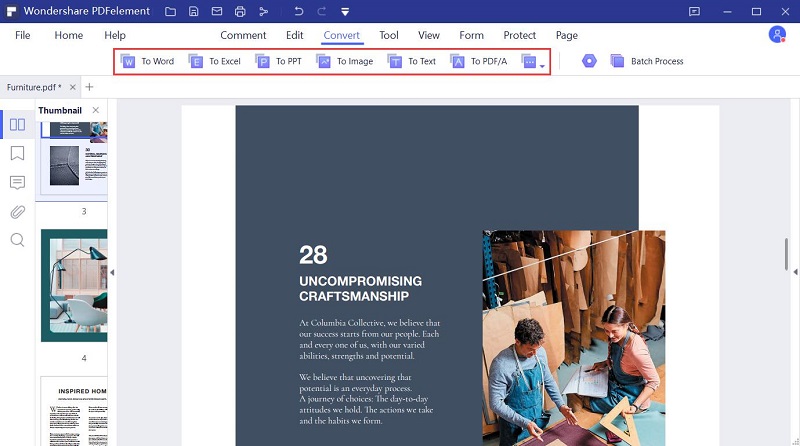
Seo spider companion tools, aka ‘the magnificent seven’
Содержание:
- 3) Select ‘Pages’ To Include
- Small Update – Version 4.1 Released 16th July 2015
- 7) Updated SERP Snippet Emulator
- 4) Exclude Pages From The XML Sitemap
- 4) Cookies
- Other Updates
- 2) Google Sheets Export
- Other Updates
- 4) XML Sitemap Crawl Integration
- 5) XML Sitemap Improvements
- 1) Structured Data & Validation
- Установка программы
- Other Updates
- 3) Crawl Overview Right Hand Window Pane
- Command Line Options
- 1) Configurable Database Storage (Scale)
- Итоговая таблица с окончательными результатами тестирования:
3) Select ‘Pages’ To Include
Only HTML pages included in the ‘internal’ tab with a ‘200’ OK response from the crawl will be included in the XML sitemap as default. So you don’t need to worry about redirects (3XX), client side errors (4XX Errors, like broken links) or server errors (5XX) being included in the sitemap. However, you can select to include them optionally, as in some scenarios you may require them.
Pages which are blocked by robots.txt, set as ‘noindex’, have been ‘canonicalised’ (the canonical URL is different to the URL of the page), paginated (URLs with a rel=“prev”) or PDFs are also not included as standard. This can all be adjusted within the XML Sitemap ‘pages’ configuration, so simply select your preference.

You can see which URLs have no response, are blocked, or redirect or error under the ‘Responses’ tab and using the respective filters. You can see which URLs are ‘noindex’, ‘canonicalised’ or have a rel=“prev” link element on them under the ‘Directives’ tab and using the filters as well.

Small Update – Version 4.1 Released 16th July 2015
We have just released a small update to version 4.1 of the Screaming Frog SEO Spider. There’s a new ‘GA Not Matched’ report in this release, as well as some bug fixes. This release includes the following –
GA Not Matched Report
We have released a new ‘GA Not Matched’ report, which you can find under the ‘reports’ menu in the top level navigation.
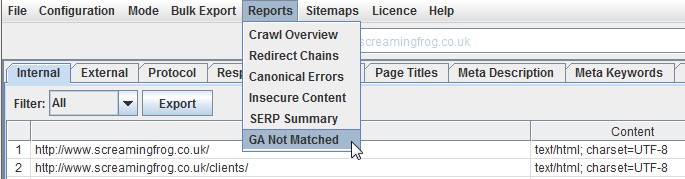
Data within this report is only available when you’ve connected to the Google Analytics API and collected data for a crawl. It essentially provides a list of all URLs collected from the GA API, that were not matched against the URLs discovered within the crawl.
This report can include anything that GA returns, such as pages in a shopping cart, or logged in areas. Hence, often the most useful data for SEOs is returned by querying the path dimension and ‘organic traffic’ segment. This can then help identify –
- Orphan Pages – These are pages that are not linked to internally on the website, but do exist. These might just be old pages, those missed in an old site migration or pages just found externally (via external links, or referring sites). This report allows you to browse through the list and see which are relevant and potentially upload via .
- Errors – The report can include 404 errors, which sometimes include the referring website within the URL as well (you will need the ‘all traffic’ segment for these). This can be useful for chasing up websites to correct external links, or just 301 redirecting the URL which errors, to the correct page! This report can also include URLs which might be canonicalised or blocked by robots.txt, but are actually still indexed and delivering some traffic.
- GA URL Matching Problems – If data isn’t matching against URLs in a crawl, you can check to see what URLs are being returned via the GA API. This might highlight any issues with the particular Google Analytics view, such as filters on URLs, such as ‘extended URL’ hacks etc. For the SEO Spider to return data against URLs in the crawl, the URLs need to match up. So changing to a ‘raw’ GA view, which hasn’t been touched in anyway, might help.
Other bug fixes in this release include the following –
- Fixed a couple of crashes in the custom extraction feature.
- Fixed an issue where GA requests weren’t going through the configured proxy.
- Fixed a bug with URL length, which was being incorrectly reported.
- We changed the GA range to be 30 days back from yesterday to match GA by default.
I believe that’s everything for now and please do let us know if you have any problems or spot any bugs via our support. Thanks again to everyone for all their support and feedback as usual.
Now go and !
7) Updated SERP Snippet Emulator
Google increased the average length of SERP snippets significantly in November last year, where they jumped from around 156 characters to over 300. Based upon our research, the default max description length filters have been increased to 320 characters and 1,866 pixels on desktop within the SEO Spider.
The lower window has also been updated to reflect this change, so you can view how your page might appear in Google.

It’s worth remembering that this is for desktop. Mobile search snippets also increased, but from our research, are quite a bit smaller – approx. 1,535px for descriptions, which is generally below 230 characters. So, if a lot of your traffic and conversions are via mobile, you may wish to update your max description preferences under ‘Config > Spider > Preferences’. You can switch ‘device’ type within the SERP snippet emulator to view how these appear different to desktop.
As outlined previously, the SERP snippet emulator might still be occasionally a word out in either direction compared to what you see in the Google SERP due to exact pixel sizes and boundaries. Google also sometimes cut descriptions off much earlier (particularly for video), so please use just as an approximate guide.
4) Exclude Pages From The XML Sitemap
Outside of the above configuration options, there might be additional ‘internal’ HTML 200 response pages that you simply don’t want to include within the XML Sitemap.

For example, you shouldn’t include ‘duplicate’ pages within a sitemap. If a page can be reached by two different URLs, for example http://example.com and http://www.example.com (and they both resolve with a ‘200’ response), then only a single preferred canonical version should be included in the sitemap. You shouldn’t include URLs with session ID’s (you can use the feature to strip these during a crawl), there might be some URLs with lots of parameters that are not needed, or just sections of a website which are unnecessary.
There’s a few ways to make sure they are not included within the XML Sitemap –
- If there are sections of the website or URL paths that you don’t want to include in the XML Sitemap, you can simply them in the configuration pre-crawl. As they won’t be crawled, they won’t be included within the ‘internal’ tab or the XML Sitemap.
- If you have already crawled URLs which you don’t want included in the XML Sitemap export, then simply highlight them in the ‘internal tab’ in the top window pane, right click and ‘remove’ them, before creating the XML sitemap.
- Alternatively you can export the ‘internal’ tab to Excel, filter and delete any URLs that are not required and re-upload the file in , before generating the XML sitemap.
4) Cookies
You can now also store cookies from across a crawl. You can choose to extract them via ‘Config > Spider > Extraction’ and selecting ‘Cookies’. These will then be shown in full in the lower window Cookies tab.

You’ll need to use mode to get an accurate view of cookies, which are loaded on the page using JavaScript or pixel image tags.
The SEO Spider will collect cookie name, value, domain (first or third party), expiry as well as attributes such as secure and HttpOnly.
This data can then be analysed in aggregate to help with cookie audits, such as those for GDPR via ‘Reports > Cookies > Cookie Summary’.

You can also highlight multiple URLs at a time to analyse in bulk, or export via the ‘Bulk Export > Web > All Cookies’.
Please note – When you choose to store cookies, the auto exclusion performed by the SEO Spider for Google Analytics tracking tags is disabled to provide an accurate view of all cookies issued.
This means it will affect your analytics reporting, unless you choose to exclude any tracking scripts from firing by using the configuration (‘Config > Exclude’) or filter out the ‘Screaming Frog SEO Spider’ user-agent similar to .
Other Updates
We have also included some other smaller updates and bug fixes in version 6.0 of the Screaming Frog SEO Spider, which include the following –
- A new ‘Text Ratio’ column has been introduced in the internal tab which calculates the text to HTML ratio.
- Google updated their Search Analytics API, so the SEO Spider can now retrieve more than 5k rows of data from Search Console.
- There’s a new ‘search query filter’ for Search Console, which allows users to include or exclude keywords (under ‘Configuration > API Access > Google Search Console > Dimension tab’). This should be useful for excluding brand queries for example.
- There’s a new configuration to extract images from the IMG srcset attribute under ‘Configuration > Advanced’.
- The new Googlebot smartphone user-agent has been included.
- Updated our support for relative base tags.
- Removed the blank line at the start of Excel exports.
- Fixed a bug with word count which could make it less accurate.
- Fixed a bug with GSC CTR numbers.
I think that’s just about everything! As always, please do let us know if you have any problems or spot any bugs at all.
Thanks to everyone for all the support and continued feedback. Apologies for any features we couldn’t include in this update, we are already working on the next set of updates and there’s plenty more to come!
Now go and download !
2) Google Sheets Export
You’re now able to export directly to Google Sheets.

You can add multiple Google accounts and connect to any, quickly, to save your crawl data which will appear in Google Drive within a ‘Screaming Frog SEO Spider’ folder, and be accessible via Sheets.

Many of you will already be aware that Google Sheets isn’t really built for scale and has a 5m cell limit. This sounds like a lot, but when you have 55 columns by default in the Internal tab (which can easily triple depending on your config), it means you can only export around 90k rows (55 x 90,000 = 4,950,000 cells).
If you need to export more, use a different export format that’s built for the size (or reduce your number of columns). We had started work on writing to multiple sheets, but really, Sheets shouldn’t be used in that way.
This has also been integrated into and the . This means you can schedule a crawl, which automatically exports any tabs, filters, exports or reports to a Sheet within Google Drive.
You’re able to choose to create a timestamped folder in Google Drive, or overwrite an existing file.

This should be helpful when sharing data in teams, with clients, or for Google Data Studio reporting.
Other Updates
We have also performed other updates in the version 3.0 of the Screaming Frog SEO Spider, which include the following –
- You can now view the ‘Last-Modified’ header response within a column in the ‘Internal’ tab. This can be helpful for tracking down new, old, or pages within a certain date range. ‘Response time’ of URLs has also been moved into the internal tab as well (which used to just be in the ‘Response Codes’ tab, thanks to RaphSEO for that one).
- The parser has been updated so it’s less strict about the validity of HTML mark-up. For example, in the past if you had invalid HTML mark-up in the HEAD, page titles, meta descriptions or word count may not always be collected. Now the SEO Spider will simply ignore it and collect the content of elements regardless.
- There’s now a ‘mobile-friendly’ entry in the description prefix dropdown menu of the SERP panel. From our testing, these are not used within the description truncation calculations by Google (so you have the same amount of space for characters as pre there introduction).
- We now read the contents of robots.txt files only if the response code is 200 OK. Previously we read the contents irrespective of the response code.
- Loading of large crawl files has been optimised, so this should be much quicker.
- We now remove ‘tabs’ from links, just like Google do (again, as per internal testing). So if a link on a page contains the tab character, it will be removed.
- We have formatted numbers displayed in filter total and progress at the bottom. This is useful when crawling at scale! For example, you will see 500,000 rather than 500000.
- The number of rows in the filter drop down have been increased, so users don’t have to scroll.
- The default response timeout has been increased from 10 secs to 20 secs, as there appears to be plenty of slow responding websites still out there unfortunately!
- The lower window pane cells are now individually selectable, like the main window pane.
- The ‘search’ button next to the search field has been removed, as it was fairly redundant as you can just press ‘Enter’ to search.
- There’s been a few updates and improvements to the GUI that you may notice.
- (Updated) – The ‘Overview Report’ now also contains the data you can see in the right hand window pane ‘Response Times’ tab. Thanks to Nate Plaunt and I believe a couple of others who also made the suggestion (apologies for forgetting anyone).
We have also fixed a number of reported bugs, which include –
- Fixed a bug with ‘Depth Stats’, where the percentage didn’t always add up to 100%.
- Fixed a bug when crawling from the domain root (without www.) and the ‘crawl all subdomains’ configuration ticked, which caused all external domains to be treated as internal.
- Fixed a bug with inconsistent URL encoding. The UI now always shows the non URL encoded version of a URL. If a URL is linked to both encoded and unencoded, we’ll now only show the URL once.
- Fixed a crash in Configuration->URL Rewriting->Regex Replace, as reported by a couple of users.
- Fixed a crash for a bound checking issue, as reported by Ahmed Khalifa.
- Fixed a bug where unchecking the ‘Check External’ tickbox still checks external links, that are not HTML anchors (so still checks images, CSS etc).
- Fixed a bug where the leading international character was stripped out from SERP title preview.
- Fixed a bug when crawling links which contained a new line. Google removes and ignores them, so we do now as well.
- Fixed a bug where AJAX URLs are UTF-16 encoded using a BOM. We now derive encoding from a BOM, if it’s present.
Hopefully that covers everything! We hope the new features are helpful and we expect our next update to be significantly larger. If you have any problems with the latest release, do just pop through the details to support, and as always, we welcome any feedback or suggestions.
You can download the SEO Spider 3.0 now. Thanks to everyone for their awesome support.
4) XML Sitemap Crawl Integration
It’s always been possible to crawl XML Sitemaps directly within the SEO Spider (in ), however, you’re now able to crawl and integrate them as part of a site crawl.
You can select to crawl XML Sitemaps under ‘Configuration > Spider’, and the SEO Spider will auto-discover them from robots.txt entry, or the location can be supplied.

The new and filters allow you to quickly analyse common issues with your XML Sitemap, such as URLs not in the sitemap, orphan pages, non-indexable URLs and more.

You can also now supply the XML Sitemap location into the URL bar at the top, and the SEO Spider will crawl that directly, too (instead of switching to list mode).
5) XML Sitemap Improvements
You’re now able to create XML Sitemaps with any response code, rather than just 200 ‘OK’ status pages. This allows flexibility to quickly create sitemaps for a variety of scenarios, such as for pages that don’t yet exist, that 301 to new URLs and you wish to force Google to re-crawl, or are a 404/410 and you want to remove quickly from the index.
If you have hreflang on the website set-up correctly, then you can also select to include hreflang within the XML Sitemap.

Please note – The SEO Spider can only create XML Sitemaps with hreflang if they are already present currently (as attributes or via the HTTP header). More to come here.
1) Structured Data & Validation
Structured data is becoming increasingly important to provide search engines with explicit clues about the meaning of pages, and enabling special search result features and enhancements in Google.
The SEO Spider now allows you to crawl and extract structured data from the three supported formats (JSON-LD, Microdata and RDFa) and validate it against Schema.org specifications and Google’s 25+ search features at scale.

To extract and validate structured data you just need to select the options under ‘Config > Spider > Advanced’.

Structured data itemtypes will then be pulled into the ‘Structured Data’ tab with columns for totals, errors and warnings discovered. You can filter URLs to those containing structured data, missing structured data, the specific format, and by validation errors or warnings.

The structured data details lower window pane provides specifics on the items encountered. The left-hand side of the lower window pane shows property values and icons against them when there are errors or warnings, and the right-hand window provides information on the specific issues discovered.
The right-hand side of the lower window pane will detail the validation type (Schema.org, or a Google Feature), the severity (an error, warning or just info) and a message for the specific issue to fix. It will also provide a link to the specific Schema.org property.
In the random example below from a quick analysis of the ‘car insurance’ SERPs, we can see lv.com have Google Product feature validation errors and warnings. The right-hand window pane lists those required (with an error), and recommended (with a warning).

As ‘product’ is used on these pages, it will be validated against Google product feature guidelines, where an image is required, and there are half a dozen other recommended properties that are missing.
Another example from the same SERP, is Hastings Direct who have a Google Local Business feature validation error against the use of ‘UK’ in the ‘addressCountry‘ schema property.

The right-hand window pane explains that this is because the format needs to be two-letter ISO 3166-1 alpha-2 country codes (and the United Kingdom is ‘GB’). If you check the page in Google’s structured data testing tool, this error isn’t picked up. Screaming Frog FTW.
The SEO Spider will validate against 26 of Google’s 28 search features currently and you can see the full list in our section of the user guide.
As many of you will be aware, frustratingly Google don’t currently provide an API for their own Structured Data Testing Tool (at least a public one we can legitimately use) and they are slowly rolling out new structured data reporting in Search Console. As useful as the existing SDTT is, our testing found inconsistency in what it validates, and the results sometimes just don’t match Google’s own documented guidelines for search features (it often mixes up required or recommended properties for example).
We researched alternatives, like using the Yandex structured data validator (which does have an API), but again, found plenty of inconsistencies and fundamental differences to Google’s feature requirements – which we wanted to focus upon, due to our core user base.
Hence, we went ahead and built our own structured data validator, which considers both Schema.org specifications and Google feature requirements. This is another first to be seen in the SEO Spider, after previously introducing innovative new features such as JavaScript Rendering to the market.
There are plenty of nuances in structured data and this feature will not be perfect initially, so please do let us know if you spot any issues and we’ll fix them up quickly. We obviously recommend using this new feature in combination with Google’s Structured Data Testing Tool as well.
Установка программы
Скачать программу нужно на сайте автора: https://netpeaksoftware.com/ru/spider.
Установка простая и быстрая. Язык выбираем русский. После открытия программы нужно пройти регистрацию. Это тоже бесплатно. После регистрации вы получите на указанный почтовый ящик ключ авторизации. Вводим ключ и работаем.

- Вписываем URL исследуемого сайта. Жмем старт;
- После анализа манипулируем кнопками и смотрим анализ по нужному параметру;
- Фильтры результатов анализа достаточно разнообразны и понятны. Жмете на кнопки, списки перестраиваются;
- Что приятно, есть визуальная раскраска результатов. Удобно;
- Показ дублей страниц заказываем справа внизу. Дубли показываются по повторяющемуся тексту и показывают URL, где дубли присутствуют;
- Результаты анализа можно сохранить файлом Excel. В отличае от программы XENU повторно открыть файл в программе нельзя.
Other Updates
Version 14.0 also includes a number of smaller updates and bug fixes, outlined below.
- There’s now a new filter for ‘Missing Alt Attribute’ under the ‘Images’ tab. Previously missing and empty alt attributes would appear under the singular ‘Missing Alt Text’ filter. However, it can be useful to separate these, as decorative images should have empty alt text (alt=””), rather than leaving out the alt attribute which can cause issues in screen readers. Please see our How To Find Missing Image Alt Text & Attributes tutorial.
- Headless Chrome used in JavaScript rendering has been updated to keep up with evergreen Googlebot.
- ‘Accept Cookies’ has been adjusted to ‘‘, with three options – Session Only, Persistent and Do Not Store. The default is ‘Session Only’, which mimics Googlebot’s stateless behaviour.
- The ‘URL’ tab has new filters available around common issues including Multiple Slashes (//), Repetitive Path, Contains Space and URLs that might be part of an Internal Search.
- The ‘‘ tab now has a filter for ‘Missing Secure Referrer-Policy Header’.
- There’s now a ‘HTTP Version’ column in the Internal and Security tabs, which shows which version the crawl was completed under. This is in preparation for supporting HTTP/2 crawling inline with Googlebot.
- You’re now able to right click and ‘close’ or drag and move the order of lower window tabs, in a similar way to the top tabs.
- Non-Indexable URLs are now not included in the ‘URLs not in Sitemap’ filter, as we presume they are non-indexable correctly and therefore shouldn’t be flagged. Please see our tutorial on ‘How To Audit XML Sitemaps‘ for more.
- Google rich result feature validation has been updated inline with the ever-changing documentation.
- The ‘Google Rich Result Feature Summary’ report available via ‘‘ in the top-level menu, has been updated to include a ‘% eligible’ for rich results, based upon errors discovered. This report also includes the total and unique number of errors and warnings discovered for each Rich Result Feature as an overview.
That’s everything for now, and we’ve already started work on features for version 15. If you experience any issues, please let us know via support and we’ll help.
Thank you to everyone for all their feature requests, feedback, and continued support.
Now, go and download version 14.0 of the Screaming Frog SEO Spider and let us know what you think!
3) Crawl Overview Right Hand Window Pane
We received a lot of positive response to our when it was released last year. However, we felt that it was a little hidden away, so we have introduced a new right hand window which includes the crawl overview report as default. This overview pane updates alongside the crawl, which means you can see which tabs and filters are populated at a glance during the crawl and their respective percentages.

This means you don’t need to click on the tabs and filters to uncover issues, you can just browse and click on these directly as they arise. The ‘Site structure’ tab provides more detail on the depth and most linked to pages without needing to export the ‘crawl overview’ report or sort the data. The ‘response times’ tab provides a quick overview of response time from the SEO Spider requests. This new window pane will be updated further in the next few weeks.
You can choose to hide this window, if you prefer the older format.
Command Line Options
Please see the full list of command line options available to supply as arguments for the SEO Spider.
Start crawling the supplied URL.
--crawl https://www.example.com
Start crawling the specified URLs in list mode.
--crawl-list
Supply a saved configuration file for the SEO Spider to use (example: –config “C:\Users\Your Name\Desktop\supercool-config.seospiderconfig”).
--config
Run in silent mode without an user interface.
--headless
Save the completed crawl.
--save-crawl
Store saved files. Default: current working directory.
--output-folder
Overwrite files in output directory.
--overwrite
Set the project name to be used for storing the crawl in database storage mode and for the folder name in Google Drive. Exports will be stored in a ‘Screaming Frog SEO Spider’ Google Drive directory by default, but using this argument will mean they are stored within ‘Screaming Frog SEO Spider > Project Name’.
--project-name
Set the task name to be used for the crawl name in database storage mode. This will also be used as folder for Google Drive, which is a child of the project folder. For example, ‘Screaming Frog SEO Spider > Project Name > Task Name’ when supplied with project name.
--task-name
Create a timestamped folder in the output directory, and store all output there. This will also create a timestamped directory in Google Drive.
--timestamped-output
Supply a comma separated list of tabs to export. You need to specify the tab name and the filter name separated by a colon. Tab names are as they appear on the user interface, except for those configurable via Configuration->Spider->Preferences where X is used. Eg: Meta Description:Over X Characters
--export-tabs
Supply a comma separated list of bulk exports to perform. The export names are the same as in the Bulk Export menu in the UI. To access exports in a submenu, use ‘submenu-name:export-name’.
--bulk-export export,...]
Supply a comma separated list of reports to save. The report names are the same as in the Reports menu in the UI. To access reports in a submenu, use ‘submenu-name:report-name’.
--save-report report,...]
Creates a sitemap from the completed crawl.
--create-sitemap
Creates an images sitemap from the completed crawl.
--create-images-sitemap
Supply a format to be used for all exports.
--export-format
Use a Google Drive account for Google Sheets exporting.
--google-drive-account
Use the Google Analytics API during crawl. Please remember the quotation marks as shown below.
--use-google-analytics
Use the Google Search Console API during crawl.
--use-google-search-console
Use the PageSpeed Insights API during crawl.
--use-pagespeed
Use the Majestic API during crawl.
--use-majestic
Use the Mozscape API during crawl.
--use-mozscape
Use the Ahrefs API during crawl.
--use-ahrefs
View this list of options.
-h, --help
Use Saved Configurations
If a feature or configuration option isn’t available as a specific command line option outlined above (like the , or JavaScript rendering), you will need to use the user interface to set the exact configuration you wish, and .

You can then supply the saved configuration file when using the CLI to utilise those features.
1) Configurable Database Storage (Scale)
The SEO Spider has traditionally used RAM to store data, which has enabled it to have some amazing advantages; helping to make it lightning fast, super flexible, and providing real-time data and reporting, filtering, sorting and search, during crawls.
However, storing data in memory also has downsides, notably crawling at scale. This is why version 9.0 now allows users to choose to save to disk in a database, which enables the SEO Spider to crawl at truly unprecedented scale for any desktop application while retaining the same, familiar real-time reporting and usability.
The default crawl limit is now set at 5 million URLs in the SEO Spider, but it isn’t a hard limit, the SEO Spider is capable of crawling significantly more (with the right hardware). Here are 10 million URLs crawled, of 26 million (with 15 million sat in the queue) for example.

We have a hate for pagination, so we made sure the SEO Spider is powerful enough to allow users to view data seamlessly still. For example, you can scroll through 8 million page titles, as if it was 800.

The reporting and filters are all instant as well, although sorting and searching at huge scale will take some time.

It’s important to remember that crawling remains a memory intensive process regardless of how data is stored. If data isn’t stored in RAM, then plenty of disk space will be required, with adequate RAM and ideally SSDs. So fairly powerful machines are still required, otherwise crawl speeds will be slower compared to RAM, as the bottleneck becomes the writing speed to disk. SSDs allow the SEO Spider to crawl at close to RAM speed and read the data instantly, even at huge scale.
By default, the SEO Spider will store data in RAM (‘memory storage mode’), but users can select to save to disk instead by choosing ‘database storage mode’, within the interface (via ‘Configuration > System > Storage), based upon their machine specifications and crawl requirements.

Users without an SSD, or are low on disk space and have lots of RAM, may prefer to continue to crawl in memory storage mode. While other users with SSDs might have a preference to just crawl using ‘database storage mode’ by default. The configurable storage allows users to dictate their experience, as both storage modes have advantages and disadvantages, depending on machine specifications and scenario.
Please see our guide on how to crawl very large websites for more detail on both storage modes.
The saved crawl format (.seospider files) are the same in both storage modes, so you are able to start a crawl in RAM, save, and resume the crawl at scale while saving to disk (and vice versa).
Итоговая таблица с окончательными результатами тестирования:
| Программа | Итоговый балл | Бесплатное распространение | Дистрибутив (Мб) |
| Netpeak Spider | 92 | — | 11 |
| Screaming Frog SEO Spider | 89 | — | 228 |
| SiteAnalyzer | 75 | + | 9 |
| WebSite Auditor | 72 | — | 203 |
| Sitebulb | 70 | — | 162 |
| Forecheck | 68 | — | 12 |
| RiveSolutions SEO Spider | 62 | + | 85 |
| Visual SEO Studio | 52 | — | 10 |
| Comparser | 51 | — | 7 |
| Site Visualizer | 47 | — | 6 |
| A1 Website Analyzer | 45 | — | 8 |
| seoBOXX WebsiteAnalyser | 43 | — | 15 |
| IIS SEO Toolkit | 42 | + | 1 |
| Website Link Analyzer | 40 | — | 3 |
| PageWeight Desktop | 38 | — | 5 |
| Beam Us Up | 30 | + | 22 |
| Webbee | 28 | — | 48 |
| Darcy SEO Checker | 25 | — | 27 |
| WildShark SEO spider | 25 | + | 4 |
| Xenu | 18 | + | 1 |
| Smart SEO Auditor | 11 | — | 7 |
| LinkChecker | 9 | + | 11 |
Итог
Однозначно выявить победителя по скорости сканирования было весьма сложной задачей за счет того, что в разные моменты времени сканирования одной программой одного сайта, скорость его сканирования могла варьироваться от 40 до 60 секунд на 1 000 страниц, соответственно, для 100 000 URI итоговый результат мог отличаться на десятки минут, поэтому для итогового расчета мы брали усредненные данные за несколько сканирований (для некоторых программ число тестов достигало порядка десятка и могло растягиваться до нескольких дней).
Это к слову о качестве тестирования. Логично, для наиболее популярных сканеров мы выделяли больше времени на тесты, а наиболее «простым» хватало и одного прогона.
Подытоживая результаты тестирования 22 SEO-краулеров можно заключить, что итоговый ТОП-5 для лучших из лучших в 2021 году получился таким:
- платно
- платно
- бесплатно
- платно
- платно
Соответственно, из платных программ лучшей можно назвать Netpeak Spider, а из бесплатных – SiteAnalyzer.
Благодарим за внимание! Ждем ваши комментарии и отзывы по работе данных программ!
Другие статьи:
- Массовая проверка уникальности текстов на сайте
- Пакетная проверка скорости загрузки страниц сайта
- Перелинковка сайта: лучшие методы оптимизации внутренних ссылок