Файл robots.txt и мета-тег robots
Содержание:
- Чем может грозить неправильно составленный роботс
- Комментарии в robots.txt
- Другие примеры настройки Robots.txt
- Формат файла robots.txt
- Как создать и редактировать robots.txt
- Для чего предназначен?
- Пример правильного файла robots.txt для сайта на 1С-Битрикс
- Создание и редактирование robots.txt
- Как создать и редактировать robots.txt
- What is a robots.txt file?
- Как создать и редактировать robots.txt
- Robots.txt для WordPress
- Примеры файлов robots.txt
- Создание robots.txt
- Как проверить эффективность файла robots.txt
- Атрибут rel=“nofollow”
- Как проверить работу robots.txt
- Что такое файл robots txt, зачем он нужен и за что он отвечает
- Ошибочные рекомендации других блогеров для Robots.txt на WordPress
- Как проверить файл?
- Команда «Allow:» – разрешение индексации в robots.txt
- Резюме
- Для чего нужен этот файл
- Robots.txt для Joomla
Чем может грозить неправильно составленный роботс
Некоторые при создании сайта на WordPress ставят галочку, чтобы система закрывала сайт от индексации (и забывают потом убрать её). Тогда Вордпресс автоматом ставит вам такой роботс, чтобы поисковики не включали ваш сайт в индекс, и это — самая страшная ошибка. Те страницы, на которые вы намерены получать трафик, обязательно должны быть открыты для индексации.
Потом, если вы не закрыли ненужные страницы от индексации, в индекс может попасть, как я уже говорил выше, очень много мусора (ненужных страниц), и они могут занять в индексе место нужных страниц.
Вообще, если вкратце, неправильный роботс грозит вам тем, что часть страниц не попадет в поиск и вы лишитесь части посетителей.
Комментарии в robots.txt
Комментарии в файле robots.txt пишутся после знака # и игнорируются поисковыми системами. Как правило, комментарии используются для обозначения причин открытия или закрытия для индексации определенных страниц, чтобы в будущем оптимизатору были понятны причины тех или иных правок в файле.
В данной статье вы уже встречались с комментирование, которое поясняло использование директив. Вот еще один пример:
#Это файл robots.txt. Все что написано в данной строке, роботы не прочтут User-agent: Yandex #Комментарий Disallow: /pink #закрыл от индексации, так как на странице неуникальный контент
Другие примеры настройки Robots.txt
User-agent: Googlebot Disallow: /*?* # закрываем от индексации все страницы с параметрами Disallow: /users/*/photo/ # закрываем от индексации адреса типа "/users/big/photo/", "/users/small/photo/" Disallow: /promo* # закрываем от индексации адреса типа "/promo-1", "/promo-site/" Disallow: /templates/ #закрываем шаблоны сайта Disallow: /*?print= # версии для печати Disallow: /*&print=
Запрещаем сканировать сервисам аналитики Majestic, Ahrefs, Yahoo!
User-agent: MJ12bot Disallow: / User-agent: AhrefsBot Disallow: / User-agent: Slurp Disallow: /
Настройки robots для Opencart:
User-agent: * Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.php?route=product/product*&manufacturer_id= Disallow: /admin Disallow: /catalog Disallow: /download Disallow: /registration Disallow: /system Disallow: /*?sort= Disallow: /*&sort= Disallow: /*?order= Disallow: /*&order= Disallow: /*?limit= Disallow: /*&limit= Disallow: /*?filter_name= Disallow: /*&filter_name= Disallow: /*?filter_sub_category= Disallow: /*&filter_sub_category= Disallow: /*?filter_description= Disallow: /*&filter_description= Disallow: /*?tracking= Disallow: /*&tracking= Allow: /catalog/view/theme/default/stylesheet/stylesheet.css Allow: /catalog/view/theme/default/css/main.css Allow: /catalog/view/javascript/font-awesome/css/font-awesome.min.css Allow: /catalog/view/javascript/jquery/owl-carousel/owl.carousel.css Allow: /catalog/view/javascript/jquery/owl-carousel/owl.carousel.min.js
Формат файла robots.txt
Файл robots.txt должен состоять как минимум из двух обязательных записей. Первой идет директива User-agent указывающая, какой поисковый робот должен следовать идущим дальше инструкциям. Значением может быть имя робота (googlebot, Yandex, StackRambler) или символ * в случае если вы обращаетесь сразу ко всем роботам. Например:
Название робота вы можете найти на сайте соответствующего поисковика. Дальше должна идти одна или несколько директив Disallow. Эти директивы сообщают роботу, какие файлы и папки индексировать запрещено. Например, следующие строки запрещают роботам индексировать файл feedback.php и каталог cgi-bin:
Также можно использовать только начальные символы файлов или папок. Строка Disallow: /forum запрещает индексирование всех файлов и папок в корне сайта, имя которых начинается на forum, например, файл http://site.ru/forum.php и папку http://site.ru/forum/ со всем ее содержимым. Если Disallow будет пустым, то это значит, что робот может индексировать все страницы. Если значением Disallow будет символ /, то это значит что весь сайт индексировать запрещено.
Для каждого поля User-agent должно присутствовать хотя бы одно поле Disallow. То-есть, если вы не собираетесь ничего запрещать для индексации, то файл robots.txt должен содержать следующие записи:
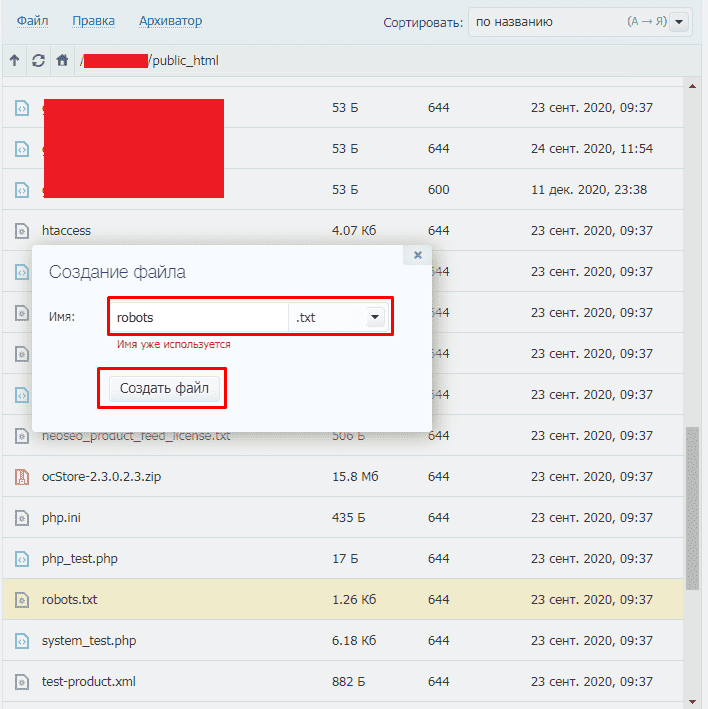
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.

Если его нет, то достаточно создать новый файл.
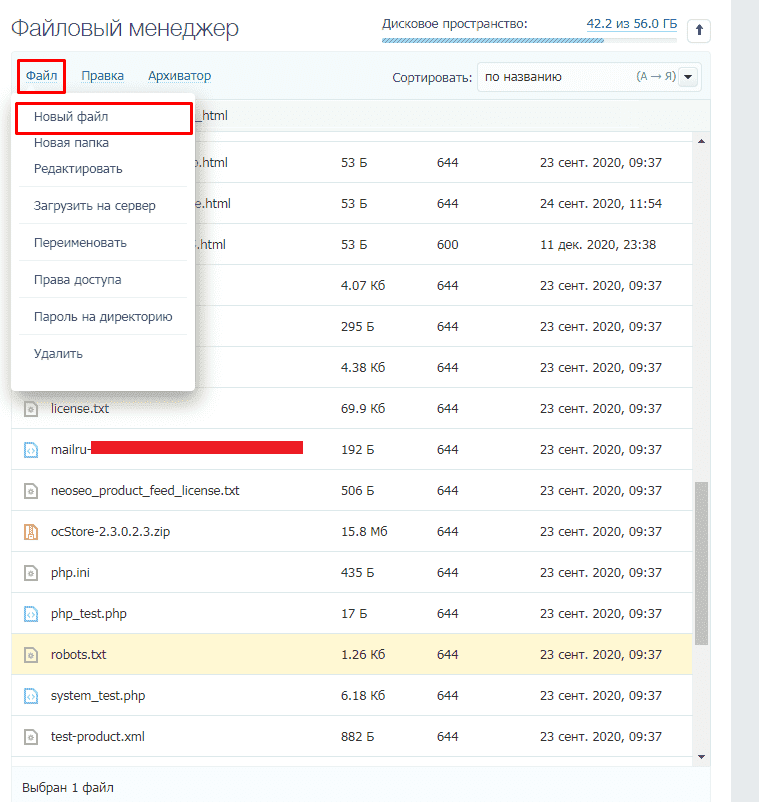
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814

WordPress;
Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Для чего предназначен?
В предисловии я уже описал, что это такое. Теперь расскажу, зачем он нужен. Robots.txt – небольшой текстовой файл, который хранится в корне сайта. Он используется поисковыми системами. В нем четко прописаны правила индексации, т. е. какие разделы сайта нужно индексировать (добавлять в поиск), а какие – нет.

Обычно от индексации закрываются технические разделы сайта. Изредка в черный список попадают неуникальные страницы (копипаст политики конфиденциальности тому пример). Здесь же “роботам объясняются” принципы работы с разделами, которые нужно индексировать. Очень часто прописывают правила для нескольких роботов отдельно. Об этом мы и поговорим далее.
При правильной настройке robots.txt ваш сайт гарантированно вырастет в позициях поисковых систем
Роботы будут учитывать только полезный контент, обделяя вниманием дублированные или технические разделы
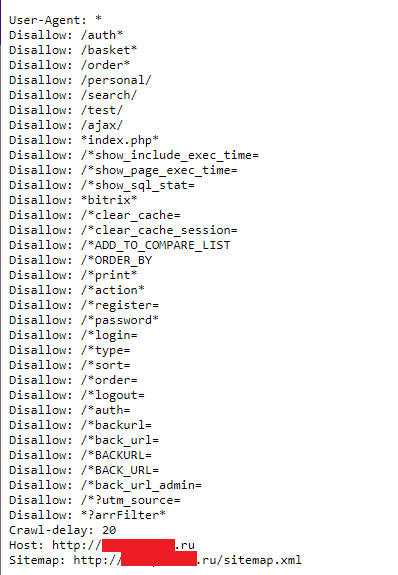
Пример правильного файла robots.txt для сайта на 1С-Битрикс
- User-agent: *
- Disallow: /auth*
- Disallow: /basket*
- Disallow: /order*
- Disallow: /personal/
- Disallow: /search/
- Disallow: /test/
- Disallow: /ajax/
- Disallow: *index.php*
- Disallow: /*show_include_exec_time=
- Disallow: /*show_page_exec_time=
- Disallow: /*show_sql_stat=
- Disallow: *bitrix*
- Disallow: /*clear_cache=
- Disallow: /*clear_cache_session=
- Disallow: /*ADD_TO_COMPARE_LIST
- Disallow: /*ORDER_BY
- Disallow: /*print*
- Disallow: /*action*
- Disallow: /*register=
- Disallow: /*password*
- Disallow: /*login=
- Disallow: /*type=
- Disallow: /*sort=
- Disallow: /*order=
- Disallow: /*logout=
- Disallow: /*auth=
- Disallow: /*backurl=
- Disallow: /*back_url=
- Disallow: /*BACKURL=
- Disallow: /*BACK_URL=
- Disallow: /*back_url_admin=
- Disallow: /*?utm_source=
- Disallow: *?arrFilter*
- Host: https://seopulses.ru
- Sitemap: https://seopulses.ru/sitemap_index.xml
Создание и редактирование robots.txt
- Если у вас еще нет файла, то нужно создать его с нуля. Откройте самый простой текстовый редактор (но не MS Word, т.к. нам нужен именно простой текстовый формат), к примеру, Блокнот (Windows) или TextEdit (Mac).
Примечания:
- Если, например, сайт реализован на CMS WordPress, то по умолчанию, вы не сможете найти его в корне сайта, так как «из коробки» его наличие не предусмотрено. Поэтому для редактирования его придется создать заново.
- Регистр имени файла важен! Название robots.txt указывается исключительно строчными буквами. Также убедитесь, что вы написали корректное название, НЕ «Robots» или «robot» – это наиболее частые ошибки при создании файла.
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
WordPress;
Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
What is a robots.txt file?
Robots.txt is a text file webmasters create to instruct web robots (typically search engine robots) how to crawl pages on their website. The robots.txt file is part of the the robots exclusion protocol (REP), a group of web standards that regulate how robots crawl the web, access and index content, and serve that content up to users. The REP also includes directives like meta robots, as well as page-, subdirectory-, or site-wide instructions for how search engines should treat links (such as “follow” or “nofollow”).
In practice, robots.txt files indicate whether certain user agents (web-crawling software) can or cannot crawl parts of a website. These crawl instructions are specified by “disallowing” or “allowing” the behavior of certain (or all) user agents.
Basic format:
User-agent: Disallow:
Together, these two lines are considered a complete robots.txt file — though one robots file can contain multiple lines of user agents and directives (i.e., disallows, allows, crawl-delays, etc.).
Within a robots.txt file, each set of user-agent directives appear as a discrete set, separated by a line break:

In a robots.txt file with multiple user-agent directives, each disallow or allow rule only applies to the useragent(s) specified in that particular line break-separated set. If the file contains a rule that applies to more than one user-agent, a crawler will only pay attention to (and follow the directives in) the most specific group of instructions.
Here’s an example:

Msnbot, discobot, and Slurp are all called out specifically, so those user-agents will only pay attention to the directives in their sections of the robots.txt file. All other user-agents will follow the directives in the user-agent: * group.
Example robots.txt:
Here are a few examples of robots.txt in action for a www.example.com site:
Blocking all web crawlers from all content
User-agent: * Disallow: /
Using this syntax in a robots.txt file would tell all web crawlers not to crawl any pages on www.example.com, including the homepage.
Allowing all web crawlers access to all content
User-agent: * Disallow:
Using this syntax in a robots.txt file tells web crawlers to crawl all pages on www.example.com, including the homepage.
Blocking a specific web crawler from a specific folder
User-agent: Googlebot Disallow: /example-subfolder/
This syntax tells only Google’s crawler (user-agent name Googlebot) not to crawl any pages that contain the URL string www.example.com/example-subfolder/.
Blocking a specific web crawler from a specific web page
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
This syntax tells only Bing’s crawler (user-agent name Bing) to avoid crawling the specific page at www.example.com/example-subfolder/blocked-page.html.
How does robots.txt work?
Search engines have two main jobs:
- Crawling the web to discover content;
- Indexing that content so that it can be served up to searchers who are looking for information.
To crawl sites, search engines follow links to get from one site to another — ultimately, crawling across many billions of links and websites. This crawling behavior is sometimes known as “spidering.”
After arriving at a website but before spidering it, the search crawler will look for a robots.txt file. If it finds one, the crawler will read that file first before continuing through the page. Because the robots.txt file contains information about how the search engine should crawl, the information found there will instruct further crawler action on this particular site. If the robots.txt file does not contain any directives that disallow a user-agent’s activity (or if the site doesn’t have a robots.txt file), it will proceed to crawl other information on the site.
Other quick robots.txt must-knows:
(discussed in more detail below)
-
In order to be found, a robots.txt file must be placed in a website’s top-level directory.
-
Robots.txt is case sensitive: the file must be named “robots.txt” (not Robots.txt, robots.TXT, or otherwise).
-
The /robots.txt file is a publicly available: just add /robots.txt to the end of any root domain to see that website’s directives (if that site has a robots.txt file!). This means that anyone can see what pages you do or don’t want to be crawled, so don’t use them to hide private user information.
-
Each subdomain on a root domain uses separate robots.txt files. This means that both blog.example.com and example.com should have their own robots.txt files (at blog.example.com/robots.txt and example.com/robots.txt).
-
It’s generally a best practice to indicate the location of any sitemaps associated with this domain at the bottom of the robots.txt file. Here’s an example:

Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
WordPress;
Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Robots.txt для WordPress
Для создания файла нам нужно точно так же забросить robots.txt в корень сайта. Изменять его содержимое в таком случае можно будет с помощью все тех же FTP и файловых менеджеров.
Есть и более удобный вариант – создать файл с помощью плагинов. В частности, такая функция есть у Yoast SEO. Править роботс прямо из админки куда удобнее, поэтому сам я использую именно такой способ работы с robots.txt.
Как вы решите создать этот файл – дело ваше, нам важнее понять, какие именно директивы там должны быть. На своих сайтах под управлением WordPress использую такой вариант:
User-agent: * # правила для всех роботов, за исключением Гугла и Яндекса
Disallow: /cgi-bin # папка со скриптами
Disallow: /? # параметры запросов с домашней страницы
Disallow: /wp- # файлы самой CSM (с приставкой wp-)
Disallow: *?s= # \
Disallow: *&s= # все, что связано с поиском
Disallow: /search/ # /
Disallow: /author/ # архивы авторов
Disallow: /users/ # и пользователей
Disallow: */trackback # уведомления от WP о том, что на вас кто-то ссылается
Disallow: */feed # фид в xml
Disallow: */rss # и rss
Disallow: */embed # встроенные элементы
Disallow: /xmlrpc.php # WordPress API
Disallow: *utm= # UTM-метки
Disallow: *openstat= # Openstat-метки
Disallow: /tag/ # тэги (при наличии)
Allow: */uploads # открываем загрузки (картинки и т. д.)
User-agent: GoogleBot # для Гугла
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js # открываем JS-файлы
Allow: /*/*.css # и CSS
Allow: /wp-*.png # и картинки в формате png
Allow: /wp-*.jpg # \
Allow: /wp-*.jpeg # и в других форматах
Allow: /wp-*.gif # /
Allow: /wp-admin/admin-ajax.php # работает вместе с плагинами
User-agent: Yandex # для Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # чистим UTM-метки
Clean-Param: openstat # и про Openstat не забываем
Sitemap: # прописываем путь до карты сайта
Host: https://site.ru # главное зеркало
Внимание! При копировании строк в файл – не забудьте удалить все комментарии (текст после #). Такой вариант robots.txt наиболее популярен среди вебмастеров, которые используют WP
Идеальный ли он? Нет. Вы можете попытаться что-то добавить или наоборот убрать. Но учтите, что при оптимизации текстовика роботов нередки ошибки. О них мы поговорим далее
Такой вариант robots.txt наиболее популярен среди вебмастеров, которые используют WP. Идеальный ли он? Нет. Вы можете попытаться что-то добавить или наоборот убрать. Но учтите, что при оптимизации текстовика роботов нередки ошибки. О них мы поговорим далее.
Примеры файлов robots.txt
1. Разрешаем всем роботам индексировать все документы сайта:
2. Запрещаем всем роботам индексировать сайт:
3. Запрещаем роботу поисковика Google индексировать файл feedback.php и содержимое каталога cgi-bin:
4. Разрешаем всем роботам индексировать весь сайт, а роботу поисковика Яндекс запрещаем индексировать файл feedback.php и содержимое каталога cgi-bin:
5. Разрешаем всем роботам индексировать весь сайт, а роботу Яндекса разрешаем индексировать только предназначенную для него часть сайта:
Пустые строки разделяют ограничения для разных роботов. Каждый блок ограничений должен начинаться со строки с полем User-Agent, указывающей робота, к которому относятся данные правила индексации сайта.
Создание robots.txt
Чтобы создать файл, достаточно воспользоваться стандартным функционалом вашей операционной системы, после чего выгрузить его на сервер через FTP. Где он лежит (на сервере) догадаться несложно – в корне. Обычно эта папка называется public_html.
Вы без труда сможете попасть в нее с помощью любого FTP-клиента (например, FileZilla) или встроенного файлового менеджера. Естественно, мы не будем загружать на сервер пустой роботс. Впишем туда несколько основных директив (правил).
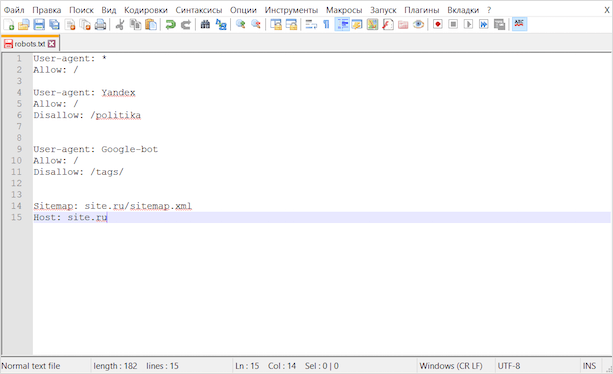
User-agent: *
Allow: /
Используя эти строки в своем файле robots, вы обратитесь ко всем роботам (директива User-agent), позволив им индексировать ваш сайт всецело и полностью (включая все тех. страницы Allow: /)
Конечно же, такой вариант нам не особо подходит. Файл будет не особо полезен для оптимизации под поисковики. Он определенно нуждается в грамотной настройке. Но перед этим мы рассмотрим все основные директивы и значения robots.txt.
Как проверить эффективность файла robots.txt
Для того, чтобы проанализировать действие файла в Яндексе, следует перейти на соответствующую страницу в разделе Яндекс.Вебмастер. В диалоговом окне укажите имя сайта и нажмите кнопку «загрузить».
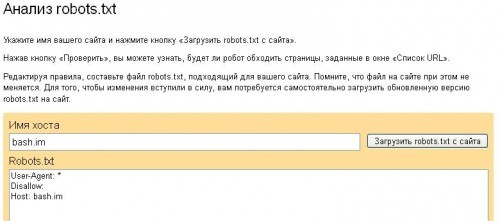
Система проанализирует файл robots.txt проверка покажет, будет ли поисковый робот обходить страницы, запрещенные к индексации. Если возникли проблемы, директивы можно отредактировать и проверить прямо в диалоговом окне. Правда после этого вам придётся скопировать отредактированный текст и вставить в свой файл robots.txt в корневом каталоге.
Аналогичную услугу предоставляет сервис «Инструменты для веб-мастеров» от поисковика Google.
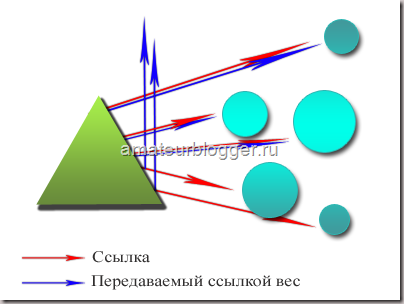
Атрибут rel=“nofollow”
Что такое атрибут rel=“nofollow”
rel=“nofollow” — это атрибут ссылки <a></a>, который закрывает от поисковых роботов определенные ссылки, во избежание их индексации.
Атрибут rel=“nofollow” используется в разметке в таком виде:
<a href="http://mysite.com/" rel="nofollow">название ссылки</a>
Случаи использования rel=“nofollow”
- закрытие внешних ссылок или крауд-ссылок, когда вы не можете отвечать за содержание и надежность контента;
- закрытие внутренних ссылок служебных страниц, которые предназначены для регистрации или входа в личный профиль;
- закрытие проплаченных рекламных ссылок с атрибутом rel=”sponsored”, что убережет ваш сайт от возможных санкций со стороны поисковых систем.
В описанных случаях лучше скрывать ссылки от роботов и грамотно распределять ссылочный вес на сайте, что поможет сэкономить им краулинговый бюджет.
Краулинговый бюджет — это определенное количество страниц на сайте, с которым поисковые роботы могут справится за одну проверку на ресурсе.
Какой вес у ссылки с атрибутом rel=“nofollow”?
Весом ссылки называют относительный показатель, который влияет на ранжирование сайта в поисковой выдаче. Чем выше вес, тем приоритетнее ссылка для роботов.
Нужно понимать что ссылка по факту будет просмотрена, но будет иметь гораздо меньше веса, сравнительно с остальными. Этот факт говорит нам что на ранжирование страниц, ссылка с данным атрибутом, практически не повлияет.
Исключения есть. Это случаи когда мы ссылаемся на социальные сети, такие как: Twitter и Facebook. Google попросту игнорирует атрибут rel=“nofollow” и вносит в общий index.
Детальнее об этом вы можете прочитать в официальной документации от Google и Yandex:
https://support.google.com/webmasters/answer/96569https://yandex.ru/support/webmaster/controlling-robot/html.xml
Как проверить работу robots.txt
Стандартный способ проверить через сервис yandex webmaster. Для лучшего анализа нужно зарегистрировать и установить на сайт сервис. Вверху видим загрузившийся robots, нажимаем проверить.
 Проверка документа в yandex
Проверка документа в yandex
Ниже появится блок с ошибками, если их нет то переходим к следующему шагу, если неверно отображается команда, то исправляем и снова проверяем.
 Отсутствие ошибок в валидаторе
Отсутствие ошибок в валидаторе
Проверим правильно ли Яндекс обрабатывает команды, спускаемся чуть ниже, введем два запрещенных и разрешенных адреса, не забываем нажать проверить. На снимке видим что инструкция сработала, красным помечено что вход запрещен, а зеленой галочкой, что индексирование записей разрешена.
 Проверка папок и страниц в яндексе
Проверка папок и страниц в яндексе
Проверили, все срабатывает, перейдем к следующему способу это настройка robots с помощью плагинов. Если процесс не понятен, то смотрите наше видео.
Что такое файл robots txt, зачем он нужен и за что он отвечает
 Файл robots txt, это текстовый файл, который содержит инструкции для поисковых роботов. Перед обращением к страницам Вашего блога, робот ищет первым делом файл robots, поэтому он так важен. Файл robots txt это стандарт для исключения индексации роботом тех или иных страниц. От файла robots txt будет зависеть попадание в выдачу Ваших конфиденциальных данных. Правильный robots txt для сайта поможет в его продвижении, поскольку он является важным инструментов во взаимодействии Вашего сайта и поисковых роботов.
Файл robots txt, это текстовый файл, который содержит инструкции для поисковых роботов. Перед обращением к страницам Вашего блога, робот ищет первым делом файл robots, поэтому он так важен. Файл robots txt это стандарт для исключения индексации роботом тех или иных страниц. От файла robots txt будет зависеть попадание в выдачу Ваших конфиденциальных данных. Правильный robots txt для сайта поможет в его продвижении, поскольку он является важным инструментов во взаимодействии Вашего сайта и поисковых роботов.
Не зря файл robots txt называют важнейшим инструментом SEO, этот маленький файл напрямую влияет на индексацию страниц сайта и сайта в целом. И наоборот, неправильный robots txt может исключить некоторые страницы, разделы или сайт в целом из поисковой выдачи. В этом случае можно иметь и 1000 статей на блоге, а посетителей на сайте просто не будет, будут чисто случайные прохожие.
На Яндекс вебмастере есть обучающее видео, в котором Яндекс сравнивает файл роботс тхт с коробкой Ваших личных вещей, которые Вы не хотите никому показывать. Чтобы посторонние не заглядывали в эту коробку, Вы её заклеиваете скотчем и пишете на ней – «Не открывать».
Роботы, как воспитанные личности, эту коробку не открывают и другим не смогут рассказать, что там находится. Если файла robots txt нет, то робот поисковой системы считает, что все файлы доступные, он откроет коробку, всё посмотрит и другим расскажет, что лежит в коробке. Чтобы робот не лазил в этот ящик, надо запретить ему туда лазить, делается это с помощью директивы Disallow, что переводится с английского – запретить, а Allow – разрешить.
Это обычный txt файл, который составляется в обычном блокноте или программе NotePad++, файл, который предлагает роботам не индексировать определённые страницы на сайте. Для чего это нужно:
- правильно составленный файл robots txt не позволяет роботам индексировать всякий мусор и не забивать поисковую выдачу ненужным материалом, а также не плодить дубли страниц, что является очень вредным явлением;
- не позволяет роботам индексировать информацию, которая нужна для служебного пользования;
- не позволяет роботам шпионам воровать конфиденциальные данные и использования их для отправки спама.
Это не означает, что мы что-то хотим спрятать от поисковиков, что-то тайное, просто эта информация не несёт ценности ни для поисковиков, ни для посетителей. Например, страница логина, RSS ленты и т.д. Кроме того, файл robots txt указывает зеркало сайта, а также карту сайта. По умолчанию на сайте, который делается на WordPress, файла robots txt нет. Поэтому нужно создать robots txt файл и залить его в корневую папку Вашего блога, в данной статье мы рассмотрим robots txt для WordPress, его создание, корректировку и заливку на сайт. Итак, сначала мы узнаем, где находится файл robots txt?
Ошибочные рекомендации других блогеров для Robots.txt на WordPress
-
Использовать правила только для User-agent: *
Для многих поисковых систем не требуется индексация JS и CSS для улучшения ранжирования, кроме того, для менее значимых роботов вы можете настроить большее значение Crawl-Delay и снизить за их счет нагрузку на ваш сайт. -
Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt -
Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Однако подобные советы я находил даже в статье с пафосным названием «Самые правильный robots для WordPress 2018»! Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше. -
Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика -
Закрывать от индексации страницы пагинации /page/
Это делать не нужно. Для таких страниц настраивается тег rel=»canonical», таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса. -
Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. -
Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например: — по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше
Как проверить файл?
Для этих целей лучше использовать специальные сервисы от Yandex и Google, т. к. эти поисковые системы являются наиболее популярными и востребованными (чаще всего единственно используемыми), такие поисковики как Bing, Yahoo или Rambler рассматривать нет смысла.
Для начала рассмотрим вариант с Яндексом. Заходим в Вебмастер. После чего в Инструменты – Анализ robots.txt.

Здесь вы сможете проверить файл на ошибки, а также проверить в реальном времени, какие страницы открыты для индексации, а какие – нет. Весьма удобно.
У Гугла есть точно такой же сервис. Идем в Search Console. Находим вкладку Сканирование, выбираем – Инструмент проверки файла robots.txt.
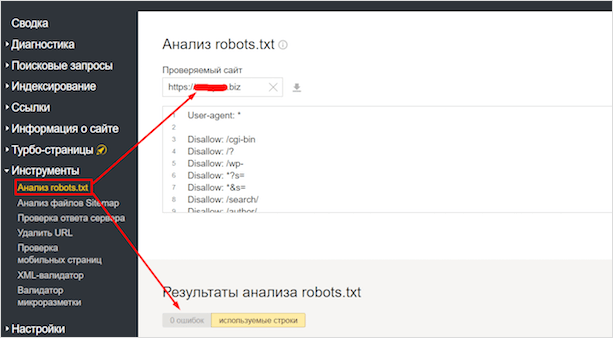
Здесь точно такие же функции, как и в отечественном сервисе.
Обратите внимание, что он показывает мне 2 ошибки. Связано это с тем, что Гугл не распознает директивы очистки параметров, которые я указал для Яндекса:. Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstat
Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstat
Обращать внимание на это не стоит, т. к
роботы Google используют только правила для GoogleBot.
Команда «Allow:» – разрешение индексации в robots.txt
Антиподом предыдущей директивы можно считать команду «Allow:». При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу. В подтверждение – очередной пример:
User-agent: Yandex Allow: /wp-admin
По какой-то причине веб-мастер передумал и внес соответствующие корректировки в robots.txt. Как следствие, отныне содержимое папки wp-admin официально разрешено к индексации Яндексом.
Несмотря на то, что команда «Allow:» существует, на практике она используется не так уж и часто. По большому счету в ней нет надобности, поскольку она применяется автоматически. Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации то или иное его содержимое. После этого весь остальной контент ресурса, который не запрещен в файле robots.txt, воспринимается поисковым роботом как такой, который индексировать можно и нужно. Все как в юриспруденции: «Все, что не запрещено законом, – разрешено».
Резюме
- robots.txt — файл с рекомендациями, как обрабатывать страницы сайта, для поисковых роботов.
- В WordPress по умолчанию нет robots.txt, но есть виртуальный файл, который запрещает ботам сканировать страницы панели управления.
- Создать robots.txt можно в блокноте и загрузить его на хостинг в корневой каталог.
- Файл robots.txt должен быть создан в кодировке UTF-8.
- Проще создать robots.txt с помощью плагинов для WordPress — Clearfy Pro, Yoast SEO, All in One SEO Pack или других SEO-плагинов.
- С помощью robots.txt можно создать директивы для разных поисковых роботов, сообщить о главном зеркале сайта, передать адрес sitemap.xml или указать параметры URL-адресов, которые не влияют на содержимое страницы.
- Проверить валидность robots.txt можно с помощью инструментов от и Яндекс.
- Все директивы файла robots.txt, которые робот не сможет интерпретировать, он проигнорирует.


Для чего нужен этот файл
А вот для чего:
- запрета на индексацию мусора — страниц и разделов, которые не содержат в себе полезный контент;
- разрешение индексации нужных страниц и разделов;
- чтобы давать разные задачи роботам разных поисковиков — то есть, например, Яндексу разрешить индексировать всё, а Рамблеру — ничего;
- можно также задавать роботам разные категории. Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
- чтобы показать через директиву Host Яндексу, какое у сайта главное зеркало;
- еще некоторые вебмастера запрещают всяким нехорошим парсерам сканировать сайт с помощью этого файла;
То есть большую часть проблем по индексации он решает. Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Robots.txt для Joomla
И хотя в 2018 Joomla редко кто использует, я считаю, что нельзя обделять вниманием эту замечательную CMS. При продвижении проектов на Joomla вам непременно придется создавать файл роботс, а иначе как вы хотите закрывать от индексации ненужные элементы?. Как и в предыдущем случае, вы можете создать файл вручную, просто закинув его на хост, либо же использовать модуль для этих целей
В обоих случаях вам придется его грамотно настраивать. Вот так будет выглядеть правильный вариант для Joomla:
Как и в предыдущем случае, вы можете создать файл вручную, просто закинув его на хост, либо же использовать модуль для этих целей. В обоих случаях вам придется его грамотно настраивать. Вот так будет выглядеть правильный вариант для Joomla:
User-agent: *
Allow: /*.css?*$
Allow: /*.js?*$
Allow: /*.jpg?*$
Allow: /*.png?*$
Disallow: /cache/
Disallow: /*.pdf
Disallow: /administrator/
Disallow: /installation/
Disallow: /cli/
Disallow: /libraries/
Disallow: /language/
Disallow: /components/
Disallow: /modules/
Disallow: /includes/
Disallow: /bin/
Disallow: /component/
Disallow: /tmp/
Disallow: /index.php
Disallow: /plugins/
Disallow: /*mailto/
Disallow: /logs/
Disallow: /component/tags*
Disallow: /*%
Disallow: /layouts/
User-agent: Yandex
Disallow: /cache/
Disallow: /*.pdf
Disallow: /administrator/
Disallow: /installation/
Disallow: /cli/
Disallow: /libraries/
Disallow: /language/
Disallow: /components/
Disallow: /modules/
Disallow: /includes/
Disallow: /bin/
Disallow: /component/
Disallow: /tmp/
Disallow: /index.php
Disallow: /plugins/
Disallow: /*mailto/
Disallow: /logs/
Disallow: /component/tags*
Disallow: /*%
Disallow: /layouts/
User-agent: GoogleBot
Disallow: /cache/
Disallow: /*.pdf
Disallow: /administrator/
Disallow: /installation/
Disallow: /cli/
Disallow: /libraries/
Disallow: /language/
Disallow: /components/
Disallow: /modules/
Disallow: /includes/
Disallow: /bin/
Disallow: /component/
Disallow: /tmp/
Disallow: /index.php
Disallow: /plugins/
Disallow: /*mailto/
Disallow: /logs/
Disallow: /component/tags*
Disallow: /*%
Disallow: /layouts/
Host: site.ru # не забудьте здесь поменять адрес на свой
Sitemap: site.ru/sitemap.xml # и здесь
Как правило, этого достаточно, чтобы лишние файлы не попадали в индекс.