Как заблокировать сайт на компьютере с windows или macos
Содержание:
- Что убирать из индекса?
- Страницы сайта
- Ошибки, на которые следует обратить внимание
- Что будет если закрыть индексацию
- Принцип работы файла robots
- Как закрыть страницу от индексации?
- Что такое файл Robots.txt?
- Сокрытие информации при помощи мета-тегов
- Как исправить зависание WordPress в режиме техобслуживания
- Как закрыть сайт от индексации в WordPress?
- Как скрыть контент с помощью Ajax
- Настройка файла robots.txt: основные директивы
- Плюсы и минусы использования закрытого контента
- Ошибки, связанные с файлом robots.txt
- Что такое robots.txt и для чего он нужен
- Проверка файла robots
- Причины использования
Что убирать из индекса?
Рассмотрев три основных способа настройки индексации, теперь поговорим о том, что конкретно нужно закрывать, чтобы оптимизировать краулинг сайта.
Документы PDF, DOC, XLS
На многих сайтах помимо основного контента присутствуют файлы с расширением PDF, DOC, XLS. Как правило, это всевозможные договора, инструкции, прайс-листы и другие документы, представляющие потенциальную ценность для пользователя, но в то же время способные размывать релевантность страницы из-за попадания в индекс большого объема второстепенного контента. В некоторых случаях такой документ может ранжироваться лучше основной страницы, занимая в поиске более высокие позиции. Именно поэтому все объекты с расширением PDF, DOC, XLS целесообразно убирать из индекса. Удобнее всего это делать в robots.txt.
Страницы с версиями для печати
Страницы с текстом, отформатированным под печать — еще один полезный пользовательский атрибут, который в то же время не всегда однозначно воспринимается поисковиками. Такие документы часто распознаются краулерами как дублированный контент, оказывая негативный эффект для продвижения. Он может выражаться во взаимном ослаблении позиций страниц и нежелательном перераспределении ссылочного веса с основного документа на второстепенный. Иногда поисковые алгоритмы считают такие дубли более релевантными, и вместо основной страницы в выдаче отображают версию для печати, поэтому их уместно закрывать от индексации.
Страницы пагинации
Нужно ли закрывать от роботов страницы пагинации? Данный вопрос становится камнем преткновения для многих оптимизаторов в первую очередь из-за диаметрально противоположных мнений на этот счет. Постраничный вывод контента на страницах листинга однозначно нужен, поскольку это важный элемент внутренней оптимизации. Но в необработанном состоянии страницы пагинации могут восприниматься как дублированный контент со всеми вытекающими последствиями для ранжирования.
Первый подход к решению этой проблемы — настройка метатега Robots. С помощью noindex, follow из индекса исключают все страницы пагинации кроме первой, но не запрещают краулерам переходить по ссылкам внутри них. Второй вариант обработки не предусматривает закрытия страниц. Вместо этого настраивают атрибуты rel=»canonical», rel=»prev» и rel=»next». Опыт показывает, что оба этих подхода имеют право на жизнь, хотя в своей практике мы чаще используем первый вариант.
Страницы служебного пользования
Технические страницы, предназначенные для административного использования, также целесообразно закрывать от индексации. Например, это может быть форма авторизации для входа в админку или другие служебные страницы. Удобнее всего это делать через директиву в robots.txt. Документы, к которым необходимо ограничить доступ, можно указывать списком, прописывая каждый с новой строки.
Страницы сайта
Для успешного продвижения важно не только избавиться от лишней информации на страницах, но и очистить поисковый индекс сайта от малополезных мусорных страниц.
Во-первых, это ускорит индексацию основных продвигаемых страниц сайта. Во-вторых, наличие в индексе большого числа мусорных страниц будет негативно влиять на оценку сайта и его продвижение
Сразу перечислим страницы, которые целесообразно прятать:
– страницы оформления заявок, корзины пользователей;
– результаты поиска по сайту;
– личная информация пользователей;
– страницы результатов сравнения товаров и подобных вспомогательных модулей;
– страницы, генерируемые фильтрами поиска и сортировкой;
– страницы административной части сайта;
– версии для печати.
Рассмотрим способы, которыми можно закрыть страницы от индексации.
Закрыть в robots.txt
Это не самый лучший метод.
Во-первых, файл robots не предназначен для борьбы с дублями и чистки сайтов от мусорных страниц. Для этих целей лучше использовать другие методы.
Во-вторых, запрет в файле robots не является гарантией того, что страница не попадёт в индекс.
Вот что Google пишет об этом в своей справке:

Работе с файлом robots.txt посвящена статья в блоге Siteclinic «Гайд по robots.txt: создаём, настраиваем, проверяем».
Метатег noindex
Чтобы гарантированно исключить страницы из индекса, лучше использовать этот метатег.
Рекомендации по синтаксису у Яндекса и Google отличаются.
Ниже приведём вариант метатега, который понимают оба поисковика:
<meta name="robots" content="noindex, nofollow">
Важный момент!
Чтобы Googlebot увидел метатег noindex, нужно открыть доступ к страницам, закрытым в файле robots.txt. Если этого не сделать, робот может просто не зайти на эти страницы.
Выдержка из рекомендаций Google:

Заголовки X-Robots-Tag
Существенное преимущество такого метода в том, что запрет можно размещать не только в коде страницы, но и через корневой файл .htaccess.
Этот метод не очень распространён в Рунете. Полагаем, основная причина такой ситуации в том, что Яндекс этот метод долгое время не поддерживал.
В этом году сотрудники Яндекса написали, что метод теперь поддерживается.

Ответ поддержки подробным не назовёшь))). Прежде чем переходить на запрет индексации, используя X-Robots-Tag, лучше убедиться в работе этого способа под Яндекс. Свои эксперименты на эту тему мы пока не ставили, но, возможно, сделаем в ближайшее время.
Подробные рекомендации по использованию заголовков X-Robots-Tag от Google.
Защита с помощью пароля
Этот способ Google рекомендует, как наиболее надёжный метод спрятать конфиденциальную информацию на сайте.

Если нужно скрыть весь сайт, например, тестовую версию, также рекомендуем использовать именно этот метод. Пожалуй, единственный недостаток – могут возникнуть сложности в случае необходимости просканировать домен, скрытый под паролем.
Исключить появление мусорных страниц c помощью AJAX
Речь о том, чтобы не просто запретить индексацию страниц, генерируемых фильтрами, сортировкой и т. д., а вообще не создавать подобные страницы на сайте.
Например, если пользователь выбрал в фильтре поиска набор параметров, под которые вы не создавали отдельную страницу, изменения в товарах, отображаемых на странице, происходит без изменения самого URL.
Сложность этого метода в том, что обычно его нельзя применить сразу для всех случаев. Часть формируемых страниц используется для продвижения.
Например, страницы фильтров. Для «холодильник + Samsung + белый» нам нужна страница, а для «холодильник + Samsung + белый + двухкамерный + no frost» – уже нет.
Поэтому нужно делать инструмент, предполагающий создание исключений. Это усложняет задачу программистов.
Использовать методы запрета индексации от поисковых алгоритмов
«Параметры URL» в Google Search Console
Этот инструмент позволяет указать, как идентифицировать появление в URL страниц новых параметров.
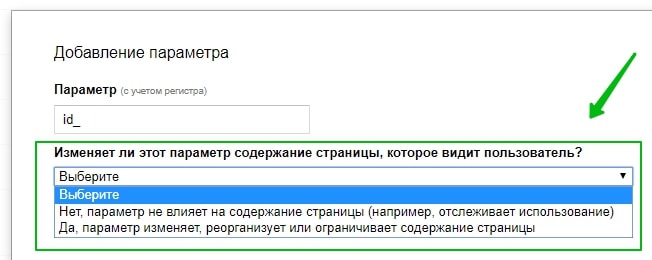
Директива Clean-param в robots.txt
В Яндексе аналогичный запрет для параметров URL можно прописать, используя директиву Clean-param.
Почитать об этом можно .
Канонические адреса, как профилактика появления мусорных страниц на сайте
Этот метатег был создан специально для борьбы с дублями и мусорными страницами на сайте. Мы рекомендуем прописывать его на всём сайте, как профилактику появления в индексе дубле и мусорных страниц.
Инструменты точечного удаления страниц из индекса Яндекса и Google
Если возникла ситуация, когда нужно срочно удалить информацию из индекса, не дожидаясь, пока ваш запрет увидят поисковые работы, можно использовать инструменты из панели Яндекс.Вебмастера и Google Search Console.
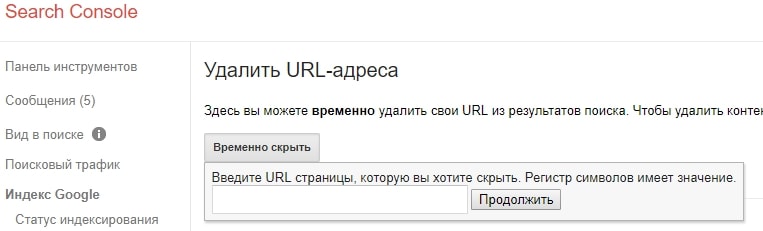
В Яндексе это «Удалить URL»:
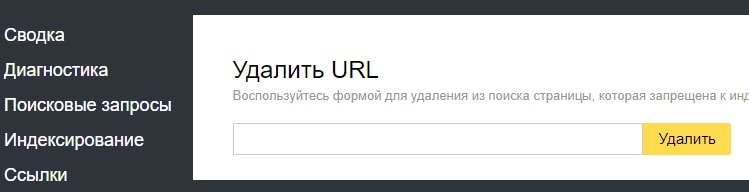
В Google Search Console «Удалить URL-адрес»:
Ошибки, на которые следует обратить внимание
Если после выполнения вышеописанных манипуляций у вас не получилось отключить индексацию, рекомендую обратить внимание на несколько моментов. В первую очередь проверьте логичность команд
Очень часто они противоречат друг другу, из-за чего не работают. Найти подобные ошибки можно посредством проверки robots.txt при помощи соответствующих инструментов в кабинете вебмастера.
Другой пласт распространённых ошибок – синтаксические. В данном случае подразумевается неправильная запись команд в файле. Рекомендую проверять файл сразу же после внесения нужных команд: так можно будет заранее найти ошибки и не тратить время на их поиск в будущем. На этом тему закрытия от индексации можно закончить. Вы можете подписаться на информационную рассылку для того, чтобы постоянно быть в курсе выхода новых полезных публикаций
Благодарю за внимание, всего хорошего!
Что будет если закрыть индексацию
Несмотря на обилие подробных инструкций по
производству выборочной индексации, многие пользователи и начинающие веб
дизайнеры производят скрытие контента неправильно. Это понятно, ведь гораздо
легче одним действием защитить от поисковых ботов весь сайт, чем по одиночке
защищать конкретный файл или внешнюю ссылку. Но, давайте посмотрим, к чему
может привести подобная ситуация:
- если поисковой системе закрыт доступ абсолютно ко всему контенту, то бот попросту туда не попадет. При повторяющихся эпизодах траст сайта постепенно сходит на убыль;
- снижается скорость загрузки страниц. Причина – та же самая, что и в примере, рассмотренном ранее;
- если при защите ссылок или контента, пользователь случайно закрыл ключи, впоследствии сайт может быть исключен из поиска. Причиной станет наложение фильтров поисковыми ботами;
- скрытие контента – это меньший поток информации, а соответственно, редкие посещения поисковых систем.
Защита от индексации может быть полезна для
верстальщиков html-страниц на начальных этапах работы, когда
вмешательство поискового бота может нарушить процесс создания сайта. Однако,
чрезмерное увлечение защитными механизмами может резко снизить эффективную
деятельность ресурса.
Принцип работы файла robots
Работа файла строится всего на 3-х элементах:
- Выбор поискового робота
- Запрет на индексацию разделов
- Разрешение индексации разделов
1. Как указать поискового робота
С помощью директивы User-agent прописывается имя робота, для которого будут действовать следующие за ней правила. Она используется вот в таком формате:
User-agent: * # для всех роботов
User-agent: имя робота # для конкретного робота
После символа «#» пишутся комментарии, в обработке они не участвуют.
Таким образом, для разных поисковых систем и роботов могут быть заданы разные правила.
Основные роботы, на которые стоит ориентироваться – это yandex и googlebot, они представляют соответствующие поисковики.
2. Как запретить индексацию в Robots.txt
Запрет индексации осуществляется в помощью директивы Disallow. После нее прописывается раздел или элемент сайта, который не должен попадать в поиск. Указывать можно как конкретные папки и документы, так и разделы с определенными признаками.
Если после этой директивы не указать ничего, то робот посчитает, что запретов нет.
Disallow: #запретов нет
Для запрета файлов указываем путь относительного домена.
Disallow: /zapretniy.php #запрет к индексации файла zapretniy.php
Запрет разделов осуществляется аналогичным образом.
Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta
Если нам нужно запретить разные разделы и страницы, содержащие одинаковые признаки, то используем символ «*». Звездочка означает, что на ее месте могут быть любые символы (любые разделы, любой степени вложенности).
Disallow: */*test #будут закрыты все страницы, в адресе которых содержится test
Обратите внимание, что на конце правила звездочка не ставится, считается, что она там есть всегда. Отменить ее можно с помощью знака «$»
Disallow: */*test$ #запрет к индексации всех страниц, оканчивающихся на test
Выражения можно комбинировать, например:
Disallow: /test/*.pdf$ #закрывает все pdf файлы в разделе /test/ и его подразделах.
3. Как разрешить индексацию в Robots.txt
По-умолчанию, все разделы сайта открыты для поисковых роботов. Директива, разрешающая индексацию нужна в тех случаях, когда вам необходимо открыть какой-либо кусочек из блока закрытого директивой disallow.
Для открытия служит директива Allow. К ней применяются те же самые атрибуты. Пример работы может выглядеть вот так:
User-agent: * # для всех роботов Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta Allow: *.pdf$ #разрешает индексировать pdf файлы, даже в разделе /razdel-sajta
Теорию мы изучили, переходим к практике.
Как закрыть страницу от индексации?
Если нужно скрыть только одну страницу, то в файле robots нужно будет прописать другой код:
User-agent: *
Disallow: /category/kak-nachat-zarabatyvat
Во второй строчке вам нужно указать адрес страницы, но без названия домена. Как вариант, вы можете закрыть страницу от индексации, если пропишите в её коде:
<META NAME=»ROBOTS» CONTENT=»NOINDEX»>
Это более сложный вариант, но если нет желания добавлять строчки в robots.txt, то это отличный выход. Если вы попали на эту страницу в поисках способа закрытия от индексации дублей, то проще всего добавить все ссылки в robots.
Как закрыть от индексации ссылку или текст?
Здесь тоже нет ничего сложного, нужно лишь добавить специальные теги в код ссылки или окружить её ими:
<noindex>
<a rel=»nofollow» href=»http://Workion.ru/»>Анкор</a>
</noindex>
Используя эти же теги noindex, вы можете скрывать от поисковых систем разный текст. Для этого нужно в редакторе статьи прописать этот тег.
К сожалению, у Google такого тега нет, поэтому скрыть от него часть текста не получится. Самый простой вариант сделать это – добавить изображение с текстом.
Скрывайте от поисковых роботов всё, что не уникально или каким-то образом может нарушать их правила. А если вы решили полностью переделать сайт, то обязательно закрывайте его от индексации, чтобы боты не индексировали внесенные изменения до того, как вы над ними поработаете и всё протестируете.
Вам также будет интересно: — Скорость сайта – важный фактор — Почему Яндекс не индексирует сайт? — Оригинальные тексты для защиты от Yandex
Что такое файл Robots.txt?
Robots.txt – это файл, который указывает поисковым роботам (например, Googlebot и Bingbot), какие страницы сайта не должны сканироваться.
Чем полезен файл Robots.txt?
Файл robots.txt сообщает роботам системам, какие страницы могут быть просканированы. Но не может контролировать их поведение и скорость сканирования сайта. Этот файл, по сути, представляет собой набор инструкций для поисковых роботов о том, к каким частям сайта доступ ограничен.
Но не все поисковые системы выполняют директивы файла robots.txt. Если у вас остались вопросы насчет robots.txt, ознакомьтесь с часто задаваемыми вопросами о роботах.
Как создать файл Robots.txt?
По умолчанию файл robots.txt выглядит следующим образом:
Можно создать свой собственный файл robots.txt в любом редакторе, который поддерживает формат .txt. С его помощью можно заблокировать второстепенные веб-страницы сайта. Файл robots.txt – это способ сэкономить лимиты, которые могут пойти на сканирование других разделов сайта.
Директивы для сканирования поисковыми системами
User-Agent: определяет поискового робота, для которого будут применяться ограничения в сканировании URL-адресов. Например, Googlebot, Bingbot, Ask, Yahoo.
Disallow: определяет адреса страниц, которые запрещены для сканирования.
Allow: только Googlebot придерживается этой директивы. Она разрешает анализировать страницу, несмотря на то, что сканирование родительской веб-страницы запрещено.
Sitemap: указывает путь к файлу sitemap сайта.
Правильное использование универсальных символов
В файле robots.txt символ (*) используется для обозначения любой последовательности символов.
Директива для всех типов поисковых роботов:
User-agent:*
Также символ * можно использовать, чтобы запретить все URL-адреса кроме родительской страницы.
User-agent:*
Disallow: /authors/*
Disallow: /categories/*
Это означает, что все URL-адреса дочерних страниц авторов и страниц категорий заблокированы за исключением главных страниц этих разделов.
Ниже приведен пример правильного файла robots.txt:
User-agent:* Disallow: /testing-page/ Disallow: /account/ Disallow: /checkout/ Disallow: /cart/ Disallow: /products/page/* Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Sitemap: yourdomainhere.com/sitemap.xml
После того, как отредактируете файл robots.txt, разместите его в корневой директории сайта. Благодаря этому поисковый робот увидит файл robots.txt сразу после захода на сайт.
Сокрытие информации при помощи мета-тегов
В качестве замены вышеописанного robots.txt можно воспользоваться похожим мета-тегом под названием «robots». Его необходимо вставить в изначальный код страницы, содержащийся в файле «index.html». Помещать его необходимо в контейнер. Также потребуется ввести краулеров, для которых индексация сайта будет недоступна. Если ресурс будет скрыт полностью, необходимо вставить «robots», если для конкретного поисковика – наименование его бота (Googlebot для Гугла и Yandex, соответственно, – для Яндекса). Мета-тег можно указать сразу в двух вариантах (они показаны на картинке снизу).
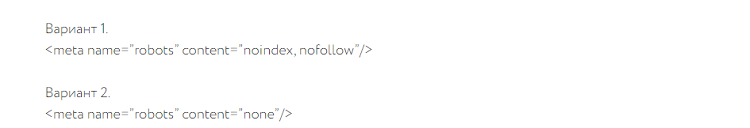
В обоих вариантах следует уделить особое внимание переменной «content», так как она обладает сразу несколькими значениями:
- «none» – полный запрет индексации;
- «noindex» – запрет только на индексацию контента;
- «nofollow» – запрет на индексацию различных адресов и ссылок;
- «follow» – разрешение на индексацию различных адресов и ссылок;
- «all» – разрешение на полную индексацию;
- «index» – разрешение только на индексацию контента.
То есть, вы можете наложить запрет на индексацию контента, но всё же оставить различные ссылки. В таком случае потребуется просто вести следующую строку: content= «noindex, follow». В итоге будет происходить индексация ссылок, в то время как текст обрабатываться не будет.
Как исправить зависание WordPress в режиме техобслуживания
Если у вас не установлен плагин для техобслуживания, то первое, на что стоит обратить внимание, – это файл .maintenance. Его нужно просто удалить, и все проблемы с зависанием уйдут напрочь
Для этого выполните следующее:
- Подключитесь к сайту с помощью FTP-клиента либо по SSH.
- Найдите в корневой папке файл .maintenance и удалите его.
- Перезагрузите страницу сайта. Все должно заработать!
Вполне возможно, что сайт зависает вследствие реальной ошибки. Скорее всего, она вызвана плагином – в этом случае потребуется его удалить либо отключить. Если же отключение плагина не помогает, то попробуйте восстановить сайт из резервной копии.
Как закрыть сайт от индексации в WordPress?
Данный способ, наверное, самый простой, и владельцам сайтов, которые созданы на базе CMS WordPress, очень повезло. Дело в том, что в данной CMS предусмотрена возможность закрытия сайта от индексации при установке движка на хостинг. В случае если вы не сделали этого при установке, вы всегда можете это сделать в настройках. Для этого вам нужно:
- 1.В админпанели переходим в раздел «Настройки» → «Чтение».
-
2.Перелистываем открывшуюся страницу в самый низ, и отмечаем галочкой опцию показанную на скриншоте:
- 3.Сохраняем изменения.
Все. Теперь ваш сайт не будет индексироваться. Если открыть страницу в браузере и нажать комбинацию клавиш CTRL+U, мы сможем просмотреть код страницы, и увидим вот такую строку кода:

Данная запись была добавлена автоматически, после того как мы включили опцию запрета индексации в настройках.
Главное не забыть отключить эту опцию после завершения работ:)
Как скрыть контент с помощью Ajax
Иногда приходится скрывать от поисковых ботов
не только внешние ссылки, но и некоторую информацию на странице. Рассмотрим,
какие виды контента можно скрыть от поисковых ботов:
- ссылки на сайты партнеров;
- рекламный контент;
- часто повторяющийся текст.
Данная информация может послужить причиной
временной блокировки сайта пользователя.
В чем заключается сущность работы сервиса Ajax? Главная особенность заключается в том, что контент не просто скрывается от ботов, но переводится на ресурс AJAX в виде внешнего файла, а в нужный момент подключается к сайту по запросу пользователя. Кроме того, помните, что не следует обрабатывать при помощи Ajax:
- скрипты с внешних ресурсов;
- приложения счетчики.
Опасность заключается в том, что эти
программы могут перестать работать.
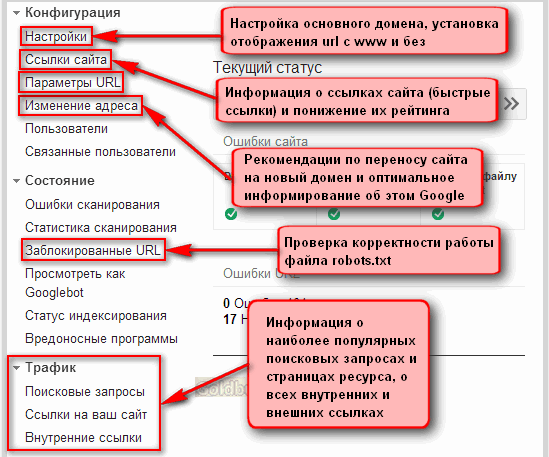
Настройка файла robots.txt: основные директивы
Чтобы правильно настроить файл robots.txt, необходимо знать директивы – команды, которые воспринимают роботы поисковых систем. Ниже рассмотрим основные директивы для настройки индексации сайта в файле robots.txt:
| Директива | Назначение |
| User-agent: | Указывает робота поисковой системы, для которого предназначены команды ниже. Названия роботов можно посмотреть в справочной информации, которую предоставляют поисковые системы. |
Директива User-agent: * обозначает, что команды ниже предназначены для всех роботов, для которых нет персональных команд в файле.
Важно соблюдать последовательность команд в файле. В начале прописываются команды для конкретных роботов (Yandex, Googlebot и т.д.), потом – для всех остальных.. Существуют другие директивы, которые используется реже
Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь
Disallow:
Данная директива в файле robots.txt закрывает индексацию определенной страницы или раздела на сайте. Сама страница или раздел указываются от корневой папки сайта, без домена (см. скриншот в начале статьи).
Allow:
Разрешает индексацию определенной страницы или раздела на сайте. Директивы Allow необходимо располагать ниже директив Disallow.
Host:
Указывает главное зеркало сайта (либо с www, либо без www). Учитывается только Яндексом.
Sitemap:
В данной директиве необходимо прописать путь к карте сайта, если она имеется на сайте.
Существуют другие директивы, которые используется реже. Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь.
Частные случаи команд в файле robots.txt
Разберем некоторые команды, которые потребуются Вам в работе:
| Команда | Что обозначает |
| User-agent: Yandex | Начало блока команд для основного робота поисковой системы Яндекс. |
| User-agent: Googlebot | Начало блока команд для основного робота поисковой системы Google. |
| User-agent: *Disallow: / | Данная команда в файле robots.txt полностью закрывает сайт от индексации всеми поисковыми системами. |
| User-agent: *Disallow: /Allow: /test.html | Данные команды закрывают все документы на сайте от индексации, кроме страницы /test.html |
| Disallow: /*.doc | Данная команда запрещает индексировать файлы MS Word на сайте. Если на сайте содержится конфиденциальная информация в файлах определенного типа, имеет смысл закрыть такие файлы от индексации. |
| Disallow: /*.pdf | Данная команда в robots.txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах. |
| Disallow: /basket/ | Команда запрещает индексировать все документы в разделе /basket/. |
| Host: www.yandex.ru | Команда задает для сайта yandex.ru основным зеркалом адрес сайта с www. Соответственно, в поиске с высокой вероятностью будут выводиться адреса страниц с www. |
| Host: yandex.ru | Данная команда задает для сайта yandex.ru в качестве основного зеркала адрес yandex.ru (без www). |
Плюсы и минусы использования закрытого контента
С правильным типом закрытого контента вы можете увеличить число подписчиков и привлечь больше трафика на ваш блог. Контент на основе закрытых данных может повысить воспринимаемую ценность вашего сайта, например, когда сообщение в блоге предлагает посетителям войти в систему, чтобы продолжить чтение. Если фрагмент вашего поста, к которому читатель может получить доступ, заинтригован, им будет предложено сделать то, что вы просите.
Кроме того, закрытый контент можно использовать для сбора ценных данных, которые вы можете использовать для понимания своей аудитории и повышения эффективности маркетинговых усилий. Каждый адрес электронной почты, который вы собираете, является другим человеком, которому вы можете отправить дружеские напоминания о новом контенте или продуктах. Некоторые могут даже отвечать на ваши электронные письма, предоставляя дополнительные возможности для построения отношений с вашей аудиторией.
С другой стороны, закрытый контент может раздражать или расстраивать ваших посетителей. Некоторым людям может не нравиться, когда их просят предоставить личную информацию, и это может оставить у них негативное восприятие вашего бренда. Стоит также отметить, что люди с меньшей вероятностью будут ссылаться на статьи, которые закрыты, что может замедлить ваш прогресс обратных ссылок .
К счастью, есть возможность использовать преимущество закрытого типа контента при сведении к минимуму отрицательных сторон. В общем смысле это включает в себя стробирование контента, который имеет реальную ценность и может быть легко распространен. В оставшейся части этого поста мы расскажем, как вы можете это сделать.
Ошибки, связанные с файлом robots.txt
Одна из самых распространенных ошибок – перевернутый синтаксис.
Неправильно:
User-agent: /
Disallow: Yandex
Правильно:
User-agent: Yandex
Disallow: /
Неправильно:
User-agent: *
Disallow: /dir/ /cgi-bin/ /forum/
Правильно:
User-agent: *
Disallow: /dir/
Disallow: /cgi-bin/
Disallow: /forum/
Если при обработке ошибки 404 (документ не найден), веб-сервер выдает специальную страницу, и при этом файл robots.txt отсутствует, то возможна ситуация, когда поисковому роботу при запросе файла robots.txt выдается та самая специальная страница, никак не являющаяся файлом управления индексирования.
Ошибка, связанная с неправильным использованием регистра в файле robots.txt. Например, если необходимо закрыть директорию «cgi-bin», то в записе «Disallow» нельзя писать название директории в верхнем регистре «cgi-bin».
Неправильно:
User-agent: *
Disallow: /CGI-BIN/
Правильно:
User-agent: *
Disallow: /cgi-bin/
Ошибка, связанная с отсутствием открывающей наклонной черты при закрытии директории от индексирования.
Неправильно:
User-agent: *
Disallow: dir
User-agent: *
Disallow: page.HTML
Правильно:
User-agent: *
Disallow: /dir
User-agent: *
Disallow: /page.HTML
Чтобы избежать наиболее распространенных ошибок, файл robots.txt можно проверить средствами Яндекс.Вебмастера или Инструментами для вебмастеров Google. Проверка осуществляется после загрузки файла.
Что такое robots.txt и для чего он нужен
Robots.txt — это обычный текстовый файл с расширением .txt, который содержит директивы и инструкции индексирования сайта, его отдельных страниц или разделов для роботов поисковых систем.
Давайте рассмотрим самый простой пример содержимого robots.txt, которое разрешает поисковым системам индексировать все разделы сайта:
User-agent: * Allow: /
Данная инструкция дословно говорит: всем роботам, читающим данную инструкцию (User-agent: *) разрешаю индексировать весь сайт (Allow: /).
 Зачем все эти сложности с инструкциями для роботов, и почему нельзя открывать сайт для индексации полностью?
Зачем все эти сложности с инструкциями для роботов, и почему нельзя открывать сайт для индексации полностью?
Представьте, что вы поисковый робот, которому нужно просмотреть миллиарды страниц по всем интернету, потом определить для каждой страницы запросы, которым они могут соответствовать и в конце проранжировать эту массу в поисковой выдаче. Согласитесь, задача не из легких. Для работы поисковых алгоритмов используются колоссальные ресурсы, которые, разумеется, ограничены.
Если помимо страниц, которые содержат полезный контент, и которые по задумке владельца сайта должны участвовать в выдаче, роботу придется просматривать еще кучу технических страниц, которые не представляют никакой ценности для пользователей, его ресурсы будут тратиться впустую. Вы только представьте, что только один единственный сайт может генерировать тысячи страниц результатов поиска по сайту, дублирующихся страниц или страниц, не содержащих контента вообще. А если этот объем масштабировать на всю сеть, то получатся гигантские цифры и соответствующие ресурсы, которые необходимо тратить поисковикам.
Наличие огромного количества бесполезного контента на вашем сайте может негативно сказаться на его представлении в поиске. Как бы вы отнеслись к человеку, который дал вам мешок орехов, но внутри оказалась только скорлупа и всего 2-3 орешка? Не трудно представить и позицию поисковиков при аналогии данной ситуации с вашим сайтом.
Кроме того, существует такое понятие, как краулинговый бюджет. Условно, это объем страниц, который может участвовать в поисковой выдаче от одного сайта. Этот объем, естественно, ограничен, но по мере роста проекта и повышения его качества, краулинговый бюджет может увеличиваться, но сейчас не об этом. Главное идея в том, в выдаче должны участвовать только страницы, которые содержат полезный контент, а весь технический «мусор» не должен засорять выдачу поисковым спамом.
Проверка файла robots
Есть потрясающий инструмент, который позволит вам включиться в творческую работу с директивами и прописать правильный robots.txt –инструмент от Яндекс.Вебмастера.
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем «Проверить» и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
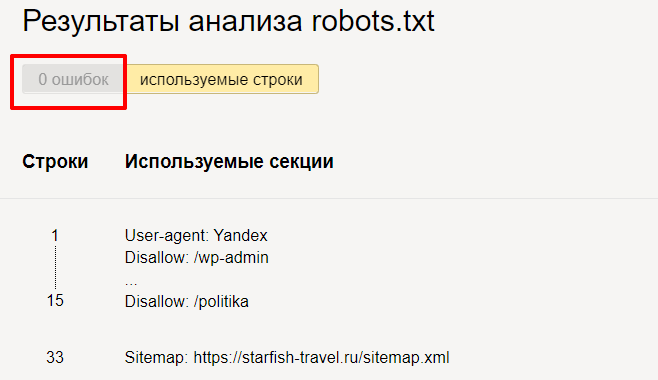
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.

Вводим список адресов, которые нас интересуют, и нажимаем «Проверить». Инструмент сообщит нам, разрешены ли для индексации данные адреса страниц, а в столбце «Результат» будет видно, почему страница индексируется или не индексируется.
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Причины использования
Такая заглушка используется на время технических работ, чтобы оповестить приходящих посетителей, что над сайтом ведутся работы и он скоро откроется.
С другой стороны сайт может некорректно работать во время тяжелых обновлений, внедрения новых функций и изменения дизайна, что может повлечь за собой потерю репутации.
Еще один вариант использования заглушки сайта — потребность разрекламировать проект прежде чем тот будет запущен.
В этом случае на заглушке размещают:
-
информацию о проекте;
-
ознакомительный контент (фотографии ассортимента, видео и т.п.);
-
таймер обратного отсчёта до полноценного открытия;
-
форму обратной связи;
-
ссылки на соцсети;
-
промокод на первую покупку.