
На странице списка задач виден статус заявки.
Очередь – данные еще не собираются. Сбор данных – счетчик показывает, сколько ключевых слов обработано.На паузе – вы можете вручную поставить задачу на паузу, если не уверены, что хотите его собирать. Или же, задача может сама встать на паузу т.к. у вас кончились деньги на балансе.Готов – и рядом появляется возможность скачать .xlsx файл.
После завершения обработки вы можете сразу отправить файл на кластеризацию.
Экспортный файл имеет вид: 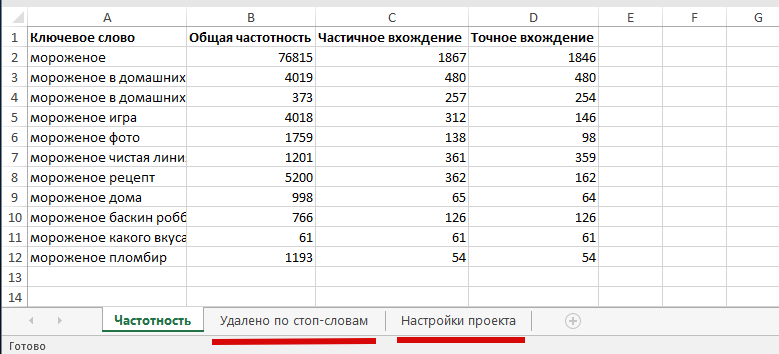
А так же вы можете создать задачи по парсингу Wordstat: сбор левой колонки и проверка частотности через API (api wordstat yandex) — https://www.rush-analytics.ru/api
Yandex Wordstat Assistant
Расширение устанавливается в 3 простых шага:
1) Скачайте актуальную версию расширения для браузера, в котором работаете с Яндекс Wordstat: Google Chrome, Mozilla Firefox, Opera или Яндекс Браузер.
Для всех браузеров алгоритм одинаковый. Мы покажем, как устанавливать и пользоваться возможностями Wordstat Assistant, на примере Google Chrome.
2) Нажмите кнопку для установки:
3) Подтвердите, что собираетесь установить расширение:
На этом всё готово, остается проверить, установилось ли расширение.
Если всё корректно, вы увидите:
Значок с таким уведомлением – теперь он всегда будет отображаться в вашем браузере.

Если такого значка нет, попробуйте перезапустить браузер.
Панель управления Wordstat Assistant в левой области страницы Яндекс Wordstat – в неё будут попадать все ключевые фразы, которые вы добавите.

На случай, если панель не появится, обновите страницу или также перезапустите браузер.
Знак «+» напротив каждого результата и в левой, и в правой колонке – нужен, чтобы добавлять фразы в список.
Чтобы его увидеть, введите нужную фразу, как обычно в Вордстате, например:

Рассмотрим все функции по порядку.
1) Добавление и удаление фраз из списка
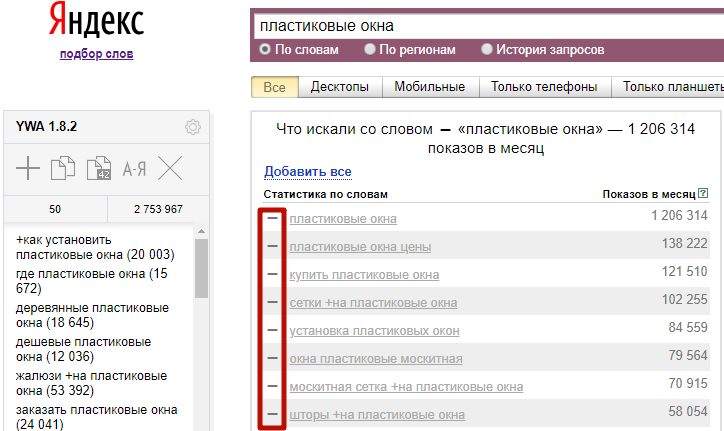
Можно добавить в список отдельную ключевую фразу, нажав на плюс, или все фразы из таблицы (именно с той страницы, на которой вы находитесь, а не из всей выдачи), нажав ссылку «Добавить все»:

Например, мы хотим добавить все похожие фразы из левой колонки с первой страницы. Жмем «Добавить все», в окне подтверждения – «Добавить»:
Выглядит это так, в скобках указана частотность для каждого запроса:
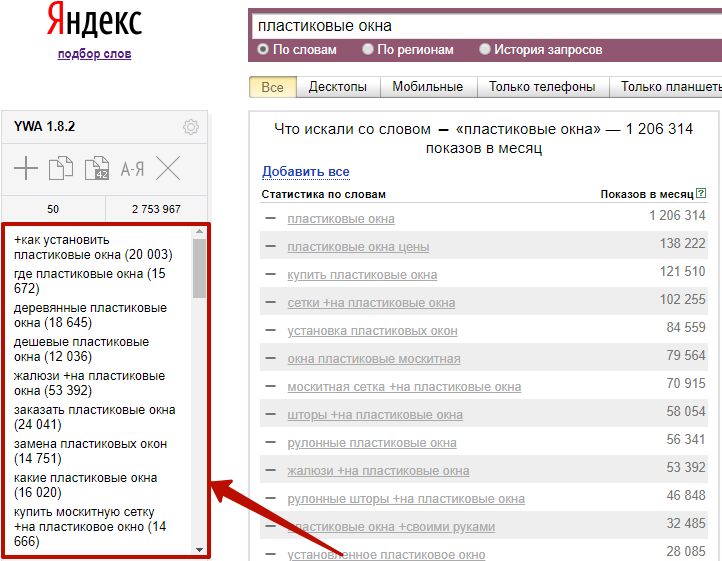
Над списком отображается общее количество фраз, которые вы добавили, и суммарная частотность по ним:
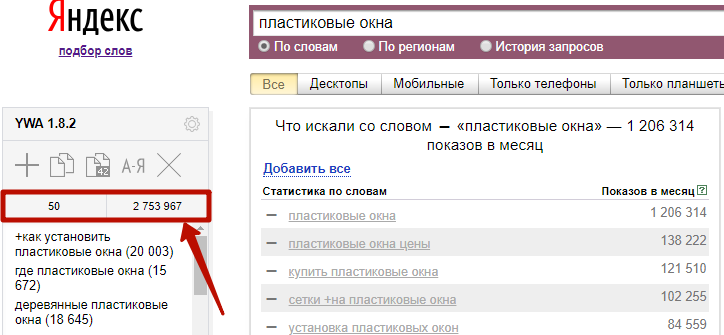
В результатах поиска Yandex Wordstat фразы, которые вы выбрали, становятся серого цвета, со знаком минус вместо плюса.
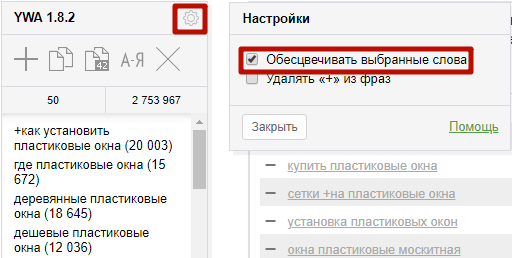
Эти опции при необходимости можно отключить здесь:
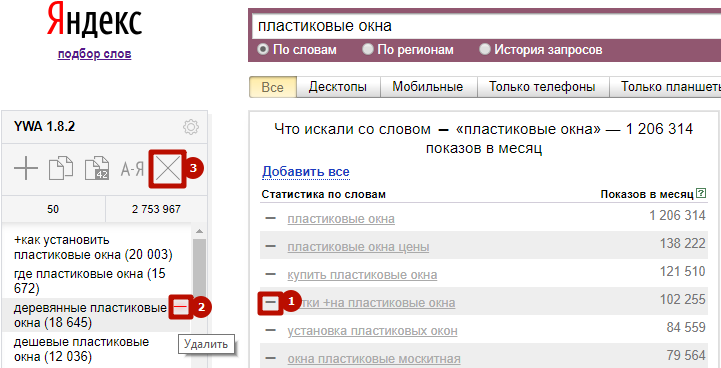
По знаку «–» фразу можно в любой момент удалить из результатов поиска Яндекс Wordstat (1). Либо можно удалить прямо её из панели управления: для этого наведите на фразу курсор и кликните по минусу рядом с ней (2). Чтобы очистить весь список, нажмите крестик вверху панели управления (3).
При попытке добавить такой же ключ, какой уже есть в списке, Wordstat Assistant выдает сообщение:
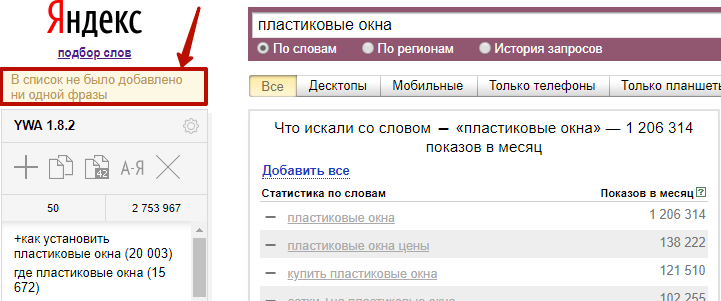
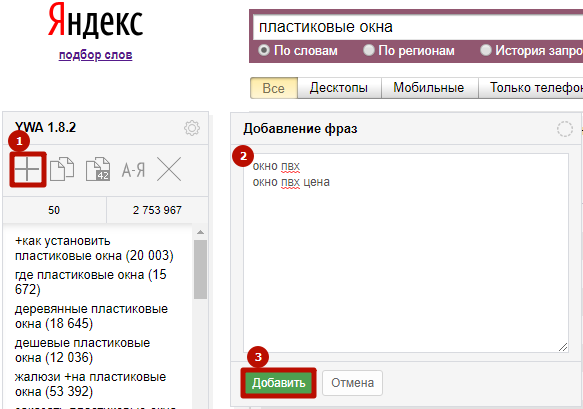
2) Добавление собственных ключей
Для этого нажмите плюс на панели управления, введите запрос или список запросов, как на скриншоте:
Для добавленных вручную фраз вместо частотности показывается знак вопроса:
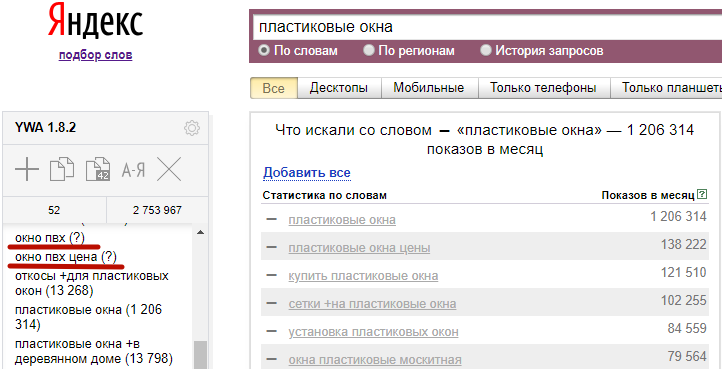
Если ваша фраза совпадает с фразой из результатов поиска Wordstat, последняя выделяется серым цветом. Но частотность при этом остается неизвестной (?), а не перетягивается из данных Wordstat.

3) Сортировка списка ключевых фраз
Её можно выполнять с помощью этой кнопки:
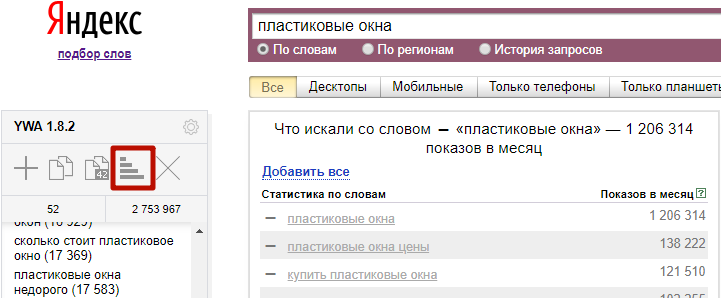
Она меняет свой вид в зависимости от того, по какому признаку вы сортируете фразы:
По возрастанию и убыванию частотности:
По алфавиту:
По порядку добавления (вновь добавленные в конец / в начало списка):
4) Копирование данных из Вордстата
Можно скопировать просто список фраз (1), либо список фраз вместе с фразами значения частотности (2), чтобы работать с ними дальше в любом формате – например, txt или Excel:
Чтобы автоматически удалить знак «+» из всех фраз, задайте эту настройку:
Если вы закроете вкладку с Wordstat или браузер, ничего не потеряется. Список сохранится под тем аккаунтом, в котором вы его сформировали.
Как правильно настроить Словоеб
Основные инструменты
При помощи программы Словоеб можно:
- Осуществить пакетный подбор слов используя правую и левую колонку Yandex.Wordstat. Можно данные действия провести и вручную, зайдя на сайт статистики поисковых запросов Яндекс, но это довольно долго и не весьма удобно, лучше использовать данную программу.
- Осуществить пакетный подбор слов используя Rambler. Adstat. Возможность аналогична с 1 пунктов, только на основании данных статистики запросов поисковика Rambler. Я эти возможности не использую, мне вполне хватает данных Яндекса.
- Определить конкурентность по данному запросу. Тут всё просто, чем выше конкурентность данного запроса, тем сложней его продвинуть и войти по нему в ТОП по поисковой выдаче.
- Определить релевантные страницы по данному запросу в Яндекс и Google. Программа поможет определить релевантную страницу по каждому ключевому запросу и место в выдаче Яндекса и Google по вашему КС. К примеру, если я ранее подбирал ключевые слова и написал под них заметку, то через время можно проверить, есть ли в выдаче основных поисковиков мой сайт по данным запросам.
- Проверить сезонность поисковых запросов, определить KEI (Keyword Effectiveness Index (KEI) — оценка ключевого слова, выраженная в цифровом значении, дающая представление о его эффективности, с точки зрения поискового продвижения). Эти возможности считаю дополнительными и использую редко))
Вот, в принципе, все возможности программы, рекомендую всем, кто пишет статьи, использовать её возможности. Это поможет вам правильно подбирать ключевые фразы и слова и использовать их грамотно в теле заметки. Подробно о том, как правильно писать статьи, рекомендую почитать:
Где скачать программу Словоеб и Key Collektor
Как всегда, рекомендую вам скачивать софт с официальных сайтов разработчика
Скачать бесплатную программу Словоеб и Key Collektor можно тут — http://seom.info/tools/
На странице ищите нужную вам программу и скачивайте самую актуальную версию.
После того, как программу скачаете, распакуйте архив, запускайте программу файлом Slovoeb, после чего нужно внести корректные настройки и данные своих аккаунтов Яндекс и Рамблер, чтобы была возможность парсить запросы.
Настройка программы Словоеб
Любой инструмент для корректной работы необходимо правильно настроить, будь то пианино или софт для вебмастера
После запуска программы находим слева вверху иконку в виде шестеренки (настройки) и переходим в эту вкладку.
Мы пройдёмся детально только по первому разделу «Парсинг», про остальные расскажу коротко, они не столь важны.
Парсинг => Общие
Настройки, которые я выделил на скриншоте выше желтым, вам необходимо сверить со своими. Дело в том, что по умолчанию, с выходом обновлений программы эти цифры могут изменяться. Я выбрал оптимальные и предлагаю вам выбрать такие же параметры, если у вас своё мнение, пожалуйста, выбирайте те цифры, которые для вас являются оптимальными, не возражаю ))
Парсинг=> Yandex.Wordstat
Тут настройки я также слегка подкорректировал и выставил следующие:
Я установил минимальное значение «фразы с частотностью» не менее 25, поскольку для ключевых слов менее 25 писать заметки не стоит, не будет результата и трафика))
Парсинг=> Yandex.Direct
Далее 3 подраздела главы «Парсинг» я пропускаю ( Rambler, поисковая выдача и подсказки) и обращаю ваше внимание на то, что необходимо обязательно внести данные своего аккаунта Яндекс в последний подраздел/
Настоятельно вам рекомендую создать новый аккаунт в Директ и внести его данные в настройках программы Словоеб. Внесите данные название аккаунта и пароль к нему через двоеточие-
логин: пароль
Внимание!
Если вы установили программу на новый ПК, то пароль и логин делайте
новый! Программа не будет работать с одним логином Яндекса на разных
устройствах! У меня на рабочем компе одни логин и пароль, на другом
другие данные Яндекса. Теперь ваша программа готова к обработке данных)) Если у вас часто выскакивает капча при работе программы и вам лень ее вводить ручками, можете воспользоваться сервисами, которые это сделают за вас (раздел настроек «Антикапча») Меня «капча» особо не беспокоит, поэтому я справляюсь сам, без помощи подобных сервисов
Теперь ваша программа готова к обработке данных)) Если у вас часто выскакивает капча при работе программы и вам лень ее вводить ручками, можете воспользоваться сервисами, которые это сделают за вас (раздел настроек «Антикапча») Меня «капча» особо не беспокоит, поэтому я справляюсь сам, без помощи подобных сервисов.
Также можно убрать при помощи настроек лишние колонки (я Рамблером не использую, мне Яндекса вполне хватает), изменить шрифт в программе (я размер на 14 выставил) и прочие мелочи, но это уже каждый сам сможет сделать.
Виды семантических ядер
Семантика для контекста и SEO различается и не может быть взаимозаменяема. Семантическое ядро для контекста будет недостаточно проработанным для SEO продвижения, а ядро для SEO в контексте будет слишком громоздким и неточным.
Семантика для контекстной рекламы
Основная задача это определить по каким именно запросам потенциальные покупатели будут искать товары или услуги, чтобы сразу совершить покупку или сделать заказ. Подбирается максимально релевантная страница для каждого запроса, т.к. чем выше релевантность, тем меньше шанс отказа и «слива» бюджета в рекламе.
Для расширения охвата, в контекстной рекламе, используются околотематические и редкие поисковые запросы. Нецелевые переходы исключаются минус-словами, операторами, а также определенными параметрами целевой аудитории.
В основе сбора семантического ядра для контекстной рекламы лежит не количество ключей, а их качество и точность. Убираются «холодные» запросы, длинные запросы, общие запросы, клик по которым доходит до 5 000 рублей и выше, информационные запросы и запросы, которые имеют низкую частотность.
Семантика для SEO
Основная задача это собрать максимально возможную семантику для сайта, в последствии, из которой будет формироваться большая иерархическая структура.
Семантическое ядро для SEO должно полностью охватывать проблематику сайта, мы должны понимать, что пользователь ищет, что он возможно будет искать, какие проблемы он будет решать, какие вопросы задавать, чтобы на все это дать ответ в категориях, карточках товаров или статьях на сайте.
В основе составления семантического ядра для SEO лежит количество и проработанность ключевых запросов и групп. Чем шире семантическое ядро сайта, тем больше входных страниц на которые будут заходить потенциальные пользователи.
Как пользоваться парсером Wordstat от Click.ru
В числе инструментов Click.ru как раз есть функциональный и недорогой парсер Wordstat. Он быстро выдает частотность даже по большому списку запросов. При этом учитывает типы соответствия и региональность. Еще не требует капчу и прокси-серверы, а отчеты позволяет выгружать в Excel и хранить в «облаке».
Для начала работы зарегистрируйтесь в системе Click.ru. После входа в свой аккаунт на главной странице выберите раздел «Парсер частоты Wordstat» и приступайте к работе.
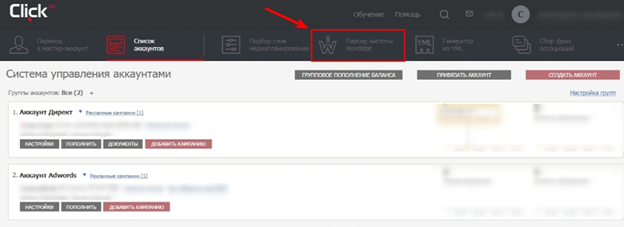 Для начала парсинга перейдите в соответствующий раздел
Для начала парсинга перейдите в соответствующий раздел
Как работать с парсером Wordstat после регистрации в Click.ru:
Загрузите список запросов.
Есть два способа: скопировать и вставить ключи в специальное поле или же загрузить XLSX-файл с ними.
При копировании списка учитывайте, что каждый ключ должен идти с новой строки. А в эксель-файле смотрите, чтобы не было вспомогательной информации (названий столбцов, лишних цифр и т. д.). Система берет запросы из первого листа .XLSX по принципу «одна ячейка – один ключ».
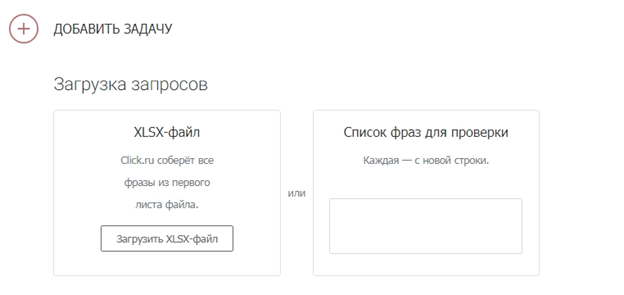 Этап загрузки запросов
Этап загрузки запросов
Выберите регионы.
В системе доступны все регионы Яндекса. Можно посчитать общую частотность по нескольким регионам или получить статистику отдельно по каждому.
Разделять регионы в отчете нужно, если вы планируете продвигать бизнес отдельными региональными поддоменами и посадочными страницами, привязанными к географии. В остальных случаях галочка не ставится.
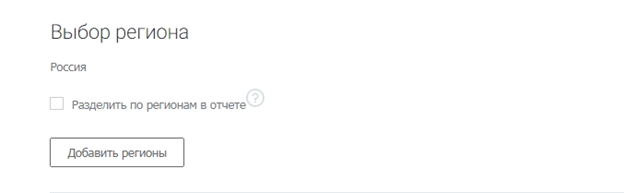 Выбираем регионы
Выбираем регионы
Укажите тип соответствия.
Широкое соответствие – когда фразы пробиваются как есть – часто показывает обманчивую частотность. Все из-за того, что учитываются все вложенные ключи, в том числе нерелевантные (как в примере с игрушками). То есть всегда лучше перепроверять частоту запроса с помощью специальных операторов.
Кавычки позволяют уточнять статистику по конкретной фразе, без учета вложенных ключей.
Пример
| скачать видео бесплатно – 1 111 285 показов | “скачать видео бесплатно” – 8 493 показа |
Кавычки с восклицательными знаками показывают частотность по заданным словоформам.
Пример
| “!купить !телефон” – 37 909 показов | “!купить !телефоны” – 2 798 показов |
Квадратные скобки – фиксируют порядок слов, что особенно важно в туристическом бизнесе
Пример
| – 4 213 показов | – 1 814 показов |
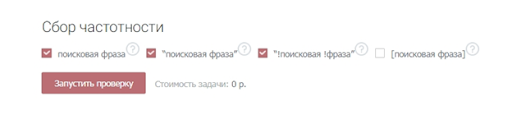 Все варианты типов соответствия
Все варианты типов соответствия
Запустите проверку.
Время сбора частотностей зависит от количества запросов, регионов и типов соответствия. Если запросов меньше 1 000, процесс займет 1–2 минуты.
Результат будет доступен в списке задач. Можно открыть отчет в браузере или скачать его в формате XLSX.
 Здесь будут появляться отчеты со статистикой
Здесь будут появляться отчеты со статистикой
Сервисы для группировки ключевых слов
- rush-analytics.ru — сбор Яндекс.Вордстат, подсказок и автоматическая кластеризация запросов;
- seo-case.com — автоматическая группировка ключевых слов;
- just-magic.org — автоматический подбор и группировка ключевых слов;
- engine.seointellect.ru — автоматическая группировка ключевых слов;
- coolakov.ru — автоматическая группировка ключевых слов;
- semparser.ru — структуризация семантики для SEO и контекста, обсуждение;
- stoolz.ru — сервис кластеризации запросов, обсуждение;
- mc-castle.ru — кластеризация запросов, обсуждение;
- kg.ppc-panel.ru — ручная группировка ключевых запросов;
- zapros.binet.pro — группировка ключевых слов для информационных сайтов от puzat.ru;
- mykeywords.ru — сервис по кластеризации ключевых слов на основе частотного анализа, обсуждение.
- art.monica.pro — сервис Артикластер для группировки ключевых фраз и подготовки ТЗ для авторов, обсуждение.
Как группировать запросы
Чтобы понять, как распределять ключевые слова по отдельным страницам, нужно сгруппировать запросы. Для этого надо создать семантические кластеры.
Чаще всего, ключевые слова из кластеров первого и второго уровней определяются еще на этапе мозгового штурма. Для этого просто нужно хорошо разбираться в своем продукте или ориентироваться на структуру сайтов-конкурентов. Семантика остальных подуровней определяется на этапе детального составления семантического ядра и его кластеризации
Еще одно важное условие — каждая группа запросов последнего уровня должна соответствовать одной потребности пользователя. Например, покупка конкретного вида детского белья
Используем Словоёб с уже известной нам функцией быстрого фильтра. С его помощью можно легко отсортировать фразы по категориям для дальнейшего внедрения на посадочных страницах.
1. Введите в поле быстрого фильтра базовое ключевое слово, которое может станет названием для категории/подкатегории/посадочной страницы (например, бренд детского постельного белья «Непоседа») и нажмите Enter.
2. Выделите нужные фразы и скопируйте их.
3. Удалите отмеченные строки правой кнопкой мыши.
4. Создайте в правом меню новую группу (например, с названием «Непоседы»).
5. Для добавления только что выбранных фраз в эту группу, перейдите во вкладку «Данные» — «Добавить фразы».
6. Вернитесь к прежнему списку нажатием клавиши Enter в поле поиска быстрого фильтра.
7. Повторите эту процедуру с другими запросами. Ключевые фразы автоматически выстроятся в алфавитном порядке, благодаря чему можно легко удалить лишние слова или выделить похожие фразы в отдельную группу.
Группировка вручную требует много времени (особенно в том случае, если семантика достаточно широкая). Для автоматизации этого процесса можно использовать платные Key Collector, Rush-Analytics, Just-Magic, или бесплатный скрипт Devaka.ru. Часто приходится объединять некоторые группы запросов. Например, такие:
Согласитесь, создавать две отдельные категории под фразы «красивое белье» и «стильное белье» неразумно 🙂 Для понимания важности фраз для каждой категории/посадочной страницы, скопируйте их в Планировщик ключевых слов Google в раздел «Получение статистики запросов и трендов»:
Так вы проверяете популярность (частотность) поискового запроса. В целом все поисковые запросы делятся на:
- ВЧ-запросы (высокочастотные).
- СЧ-запросы (среднечастотные).
- НЧ-запросы (низкочастотные).
- Микро НЧ-запросы.
При этом нет точных цифр, по которым можно с уверенностью сказать, что запрос принадлежит к определенной группе. Все зависит от тематики сайта. В одних тематиках фраза с частотностью 1000 запросов в месяц может быть низкочастотной (фильмы, музыка), в других — 200 запросов уже может быть признаком высокочастотной фразы (финансовая тематика). Соотношение этих групп: Наиболее высокочастотные запросы впоследствии вписывайте в метатеги. А под низкочастотные оптимизируйте страницы сайта. Как правило, они очень низкоконкурентны, и достаточно провести качественную работу с текстами, чтобы вывести соответствующие страницы в ТОП.
Читайте, как привлечь целевой трафик на сайт с помощью формирования максимально широкого семантического ядра.
После всех этих манипуляций вы получите подробную структуру сайта, состоящую из ключевых фраз для:
Составление масок для парсинга
Начинаем подбор ключевых запросов с составления запросов для парсинга. Чаще всего это 2-словные, но иногда и 3-словные запросы, которые также называют «масками».
Эти запросы должны максимально коротко, но релевантно описывать ваши услуги или товары.
Предположим, вы предлагаете доставку еды. Подходящими для вас масками будут:
– доставка еды – еда на дом – еда в офис – заказать еду – доставка обедов и т. д.
В зависимости от ассортимента, вам также нужно охватить более точные запросы, например: доставка плова, заказать суши и т. д.
Вам интересны интернет-маркетинг и продвижение бизнеса в интернете? Подписывайтесь на наш Telegram-канал!
Как правильно составить маски запросов?
Не стоит пренебрегать данным этапом сбора семантического ядра (СЯ), так как от него зависит полнота СЯ, охват кампании, средняя цена за клик, количество и стоимость конверсий.
Неопытные специалисты часто используют только самые очевидные запросы. И хотя они охватывают большую часть целевой аудитории, по этим запросам самая высокая конкуренция и, как следствие, цена клика.
Чтобы собрать максимальное количество непересекающихся запросов, используйте:
- Брейншторминг. Просто подумайте, с помощью каких запросов ваша целевая аудитория может искать ваши товары или услуги.
- Правая колонка Yandex Wordstat. У Яндекса большой объем статистики, что и как ищут пользователи, и часто предлагает хорошие варианты ключевых фраз, до которых мы сами не додумались бы. Этот способ подходит и для сбора семантического ядра под Google;
- Блок «Вместе с этим ищут» на поиске Google и Яндекс. Работает по той же логике, что и правая колонка Wordstat — показывает, какие еще запросы вводят пользователи, которые ищут по определенному запросу.
- Сайты конкурентов. Просмотрите сайты ваших топ 5-10 конкурентов в Google и Яндекс. Подходящие нам ключевые запросы часто можно обнаружить в заголовках или в тексте на продвигаемых страницах.
- Названия конкурентов. В некоторых нишах, при правильном подходе, хорошие результаты показывает реклама на бренд конкурентов. Например, если вы занимаетесь доставкой пиццы, то в качестве ключевых фраз можете попробовать использовать « додо пицца» или «доминос».
- Ключевые слова конкурентов. Есть специальные сервисы конкурентного анализа, которые предлагают показать, какие запросы используют ваши конкуренты. Точность этих сервисов оставляет желать лучшего, но иногда помогают найти новые, релевантные запросы. Мы пользуемся keys.so, как недорогим и достаточно функциональным сервисом.
- Нестандартные формулировки, транслитерация, сленг. Иногда один и тот же бренд люди пишут по разному и, чтобы охватить их, нам нужно использовать все эти варианты в качестве ключевых слов. Например, вы продаете запчасти для автомобилей Hyundai. Чтобы охватить целевую аудиторию полностью, в вашем семантическом ядре должны использоваться слова: Хундай, Хендай, Хёндай, Хюндай, Хьюндай.

Блок «Вместе с этим ищут» в Яндексе

Правая колонка Яндекс Вордстат с рекомендациями ключевых слов
Букварикс
Сервис Букварикс предоставляет набор инструментов для работы с ключевыми словами и доменами, а также для работы со списками.
Возможности Букварикс:
- Поиск по ключевым словам (по одному слову или по списку);
- Поиск по заданному домену;
- Сравнение доменов (двух, нескольких).
- Приведение слов в списке к одному виду;
- Анализ слов в списке по частоте встречаемости (в порядке снижения частоты);
- Сравнение двух списков и формирование одного общего списка оригинальных ключевых слов;
- Комбинирование и формирование словосочетаний из ключевых слов двух списков;
- Поиск и удаление дубликатов слов из списка.
Тарифы:
- Без регистрации – бесплатно (с ограниченными возможностями);
- Бесплатный аккаунт – бесплатно (с ограниченными возможностями);
- Бизнес-аккаунт – 695 рублей за 1 месяц.
Ключевые идеи статьи
1. Не ограничивайтесь самыми очевидные ключевыми словами! Подберите релевантные, но нестандартные формулировки, которые принесут вам недорогие клики и конверсии.
2
Уделяйте большое внимание минус-словам. Чем полнее и ваш список минус-слов, тем меньше нецелевых показов и кликов получите
3. Информационные запросы используйте только если есть подходящие посадочные страницы для них. Генерировать прямые продажи по инфо-запросам будет сложно.
4. Пользы от больших семантических ядер нет. Для большинства кампаний несколько десятков или сотен запросов вполне достаточно, чтобы получить релевантный трафик по максимально низкой цене.
Если же у вас возникли трудности с подбором ключевых запросов для Яндекс Директ или Google Рекламы, или другие проблемы при запуске или ведении кампаний, обращайтесь к нашим специалистам.
Подбор ключевых слов для сайта (Семантическое ядро)
Первый шаг к правильному SEO тексту. Прежде чем писать статью или правильно оформить страницу сайта необходимо разобраться с тематикой проекта. Подобрать основные словосочетания, по которым люди ищут похожие на ваш ресурс или товары. Главным помощником новичка в SEO продвижении станет Яндекс, а точнее статистический сервис поисковой машины Вордстат: yandex.wordstat. Информации с этого ресурса хватит новичку на первые 3 — 4 месяца работы. Потом можно будет пользоваться всплывающими подсказками поисковиков Google и Yandex и другими статистическими службами, но об этом читайте в другом материале. Как подобрать ключевой запрос с помощью Яндекс Вордстат:
- Напишите не задуманное словосочетание, а набор из 4 — 5 слов. При каждом новом подборе статистики удаляйте по одному слову.
- Смотрите на похожие запросы, которые показывает Яндекс справа.
- Вначале обрабатывайте низкочастотные запросы (по статистике имеют показы не более 100-150 раз в месяц)
Отступление:
Как же раздражает в людях пафос. Нет, чтобы написать – подобрать ключевые запросы. Нет, нужно написать так, чтобы это было с пафосом и звучно для заказчика. Рутинная вещь, из категории умывания и чистки зубов. А как пишут — семантическое ядро сайта. Тьфу ….
После составления семантического ядра должен появиться следующий Excel — ий файл: Статистический по проекту В таблицах файла отображены ключевые запросы и позиции сайта на начало продвижение, а так же url-адреса страниц по каждой позиции. Позже вы внесете туда примечания,наметите план продвижения и расширите запросную базу продвигаемого сайта. Таким документом можно пользоваться в начальной стадии статейного продвижения сайта. Для новичка в SEO его с головой хватит на 6 — 12 месяцев. Ведение статистики обязательно, ведь субъективные ощущения часто подводят!
Правильный подбор ключевых слов
Далее стоит посмотреть на то, по каким словам продвигаются конкуренты, какие вопросы затрагиваются на тематических форумах и в сообществах. Всё это идеи для сайта.
Кроме самих ключевых слов, обязательно уделите внимание их синонимам, так как слова или фразы, выражающие одно и то же понятие, одинаково востребованы и по ним будут переходить пользователи. Количество задействованных формулировок прямо влияет на релевантность страницы
Выбирая те или иные ключевые слова, ориентируйтесь в первую очередь на статистику, предоставляемую поисковыми системами, так как посторонние программы редко дают реальную картину. Данные Яндекса или Google объективны и помогут вам подобрать правильные список ключевых запросов, и чем точнее тематика подобранных слов, тем логичнее будет структурирован ваш интернет-ресурс.
Иногда количество ключевых слов при формировании семантического ядра ограниченно, так как низкочастотные слова непопулярны. Однако старайтесь собрать у себя как можно больше ключевых слов, даже если статистика свидетельствует о том, что по низкочастотным запросам ваш сайт посещают очень редко. Если такими словами пренебрегать, то это приводит к плохим результатам, и вы сами уменьшите популярность сайта.
Отдельного разговора заслуживает подбор ключей на уже работающем сайте, когда надо нарастить трафик.
Просто собрать семантику и подготовить тексты — мало. Семантику надо актуализировать, хотя бы раз в пол года, в некоторых нишах — чаще. Новые запросы, подсказки, вариации старых, тренды, новинки и т.д. В тоже время, если вы видите,ч то конкуренты вяло реагируют на изменения (а это очень частый случай) — это ваш шанс пробиться даже вопреки конкуренции старых трастовых сайтов.
Какой вариант выбрать
Долгое время все продвигались по позициям. Компании вели ожесточенную борьбу за попадание в ТОП-10 по определенному ключевому слову. С каждым годом делать это все труднее. Поисковые подсказки, особенности региональной и персонализированной выдачи и другие факторы вносят коррективы в результаты выдачи по одному и тому же запросу. Поэтому последние несколько лет все больше компаний делают ставку на трафиковое продвижение, чтобы получить больший охват пользователей и меньше зависеть от изменений алгоритмов.
Сейчас для достижения максимального эффекта лучший вариант — объединить два способа. Сначала прорабатываем весь сайт по большому пулу запросов, а дальше занимаемся приоритетными запросами индивидуально.