Мета теги страниц сайта: title, description, keywords, robots и другие
Содержание:
- NOFOLLOW в ссылках
- Alt атрибуты изображения
- Pages to set to noindex
- SEO best practices with robots meta directives
- Директивы Meta Robots, которые стоит использовать в SEO
- Метатеги для поисковых систем
- Мета тег description
- Коротко о главном
- What are robot meta tags?
- Как закрыть внешние ссылки от индексации
- The different robots meta tag values
NOFOLLOW в ссылках
Nofollow используется как значение атрибута rel в теге <a>. И отвечает за индексацию каждой конкретной ссылки на странице.
<a href=»url» rel=»nofollow»>ссылка</a>
Атрибут rel показывает отношение данного документа к документу, на который ссылается.
В данном случае, указывая атрибуту rel значение nofollow, мы просим поисковую систему не переходить по внешней ссылке, а также подчеркиваем то, что мы не отвечаем за содержание, на которое ссылаемся.
По ссылкам, оформленным с данным значением, не передается авторитет нашей страницы, другими словами не передается тИЦ и Page Rank. Однако стоит также учитывать и то, что в случае с PR вес все же уходит, но не на сайт, на который мы ссылаемся, а в никуда в прямом смысле этого слова. По поводу тИЦ точной информации о том, уходит вес или остается на сайте — нет.
Остановимся подробнее на распределении и передаче веса в Google.
Итак, абсолютно не важно, сколько ссылок у вас имеют атрибут rel=»nofollow», а сколько без него. Если на странице стоит 10 ссылок, то каждая ссылка получит часть авторитета вашей страницы, и каждая из них передаст этот вес, но если в одном случае вес передастся на конкретный сайт, то в другом случае – вес просто уйдет в никуда
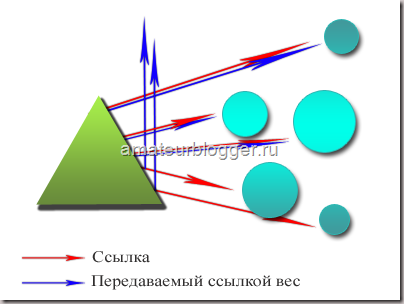
Давайте представим немного, как видит всемирную паутину поисковая система. Все сайты связаны между собой ссылками, абсолютно все. Первый ссылается на второй, второй на третий … тысячный на тысяча первый и миллион какой-то в итоге обязательно будет ссылаться на первый.
Таким образом цепочка замыкается, все сайты находятся в цикле, и вес, который передает первый сайт всегда возвращается к нему через сотни и тысячи других сайтов. Также не забываем, и я уже писала об этом в статье про перелинковку, что этот вес передается не единожды, а постоянно, при этом с течением времени вес становится только больше, все сильнее увеличивая свой авторитет. Именно на этом принципе строится перелинковка сайта.
Теперь представим, что первый сайт закрыл свои ссылки атрибутом rel=»nofollow». Вес не перейдет на второй сайт, а утечет в никуда, и второй сайт не получит ту часть веса, которую должен был, не сможет передать его дальше по цепочке, и в итоге, пройдя весь цикл, Х-какой-то сайт, который должен был передать вес на первый сайт, передаст его в значительно меньшем количестве, чем мог бы. Итак, каждый раз не получая ту часть веса, которую вы самостоятельно пускаете в никуда, закрывая свои ссылки атрибутом rel=»nofollow», сайт не может передать вам ее, из чего следует, что закрывая свои ссылки, вы сами лишаете себя увеличения веса, и такого показателя, как PR.
Чтобы было проще это понять, представим, что каждая ссылка передает вес, равным единице.
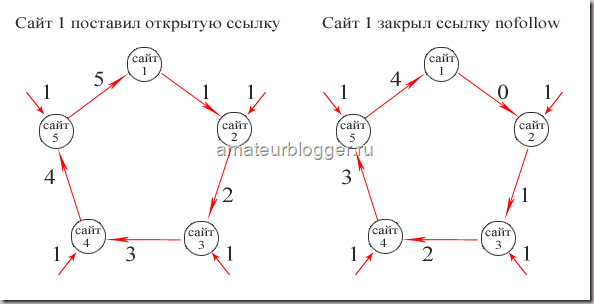
Таким образом, если первый сайт не закрыл ссылку атрибутом rel=»nofollow», то в конце цикла получит больший вес от входящих ссылок, чем в случае, если исходящие ссылки будут закрыты.
Но есть ситуации, когда действительно необходимо закрывать ссылки значением nofollow. Обратимся к источникам, Яндекс и Google, что они говорят по этому поводу?
Выдержка из раздела Помощь Яндекса:

Выдержка из раздела Справка Google:
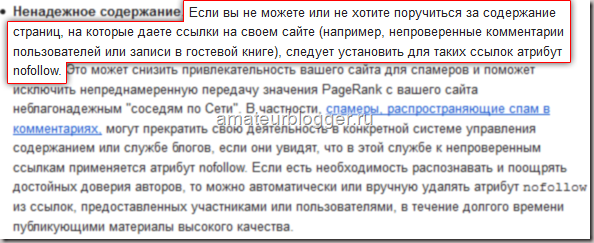
Мы должны закрывать ссылки в тех разделах своего сайта, где любой пользователь может оставить свою ссылку, за которую мы не сможем поручиться, гарантировать, что там качественное содержание.
Также мне хотелось бы уделить внимание ещё одному моменту. Некоторые ярые борцы за закрытые ссылки ставят rel=»nofollow» не только в самих ссылках, т.е
в теге , но и везде, на что только хватает фантазии. И в теге
Давайте не будем выдумывать свои собственные стандарты, а обратимся к существующим, которые разрабатывает международная организация W3C.
Значение rel=»nofollow» можно использовать только в теге , и в других тегах его использовать нельзя!
Итак, мы выяснили, когда стоит пользоваться атрибутом ссылки rel=»nofollow», а когда это не целесообразно. Также мы больше не будем вставлять его никуда, кроме одного единственного тега, обозначающего ссылку
Теперь уделим внимание тегу noindex.
Alt атрибуты изображения
Атрибут alt изображения добавляется к тегу изображения img для описания его содержимого. Альтернативные атрибуты важны с точки зрения внутренней оптимизации сайта по двум причинам:
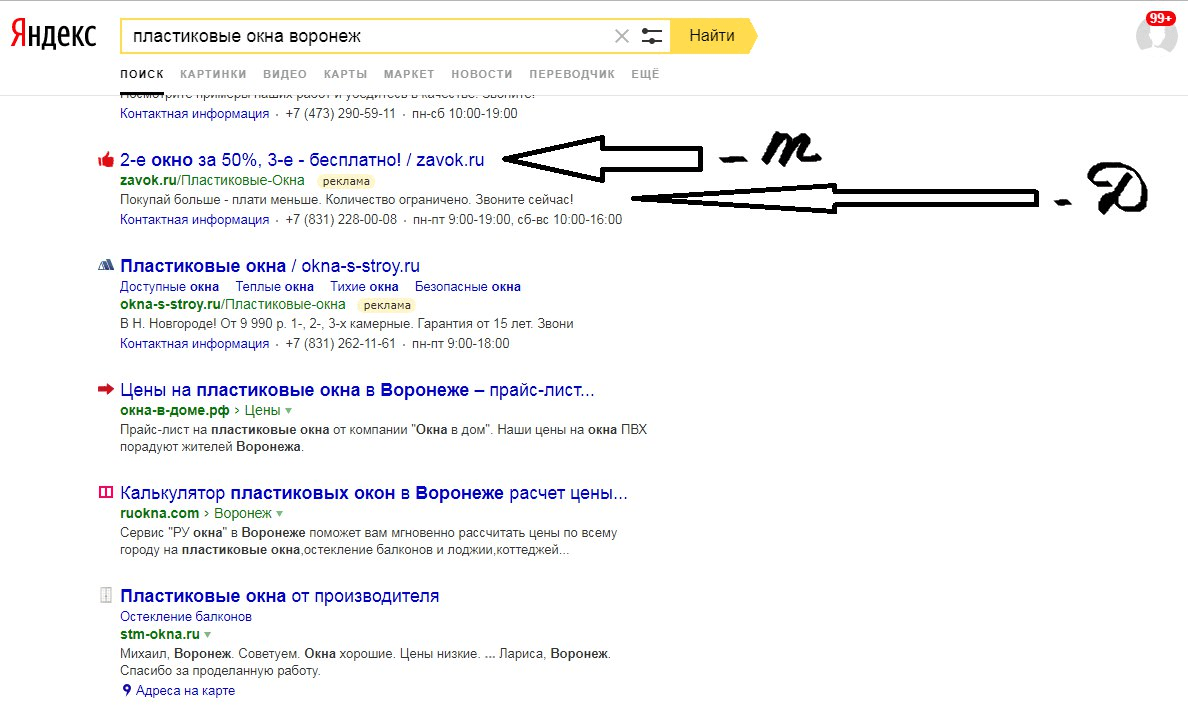
- Альтернативный текст показывается посетителям, если какое-либо конкретное изображение не может быть загружено (или если отображение картинок отключено).
- Атрибуты Alt обеспечивают контекст для роботов, потому что поисковые системы не могут «видеть» изображения.
На e-commerce сайтах изображения часто имеют решающее влияние на то, как посетитель взаимодействует со страницей
Поисковики так же прямо заявляют о важности этого тега
Например, Google в своих гайдах для вебмастеров пишет, что помощь поисковым системам в понимании того, что находится на картинках, и как они сочетаются с остальным контентом, помогает соотносить страницу сайта с подходящими поисковыми запросами.
Даже Мюллер писал у себя в Твиттере, что продуманное альтернативное описание изображения необычайно важно, если вы хотите занять высокое место в Google Картинках. Однако не забывайте о релевантности
Не только alt-текст, заголовки и подписи должны соответствовать изображению, но и сама картинка должна размещаться в тематическом контенте
Однако не забывайте о релевантности. Не только alt-текст, заголовки и подписи должны соответствовать изображению, но и сама картинка должна размещаться в тематическом контенте.
Оптимизация alt тега img для изображений
- Сделайте всё возможное, чтобы оптимизировать свои самые важные изображения (картинки товаров, инфографику, инструкции), которые могут получить хорошие позиции в поиске Google Images.
- Добавьте alt-текст на страницах, где не так много другого контента (кроме картинок).
- Делайте тег alt для изображений понятным и достаточно информативным, разумно используйте ключевые слова и убедитесь, что они естественным образом вписываются в содержание страниц.
Pages to set to noindex
If you are the only one writing for your blog, your author pages are probably 90% the same as your blog homepage. That’s of no use to Google and can be considered duplicate content. To prevent this kind of duplicate content you can choose to disable the author archive entirely. Here’s how to enable or disable it easily with Yoast SEO. If, for some reason, you’d like to keep it on your site, but out of the search results, you can it. Fortunately, with Yoast SEO, this is not very difficult either; just check how to noindex an author archive.
Certain (custom) post types
Sometimes a plugin or a web developer adds a custom post type that you don’t want to be indexed. At Yoast, for example, we use custom pages for our products, as we are not a typical online store selling physical products. So, we don’t need a product image, filters like dimensions and technical specifications on a tab next to the description. Therefore, we noindex the regular product pages WooCommerce outputs and are using our own pages. Indeed, we the product post type.
Relatedly, we’ve seen eCommerce solutions that added specifications like dimensions and weight as a custom post type as well. These pages are considered to be low-quality content. You’ll understand that these pages have no use for a visitor or Google, so need to be kept out of the search result pages too.
Thank you pages
That page serves no other purpose than to thank your customer/newsletter subscriber/first-time commenter. These pages are usually thin content pages, with upsell and social share options, but no value for someone using Google to find useful information. Therefore, those pages shouldn’t be in the search results pages.
Admin and login pages
Most login pages shouldn’t be in Google. But these are. Keep yours out of the index by adding a to it. Exceptions are the login pages that serve a community, like Dropbox or similar services. Just ask yourself if you would google one of your login pages if you were not in your company. If not, it’s probably safe to say that Google doesn’t need to index these login pages. Luckily, if you are running WordPress, you’re safe as the CMS noindexes your site’s login page automatically.
Internal search results
Internal search results are pretty much the last pages Google would want to send its visitors to. If you want to ruin a search experience, you link to other search pages, instead of an actual result. But the links on a search result page are still very valuable, you definitely want Google to follow them. So, all links should be followed, and the robots meta setting should be:
Yoast SEO makes sure your internal search pages are set to noindex by default. It’s one of Yoast SEO’s hidden features. This is not an editable setting, because it’s simply how it should be done according to the Google Guidelines, and we fully agree with them on this.
For developers only: If you do want to change this, this can be done by using one of our filters. An example can be found .
SEO best practices with robots meta directives
-
All meta directives (robots or otherwise) are discovered when a URL is crawled. This means that if a robots.txt file disallows the URL from crawling, any meta directive on a page (either in the HTML or the HTTP header) will not be seen and will, effectively, be ignored.
-
In most cases, using a meta robots tag with parameters «noindex, follow» should be employed as a way to to restrict crawling or indexation instead of using robots.txt file disallows.
-
It is important to note that malicious crawlers are likely to completely ignore meta directives and as such, this protocol does not make a good security mechanism. If you have private information that you don’t want to make publicly searchable, choose a more secure approach, such as password protection, to keep visitors from viewing confidential pages.
-
You do not need to use both meta robots and the x-robots-tag on the same page – doing so would be redundant.
Keep learning
- Robots.txt
- X-Robots-Tag: A Simple Alternate For Robots .txt and Meta Tag
- Controlling Search Engine Crawlers for Better Indexation and Rankings
- Robots Meta Tag and X-Robots-Tag HTTP Header Specifications
Put your skills to work
Moz Pro lets you run crawls, research and report on keyword ranking, and track your site’s SEO performance, including its accessibility, over time. Try it >>
Директивы Meta Robots, которые стоит использовать в SEO
Как мы видим из предыдущей таблицы, не все атрибуты метатега Robots поддерживаются поисковой системой Google, под которую оптимизируют сайты большинство разработчиков и SEO-специалистов. Поэтому рассмотрим те атрибуты метатега Robots, которые поддерживаются Google:
- nosnippet,
- noimageindex,
- noarchive,
- unavailable_after.
Все они прописываются в блоке страницы, к которой вы хотите применить те или иные инструкции по индексации.
Nosnippet
Для решения проблемы вам следует использовать инструкцию следующего вида:
Также важно учитывать, что атрибут nosnippet отключает и отображение расширенных сниппетов в результатах поиска. К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов
Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц
К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов. Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц.
Noimageindex
Директива noimageindex позволит скрыть графический контент на вашем сайте из результатов поиска по картинкам. Это может быть полезно, если вы, к примеру, хотите разместить на своём блоге уникальные изображения и при этом минимизировать риск воровства.
Чтобы запретить поисковым системам индексировать изображения, задайте в блоке html-документа следующую директиву:
Действие необходимо повторить с каждой страницей, которая содержит изображения, которые вы хотите скрыть от поисковиков. Учитывайте, что если другие сайты уже ссылались на ваши изображения, поисковики могут продолжать индексировать их.
Запрещая индексацию изображений, не забывайте о том, что поиск по картинкам может приносить хороший дополнительный трафик вашему сайту.
Noarchive
Вопреки распространённому мнению, директива noarchive никак не влияет на ранжирование — эту информацию подтвердил в своем Твиттере ведущий аналитик компании Google, специалист отдела качества поиска по работе с вебмастерами Джон Мюллер (John Mueller).
Директива unavailable_after наиболее актуальна для страниц с акционными предложениями. Так как по истечению времени действия акции они теряют свою актуальность, вы можете указать поисковикам дату крайнего срока индексации контента. Дату и время нужно указывать в формате RFC 850.
К примеру, если вам нужно исключить возможность индексации страницы после 25 марта 2019 года, используйте метатег следующего вида:
Отдельно отметим, что для правильного функционирования тега необходимо, чтобы он был прописан до первого обхода роботом. В таком случае запрос на удаление из поисковой выдачи займёт примерно сутки после указанной даты.
Метатеги для поисковых систем
Robots
Метатег указывает роботам поисковых систем, как сканировать и индексировать страницу.
Для конкретного бота можно задать свою инструкцию. Например, заменить robots на Googlebot для Гугла или на YandexBot для Яндекса.
Возможные указания:
- all – означает, что разрешена индексация и переход по ссылкам, аналогично index, follow;
- noindex – запрет индексации;
- index – разрешена индексация;
- nofollow – нельзя переходить по ссылкам;
- follow – можно переходить по ссылкам;
- noarchive – запрещено показывать ссылку на сохраненную копию в выдаче;
- noyaca – (для Яндекса) не использовать для сниппета описание из Яндекс.Каталога;
- nosnippet – (в Google) нельзя использовать для сниппета фрагмент текста и показывать видео;
- noimageindex – (в Google) запрет указания страницы как источника изображения;
- unavailable_after: – (в Google) после указанной даты будет прекращено сканирование и индексирование страницы;
- none – запрет индексации и перехода по ссылкам, аналогичен noindex, nofollow.
Description
Метатег name=«description» может использоваться поисковыми системами при формировании сниппета, поэтому он должен:
- точно описывать содержание страницы;
- вызывать желание кликнуть;
- включать продвигаемое ключевое слово.
В разных поисковых системах выводятся 160–240 символов.
Description для каждой продвигаемой страницы должен быть уникальным.
Keywords
Метатег name=«keywords» раньше использовался поисковыми системами при ранжировании, но из-за многочисленных манипуляций его значимость постоянно уменьшалась. Теперь большинство поисковиков его игнорируют. Google не поддерживает вообще, а Яндекс пишет, что может учитывать. Но на практике keywords давно не оказывает влияния, а его некорректное заполнение может привести к переспаму.
Существуют три подхода:
- оставлять пустым;
- писать конкретные фразы или отдельные слова через запятую;
- указать через пробел бессвязный набор слов, из которых могут быть составлены ключевые фразы.
Если принято решение прописать ключевые слова, важно не допускать спама. Ключевые слова должны характеризовать конкретную страницу и упоминаться в контенте
Ключевые слова должны характеризовать конкретную страницу и упоминаться в контенте.
Title
Title технически не является метатегом, но его часто относят к этой группе, потому что он содержит информацию, которая используется поисковыми системами и браузерами.
Данный HTML-тег важен для SEO: влияет на ранжирование и кликабельность по сниппету.
Классические рекомендации по заполнению метатега:
- использовать главное продвигаемое ключевое слово на странице;
- разместить ключ вначале;
- обеспечить уникальность внутри сайта;
- сделать привлекательным для пользователя;
- подобрать такую длину, чтобы заголовок не обрезался в сниппете.
Рекомендуема длина – 70–80 символов.
Мета тег description
Мета-описание (meta description) – также находится в <head> веб-страницы и обычно (хотя далеко не всегда) отображается в сниппете поисковой выдачи вместе с заголовком и URL-адресом страницы.
Например, это мета-описание данной статьи:
И да, само по себе метаописание не является фактором ранжирования. Но для любого вебмастера, старающегося увеличить количество переходов из поиска и улучшить поисковую выдачу своего бренда, это уникальная возможность.
Description занимает большую часть сниппета поисковой выдачи и приглашает пользователей щёлкнуть именно по вашей ссылке, обещая чёткое и комплексное решение их запроса.
Описание влияет на количество получаемых вами кликов, а также может улучшить CTR и снизить показатель отказов, если содержание страницы действительно соответствует обещаниям. Вот почему описание должно быть в равной степени реалистичным, привлекательным и чётко отражать содержание.
Если ваше описание содержит ключевые слова, использованные человеком в своём поисковом запросе, они будут выделены в поисковой выдаче жирным шрифтом
Это помогает вам привлечь внимание и сообщить пользователю, что именно он найдёт на вашей странице.
Невозможно поместить каждое ключевое слово, по которому вы хотите ранжироваться, в мета-описание, и в этом нет реальной необходимости – вместо этого напишите пару связных предложений, описывающих суть вашей страницы, включая основные ключевые слова.
Лучший способ выяснить, что необходимо поместить в мета тег Description для эффективного ранжирования – провести анализ конкурентов. Вбейте главный поисковый запрос вашей будущей или текущей страницы в Яндекс и Google. Посмотрите, кто и как заполнил описание, и возьмите себе всё самое лучшее из топа.
Мета совет
Мета-описание не обязательно должно состоять из одного-двух предложений. Вы можете добавить дополнительную информацию о странице, которая обрабатывается поисковиками и позволит выделиться в SERP.
Например:
- Для авторской статьи вы можете добавить дату публикации, имя автора.
- На странице продукта вы можете указать цену и дату изготовления товара.
Коротко о главном
Meta Robots — удобный инструмент, который позволяет управлять инструкциями по индексации сайта и его отдельных страниц. Однако зачастую его использование ограничивается атрибутами запрета индексации — noindex, nofollow.
На деле же он может использоваться как минимум с 4 директивами, которые полноценно воспринимаются поисковыми роботами Google и помогают решить разного рода SEO-задачи. В их числе — nosnippet, noimageindex, noarchive и unavailable_after.

Проверить директивы метатега Robots всего сайта или списка определённых URL удобнее всего с помощью Netpeak Spider. Программа покажет все возможные ошибки, связанные с метатегами, и предоставит данные об атрибутах в максимально наглядном виде.
Краулер программы выполняет глубокий анализ сайта в автоматическом режиме, получает полную его структуру и находит ошибки технической оптимизации. Умеет находить битые ссылки и редиректы, обнаруживать дублирование страниц, Title, Description, заголовков H1 и т.д — проверяет более 50 ключевых параметров. Настоятельно рекомендую!
Robots meta directives (sometimes called «meta tags«) are pieces of code that provide crawlers instructions for how to crawl or index web page content. Whereas robots.txt file directives give bots suggestions for how to crawl a website’s pages, robots meta directives provide more firm instructions on how to crawl and index a page’s content.
There are two types of robots meta directives: those that are part of the HTML page (like the meta robotstag) and those that the web server sends as HTTP headers (such as x-robots-tag). The same parameters (i.e., the crawling or indexing instructions a meta tag provides, such as «noindex» and «nofollow» in the example above) can be used with both meta robots and the x-robots-tag; what differs is how those parameters are communicated to crawlers.

Meta directives give crawlers instructions about how to crawl and index information they find on a specific webpage. If these directives are discovered by bots, their parameters serve as strong suggestions for crawler indexation behavior. But as with robots.txt files, crawlers don’t have to follow your meta directives, so it’s a safe bet that some malicious web robots will ignore your directives.
Below are the parameters that search engine crawlers understand and follow when they’re used in robots meta directives. The parameters are not case-sensitive, but do note that it is possible some search engines may only follow a subset of these parameters or may treat some directives slightly differently.
Как закрыть внешние ссылки от индексации
Для того чтобы запретить к индексации текстовые фрагменты, на сайте нужно использовать тег noindex
Важно знать, что этот тег способен закрывать только текстовые блоки. Картинки, баннеры, и другие элементы запретить к индексации с помощью этого тега нельзя
Многие люди совершают большую ошибку, когда заключают в этот тег ссылку. Поисковая система без проблем считывает и индексирует ссылку. В этом случае запрещён к индексации только анкор ссылки, так как это текст. Будьте внимательны.
Тег noindex прописывается в исходный код сайта. Имеет открывающий и закрывающий тег. Текст помещается между этими тегами.
Теперь подробнее:
Этот текст поисковые системы не отдадут на индексацию. А также тег noindex может выступать в роли метатега, который расположен в начале страницы и он отличается в корне. Если на странице расположен метатег noindex, в этом случае он запрещает индексирование всей страницы. При этом не только тексты, но и все что на ней находится – ссылки, картинки, баннеры, формы и так далее, всё это будет запрещено к индексации. Лучше всего для запрета индексация целых страниц использовать специальный файл robots.txt.
Как правильно ставить тег noindex
Вначале можно прочитать, что тег noindex создан исключительно для поисковых машин. То есть этот тег не является официальным тегом языка html. Именно поэтому HTML-редакторы могут показывать, что тег написан с ошибкой. Не пугайтесь, это происходит по причине того, что они просто не понимают этот тег и не считают его валидным. Но, так или иначе, его без проблем прочитают поисковые машины.
И ещё важно знать и запомнить, на тег noindex будет реагировать только поисковая система Яндекс, так как он его и создал. Поисковая система Google не реагирует на такой тег вообще.. Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега
Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже
Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега. Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже.
Владельцам сайта не запрещается манипулировать тегами, можно не смотреть за их вложенностью, noindex будет работать при любом раскладе. Об этом пишет сам Яндекс. Главное, быть внимательным при работе с этими тегами, так как если вы забудете поставить закрывающий тег, схема работать не будет. В этом случае поисковая система Яндекс проиндексирует и отдаст всё что есть на странице в выдачу.
Как скрыть ссылки от индексации
В случае когда в тег ссылки добавить отдельный, дополнительный атрибут rel=”nofollow”, это будет означать, что ссылка не будет проиндексирована поисковым роботом. Вот пример как это выглядит в коде HTML:
Этот параметр очень важен для тех сайтов, которые не хотят делиться весом своего ресурса с другими WEB-проектами
Но также важно запомнить, что он не оставляет этот вес и у себя, по сути, он просто сгорает и не достаётся никому
Если же ссылку использовать без этого тега nofollow, то вес страницы, через эту ссылку уйдёт на другой сайт
Исходя из этого, важно понимать, что если внести этот атрибут во все ссылки, которые уходят на другие сайты, сайт потеряет в весе
Как работает этот атрибут nofollow на примере:
Конечно, если ссылка ссылается на страницу в рамках одного сайта или блога, то проставлять это свойство бесполезно и даже вредно. Это можно использовать только в тех случаях, когда стоит задача не передавать вес отдельным страницам сайта. Например, если есть продающая страница, куда должен поступать весь трафик, имеет ссылку на внутреннюю страницу, например, ответы на вопросы, то, конечно, лучше эту ссылку поместить в атрибут nofollow.
Как использовать тег noindex и nofollow одновременно
Данные теги не конфликтуют между собой, поэтому совершенно спокойно можно использовать их одновременно на одной странице или участке текста. В этом случае и текст и ссылка не будет доступна к индексации
Но важно не забывать, что текст будет скрыт только для поисковой системы Яндекс
На этом сегодня всё, всем удачи и до новых встреч!
The different robots meta tag values
The following values (‘parameters’) can be placed on their own, or together in the attribute of tag (separated by a comma), to control how search engines interact with your page.
Scroll down for an overview of which search engines support which specific parameters.
- index
- Allow search engines to add the page to their index, so that it can be discovered by people searching.
- Note: When there are no directives relating to indexing, this is assumed to be the default.
- noindex
- Disallow search engines from adding this page to their index, and therefore disallow them from showing it in their results.
- Note: Informal messaging from Google suggests that, if a page is set to for a long period of time, it may also be treated as if it were also set to . The precise mechanics of this are unclear, and it’s unclear whether other search engines behave similarly.
- follow
- Tells the search engines that it may follow links on the page, to discover other pages.
- Note: When there are no directives relating to following links, this is assumed to be the default.
- nofollow
- Tells the search engines robots not to ‘endorse’ (pass equity through) any links on the page. Note that this includes all links on the page, including, e.g., those in navigation elements, links to images or other resources, and so on.
- Note: It’s unclear (and inconsistent between search engines) whether this attribute prevents search engines from following links, or just prevents them from assigning any value to those links.
- none
- A shortcut for .
- all
- A shortcut for .
- Note: This is assumed by default on all pages, and does nothing if specified.
- noimageindex
- Disallow search engines from indexing images on the page.
- Note: If images are linked to directly from elsewhere, search engines can still index them, so using an X-Robots-Tag HTTP header is generally a better idea.
- noarchive
- Prevents the search engines from showing a cached copy of this page in their search results listings.
- nocache
- Same as , but only used by MSN/Live.
- nosnippet
- Prevents the search engines from showing a text or video snippet (i.e., a ) of this page in the search results, and prevents them from showing a cached copy of this page in their search results listings.
- Note: Snippets may still show an image thumbnail, unless is also used.
- nositelinkssearchbox
- Prevents the search engine from showing an inline search box for your site.
- nopagereadaloud
- Prevents the search engine from reading your page’s content aloud via voice services/results.
- notranslate
- Prevents search engines from showing translations of the page in their search results.
- max-snippet:
- Sets a maximum number of characters for the meta description.
- Note: Omitting this tag may result in an implied value of . A default value of should be set to imply ‘no limit’.
- max-video-preview:
- Sets a maximum number of seconds for a video in a preview.
- Note: Omitting this tag may result in an implied value of . A default value of should be set to imply ‘no limit’.
- max-image-preview:
- Sets a maximum image size for use in a preview (, or ).
- Note: Omitting this tag may result in an implied value of .
- rating
- Indicates that a page contains adult material.
- unavailable_after
- Tells search engines a date/time after which they should not show it in search results; a ‘timed’ version of .
- Note: Must be in format (e.g., ).
- noyaca
- Prevents the search results snippet from using the page description from the Yandex Directory.
- Note: Only supported by Yandex.
noydir- Blocks Yahoo from using the description for this page in the Yahoo directory as the snippet for your page in the search results.
- Note: Since Yahoo closed its directory this tag is deprecated, but you might come across it once in awhile.