Поиск файлов в linux
Содержание:
- Выполнение и объединение команд
- Options and Optimizations for Finding Files in Linux Using the Command Line
- Search Location Shortcuts
- Use the ‘find’ Command to Locate a File in Linux
- Поиск по типу файла
- Рекурсивный поиск
- Работа с найденными файлами
- ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
- Поиск файлов по дате изменения
- Использование регулярных выражений
- Поиск больших файлов и директорий командой du
- Поиск файлов по типу
- Основные опции команды Linux find
- Options and Optimization for Find Command for Linux
- Поиск файла в Linux по фамилии командой whereis
- Примеры использования locate
- Поиск по размеру файла
- find — синтаксис и зачем оно нужно
- Найти и удалить файлы
- Сравнение файлов diff
- Expressions
- Команда sed в Linux
- Найти файлы по типу
Выполнение и объединение команд
Утилита find позволяет выполнять любую вспомогательную команду на все найденные файлы; для этого используется параметр –exec. Базовый синтаксис выглядит так:
find параметры_поиска -exec команда_и_параметры {} \;
Символы {} используются в качестве заполнителя для найденных файлов. Символы \; используются для того, чтобы find могла определить, где заканчивается команда.
Для примера можно найти файлы с привилегиями 644 (как в предыдущем разделе) и изменить их привилегии на 664:
cd ~/test
find . -perm 644 -exec chmod 664 {} \;
Затем можно сменить привилегии каталога:
find . -perm 755 -exec chmod 700 {} \;
Чтобы связать несколько результатов, используйте команды -and или -or. Команда –and предполагается, если она опущена.
find . -name file1 -or -name file9
Options and Optimizations for Finding Files in Linux Using the Command Line
The default configuration for ignores
. If you want to follow and return symbolic links, add the option to the command, as shown below:
This command enables the maximum optimization level () and allows to follow symbolic links (). searches the entire directory tree beneath for files that end with .
optimizes its filtering strategy to increase performance. Three user-selectable optimization levels are specified as , , and . The optimization is the default and forces to filter based on filename before running all other tests.
Optimization at the level prioritizes filename filters, as in , and then runs all file-type filtering before proceeding with other more resource-intensive conditions. Level optimization allows to perform the most severe optimization and reorders all tests based on their relative expense and the likelihood of their success.
| Command | Description |
|---|---|
| Filter based on filename first (default). | |
| File name first, then file-type. | |
| Allow to automatically re-order the search based on efficient use of resources and likelihood. of success | |
| Search current directory as well as all sub-directories X levels deep. | |
| Search without regard for text case. | |
| Return only results that do not match the test case. | |
| Search for files. | |
| Search for directories. |
Search Location Shortcuts
The first argument after the find command is the location you wish to search. Although you may specify a specific directory, you can use a metacharacter to serve as a substitute. The three metacharacters that work with this command include:
- Period (.): Specifies the current and all nested folders.
- Forward Slash (/): Specifies the entire filesystem.
- Tilde (~): Specifies the active user’s home directory.
Searching the entire filesystem may generate access-denied errors. Run the command with elevated privileges (by using the sudo command) if you need to search in places your standard account normally cannot access.
Use the ‘find’ Command to Locate a File in Linux
The command used to search for files is called find.
The basic syntax of the find command is as follows:
The currently active path marks the search location, by default. To search the entire drive, type the following:
If, however, you want to search the folder you are currently in, use the following syntax:
When you search by name across the entire drive, use the following syntax:
- The first part of the find command is the find command.
- The second part is where to start searching from.
- The next part is an expression that determines what to find.
- The last part is the name of the file to find.
To access the shell (sometimes called the terminal window) in most distributions, click the relevant icon or press Ctrl+Alt+T.
Поиск по типу файла
При помощи параметра «-type» можно указать тип необходимого файла. Это работает так:
find -type type_descriptor query
Вот список общих дескрипторов, при помощи которых можно указать тип файла:
-
f
: обычный файл; -
d
: каталог; -
l
: символическая ссылка; -
c
: символьные устройства; -
b
: блочные устройства.
К примеру, чтобы найти в системе все символьные устройства, нужно выполнить команду:
find / -type c
/dev/parport0
/dev/snd/seq
/dev/snd/timer
/dev/autofs
/dev/cpu/microcode
/dev/vcsa7
/dev/vcs7
/dev/vcsa6
/dev/vcs6
/dev/vcsa5
/dev/vcs5
/dev/vcsa4
. . .
Чтобы найти все файлы, которые заканчиваются на.conf, используйте:
find / -type f -name «*.conf»
/var/lib/ucf/cache/:etc:rsyslog.d:50-default.conf
/usr/share/base-files/nsswitch.conf
/usr/share/initramfs-tools/event-driven/upstart-jobs/mountall.conf
/usr/share/rsyslog/50-default.conf
/usr/share/adduser/adduser.conf
/usr/share/davfs2/davfs2.conf
/usr/share/debconf/debconf.conf
/usr/share/doc/apt-utils/examples/apt-ftparchive.conf
. . .
Рекурсивный поиск
Для рекурсивного поиска шаблона, используйте опцию (или ). Когда эта опция используется, будет выполняться поиск по всем файлам в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы перейти по всем символическим ссылкам , вместо этого используйте опцию (или ).
Вот пример, показывающий, как искать строку во всех файлах в каталоге:
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете опцию, перейдите по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда вызывается из-за того, что файлы в каталоге Nginx являются символическими ссылками на файлы конфигурации внутри каталога.
Работа с найденными файлами
Для того чтобы выполнять действия над найденными документами применяется find exec Linux. Чтобы получить подробную информацию по каждому результату, выполняют «$find . -exec ls -ld {} \;». Для удаления все текстовых типов во временную папку прописывают «$find /tmp -type f -name «*.txt» -exec rm -f {} \;». А для того чтобы, к примеру, удалить все данные, больше 50 мегабайт в объеме, выполняют «$ find /home/bob/dir -type f -name *.log -size +5M -exec rm -f {} \;».
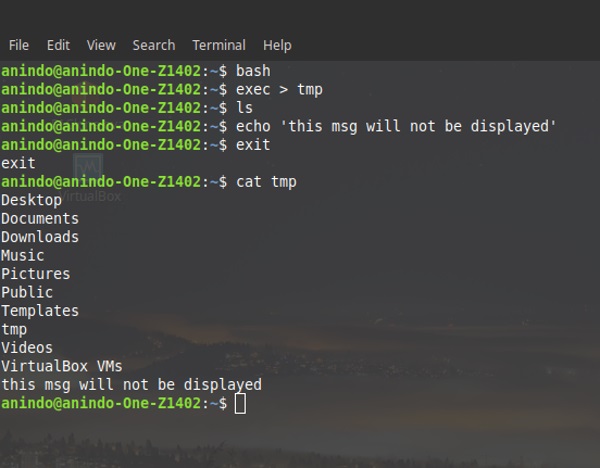
Применение опции exec
Теперь стало ясно, как найти файл или директорию в Линукс. Все крайне просто, ведь процедура основана на использовании команды find, которая выводит все содержимое результатов по определенным критериям. В сторонних справочниках к различным дистрибутивам можно почитать более подробное описание опций find, помогающей найти любую папку в Linux.
ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
С теорией покончено, теперь перейдем к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
ПОИСК ТЕКСТА В ФАЙЛАХ
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
ВЫВЕСТИ НЕСКОЛЬКО СТРОК
Например, мы хотим выбрать все ошибки из лог файла, но знаем что в следующей сточке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк, ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после нее.
Выведет целевую строку и 4 строчки до нее
Выведет по две строки с верху и снизу от вхождения.
РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ В GREP
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах grep. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки, спецсимвол «$»:
Найдем все строки которые содержат цифры:
Вообще, регулярные выражения grep это очень обширная тема, в этой статье я лишь показал несколько примеров, чтобы дать вам понять что это. Как вы увидели, таким образом, поиск текста в файлах grep становиться еще гибче. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим их и пойдем дальше.
РЕКУРСИВНОЕ ИСПОЛЬЗОВАНИЕ GREP
Если вам нужно провести поиск текста grep в нескольких файлах, размещенных в одном каталоге или подкаталогах, например, в файлах конфигурации Apache — /etc/apache2/ — используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займется поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
ПОИСК СЛОВ В GREP
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить grep искать по содержимому файлов в linux только те строки, которые выключают искомые слова с помощью опции -w:
ПОИСК ДВУХ СЛОВ
Можно искать по содержимому файла не одно слово, а целых несколько. Чтобы искать два разных слова используйте команду egrep:
КОЛИЧЕСТВО ВХОЖДЕНИЙ СТРОКИ
Утилита Grep может сообщить сколько раз определенная строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки в которой найдено вхождение, например:
Получим:
ИНВЕРТИРОВАННЫЙ ПОИСК В GREP
Команда grep linux может быть использована для поиска строк в файле Linux которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
ВЫВОД ИМЕНИ ФАЙЛА
Вы можете указать grep выводить только имя файла в котом было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Поиск файлов по дате изменения
также может искать файлы на основе их последнего изменения, доступа или изменения времени.
То же, что и при поиске по размеру, используйте символы «плюс» и «минус» для «больше чем» или «меньше чем».
Допустим, несколько дней назад вы изменили один из файлов конфигурации dovecot, но забыли, какой именно. Вы можете легко отфильтровать все файлы в каталоге, который заканчивается и был изменен за последние пять дней с помощью:
Вот еще один пример фильтрации файлов по дате изменения с использованием этой опции. Команда ниже выведет список всех файлов в каталоге, которые были изменены или несколько дней назад:
Использование регулярных выражений
Иногда вам может потребоваться использование регулярных выражений, чтобы определить критерии поиска. И find поддерживает их даже в большей степени, чем вы, возможно, ожидали. find не только поддерживает использование регулярных выражений, но и позволяет использовать различные их типы. Тип регулярного выражения можно определить при помощи опции -regextype, которая принимает параметры posix-awk, posix-egrep и тому подобные. В man-странице вы найдёте полный перечень поддерживаемых типов регулярных выражений вашей версией find.
Небольшой пример. Скажем, вам нужно найти файлы, имеющие расширения «.php» и «.js». Такое можно осуществить следующей командой:
find -regextype posix-egrep -regex '.*(php|js)$'
Выглядит страшновато, не так ли? Эта команда говорит find использовать синтаксис регулярных выражений egrep (-regextype posix-egrep), а затем сообщает само регулярное выражение. Выражение обрамлено одинарными кавычками, чтобы оболочка не пыталась по-своему интерпретировать спецсимволы, использующиеся в выражении. В самом выражении «.*» означает любой символ, повторяющийся ноль или более раз. Часть выражения «(php|js)» сообщает о необходимости искать «php» или «js» (символ вертикальной черты используется для определения оператора «или»). И, наконец, знак доллара в конце выражения сообщает о том, что предыдущая часть выражения должна искаться в конце строки.
Регулярные выражения можно комбинировать.
Поиск больших файлов и директорий командой du
Команда du используется для вывода размеров файлов и директорий в Linux. Ее можно использовать для поиска больших файлов и директорий. Для этого выполняется команда du и результат сортируется по размеру. Таким образом можно увидеть, кто занимает больше всего места на диске.
Найдем пять самых больших файлов и директорий:
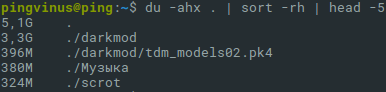
- Символ . указывает путь и означает текущую директорию. Для поиска в другой директории укажите вместо точки ее путь.
- Опции -ahx означают:a — искать и файлы и директории;h — выводить информацию в удобно-читаемом формате;x — не выполнять поиск на других файловых системах.
- sort -rh выполняет сортировку результата.
- head −5 выводит только пять первых результатов.
Поиск файлов по типу
Иногда вам может потребоваться поиск файлов определенного типа, таких как обычные файлы, каталоги или символические ссылки. В Linux все это файл.
Для поиска файлов по их типу используйте опцию и один из следующих дескрипторов, чтобы указать тип файла:
- : обычный файл
- : каталог
- : символическая ссылка
- : символьные устройства
- : блочные устройства
- : FIFO
- : разъем
Например, чтобы найти все каталоги в текущем рабочем каталоге , вы должны использовать:
Распространенным примером может быть рекурсивное изменение разрешений на доступ к файлам на веб-сайте и на использование каталогов с помощью команды
Основные опции команды Linux find
Очень часто в процессе работы появляется необходимость найти тот или иной файл (папку). Часто даже название файла забываются, поэтому приходиться выполнять поиск по другим критериям: правам доступа, размеру, типа файла и его расширению. Специально для этих целей и придумана команда find. Она позволяет выполнять поиск файла или папки в Linux по имени, а также создавать различные запросы для файловой системы и жесткого диска для нахождения нужных данных. Преимуществом использования данной команды становится возможность не только выполнять поиск по всем каталогам, созданным в операционной системе, но в отдельных указанных папках.
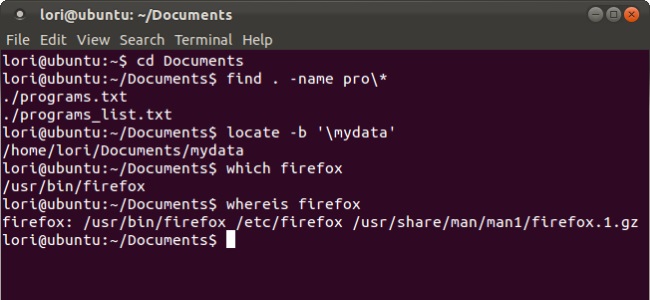
Пример использования
Важно! Возможности команды достаточно обширны, как и список предлагаемых к использованию опций. В этом материале будут описаны лишь наиболее важные и популярные из них, так как для рассмотрения всех атрибутов и параметров, доступных к применению, потребует много времени
Помимо поиска на внутренних носителях, find может спокойно искать данные по заданным параметрам на дисках типа NFS, но только в том случае, если пользователь обладает соответствующими разрешениями. В таких случаях обычно все выполняется на фоне, так как раскрытие дерева каталога занимает существенное количество времени.
Options and Optimization for Find Command for Linux
find is configured to ignore symbolic links (shortcut files) by default. If you’d like the find command to follow and show symbolic links, just add the -L option to the command, as we did in this example.
find can help Linux find file by name. The Linux find command enhances its approach to filtering so that performance is optimised. The user can find a file in Linux by selecting three stages of optimisation-O1, -O2, and -O3. -O1 is the standard setting and it causes find to filter according to filename before it runs any other tests.
-O2 filters by name and type of file before carrying on with more demanding filters to find a file in Linux. Level -O3 reorders all tests according to their relative expense and how likely they are to succeed.
Поиск файла в Linux по фамилии командой whereis
Whereis возвращает место расположения кода (опция -b), ман-страниц (функция -m), и исходные файлы (опция -s) для указанной команды. Если опции не указываются, выводится вся вразумительная информация. Эта команда быстрее чем “find” но менее полная. Команда whereis имеет последующий формат:
покажет положение бинарного файла, исходников и man-страницы бригады find:
Вот и подошла к концу эта маленькая статья, в которой была рассмотрена команда find. Как видите, это одна из наиболее значительных команд терминала Linux, позволяющая очень легко получить список нужных файлов. Ее желанно знать всем системным администраторам.
Примеры использования locate
Если нужно найти файлы, соответствующие сразу нескольким шаблонам, используется опция -A. Шаблоны разделяются пробелом:
Опция -w включена по умолчанию, поэтому locate проверяет на соответствие шаблону не только имена файлов, но и названия папок, в которых эти файлы расположены. Например, если Документ1.ods находится по адресу Компьютер/БухалтерияДоки/ВсеДокументы/, он будет выведен командой при использовании шаблонов «Док», «Бух» и «Все». Для того, чтобы в результатах отображались только файлы с именами, в которых присутствует шаблон, применяется опция -b.
Для сравнения:

На скриншоте видно, как команда обрабатывает запросы с каждой из упомянутых опций.
Команда locate чувствительна к регистру. Если, к примеру, шаблон имеет вид «GrEEn», файлы с именами green и GREEN в процессе поиска будут игнорироваться. Для того, чтобы найти все документы, независимо от наличия строчных и заглавных букв в их названиях, используется опция -i.
Порой в названиях файлов встречаются буквы с диакритическими знаками (умлаутами, акутами, тремами и прочими). Эти документы не будут найдены, если в команде используется шаблон, состоящий из обычных букв. И наоборот, если в шаблоне есть буквы с диакритическими знаками, команда проигнорирует файлы, в названиях которых отсутствуют аналогичные символы. «Стереть» разницу между буквами с диакритическими знаками и без них можно при помощи опции -t.

По умолчанию команда locate осуществляет поиск в собственной базе данных mlocate.db, однако, умеет работать и с пользовательскими БД. Для этого предусмотрена следующая опция: —database.
Можно одновременно осуществлять поиск в нескольких базах данных, при этом названия файлов этих баз нужно разделять двоеточием:
Результаты будут выведены отдельно для каждой базы данных, в той же очерёдности, с которой базы данных были перечислены в запросе.

Файлы, добавленные в систему до обновления стандартной базы данных, не обнаруживаются командой locate. Также в результатах могут появляться уже несуществующие (удалённые) документы. Для того, чтобы актуализировать выдачу, используется опция -e.
Глядя на скриншот, легко сравнить результаты поиска с опцией -е и без неё.

Кроме того, можно обновить базу данных вручную, выполнив в терминале команду:

Поиск по размеру файла
df -h /boot
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 1014M 194M 821M 20% /boot
Найти обычные файлы определённого размера
Чтобы найти обычные файлы нужно использовать
-type f
find /boot -size +20000k -type f
find: ‘/boot/efi/EFI/centos’: Permission denied
find: ‘/boot/grub2’: Permission denied
/boot/initramfs-0-rescue-389ee10be1b38d4281b9720fabd80a37.img
/boot/initramfs-3.10.0-1160.el7.x86_64.img
/boot/initramfs-3.10.0-1160.2.2.el7.x86_64.img
Файлы бывают следующих типов:
— : regular file
d : directory
c : character device file
b : block device file
s : local socket file
p : named pipe
l : symbolic link
Подробности в статье —
«Файлы в Linux»
find /boot -size +10000k -type f
find: ‘/boot/efi/EFI/centos’: Permission denied
find: ‘/boot/grub2’: Permission denied
/boot/initramfs-0-rescue-389ee10be1b38d4281b9720fabd80a37.img
/boot/initramfs-3.10.0-1160.el7.x86_64.img
/boot/initramfs-3.10.0-1160.el7.x86_64kdump.img
/boot/initramfs-3.10.0-1160.2.2.el7.x86_64.img
/boot/initramfs-3.10.0-1160.2.2.el7.x86_64kdump.img
То же самое плюс показать размер файлов
find /boot -size +10000k -type f -exec du -h {} \;
find: ‘/boot/efi/EFI/centos’: Permission denied
find: ‘/boot/grub2’: Permission denied
60M /boot/initramfs-0-rescue-389ee10be1b38d4281b9720fabd80a37.img
21M /boot/initramfs-3.10.0-1160.el7.x86_64.img
13M /boot/initramfs-3.10.0-1160.el7.x86_64kdump.img
21M /boot/initramfs-3.10.0-1160.2.2.el7.x86_64.img
14M /boot/initramfs-3.10.0-1160.2.2.el7.x86_64kdump.img
find — синтаксис и зачем оно нужно
find — утилита поиска файлов по имени и другим свойствам, используемая в UNIX‐подобных операционных системах. С лохматых тысячелетий есть и поддерживаться почти всеми из них.
Базовый синтаксис ключей (забран с Вики):
-name — искать по имени файла, при использовании подстановочных образцов параметр заключается в кавычки
Опция `-name’ различает прописные и строчные буквы; чтобы использовать поиск без этих различий, воспользуйтесь опцией `-iname’;
-type — тип искомого: f=файл, d=каталог, l=ссылка (link), p=канал (pipe), s=сокет;
-user — владелец: имя пользователя или UID;
-group — владелец: группа пользователя или GID;
-perm — указываются права доступа;
-size — размер: указывается в 512-байтных блоках или байтах (признак байтов — символ «c» за числом);
-atime — время последнего обращения к файлу (в днях);
-amin — время последнего обращения к файлу (в минутах);
-ctime — время последнего изменения владельца или прав доступа к файлу (в днях);
-cmin — время последнего изменения владельца или прав доступа к файлу (в минутах);
-mtime — время последнего изменения файла (в днях);
-mmin — время последнего изменения файла (в минутах);
-newer другой_файл — искать файлы созданные позже, чем другой_файл;
-delete — удалять найденные файлы;
-ls — генерирует вывод как команда ls -dgils;
-print — показывает на экране найденные файлы;
-print0 — выводит путь к текущему файлу на стандартный вывод, за которым следует символ ASCII NULL (код символа 0);
-exec command {} \; — выполняет над найденным файлом указанную команду; обратите внимание на синтаксис;
-ok — перед выполнением команды указанной в -exec, выдаёт запрос;
-depth или -d — начинать поиск с самых глубоких уровней вложенности, а не с корня каталога;
-maxdepth — максимальный уровень вложенности для поиска. «-maxdepth 0» ограничивает поиск текущим каталогом;
-prune — используется, когда вы хотите исключить из поиска определённые каталоги;
-mount или -xdev — не переходить на другие файловые системы;
-regex — искать по имени файла используя регулярные выражения;
-regextype тип — указание типа используемых регулярных выражений;
-P — не разворачивать символические ссылки (поведение по умолчанию);
-L — разворачивать символические ссылки;
-empty — только пустые каталоги.
Примерно тоже самое, только больше и в не самом удобочитаемом виде, т.к надо делать запрос по каждому ключу отдельно, можно получить по
Результатам будет нечто такое из чего можно вычленять справку по отдельному ключу или команде (кликабельно):
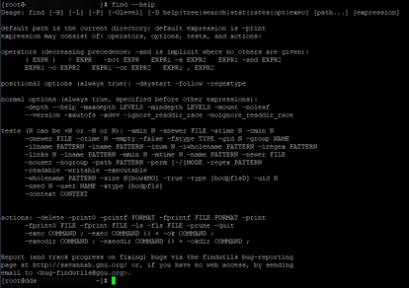
В качестве развлечения можно использовать:
Дабы получить мануал из самой системы по базису и ключам (тоже кликабельно);

Немного о примерах использования. Точно так же, оттуда же и тп. Просто для понимания как оно работает вообще. Наиболее просто, конечно, осознать это потренировавшись в той же консоли на реальной системе.
Найти и удалить файлы
Чтобы удалить все соответствующие файлы, добавьте опцию в конец выражения соответствия.
Убедитесь, что вы используете эту опцию, только если вы уверены, что результат соответствует файлам, которые вы хотите удалить. Рекомендуется распечатать соответствующие файлы перед использованием параметра.
Например, чтобы удалить все файлы, заканчивающиеся на из, вы должны использовать:
Используйте опцию с особой осторожностью. Командная строка find оценивается как выражение, и если вы сначала добавите параметр, команда удалит все, что находится ниже указанных вами начальных точек.. Когда дело доходит до каталогов, можно удалить только пустые каталоги так же, как .
Когда дело доходит до каталогов, можно удалить только пустые каталоги так же, как .
Сравнение файлов diff
Утилита diff linux — это программа, которая работает в консольном режиме. Ее синтаксис очень прост. Вызовите утилиту, передайте нужные файлы, а также задайте опции, если это необходимо:
$ diff опции файл1 файл2
Можно передать больше двух файлов, если это нужно. Перед тем как перейти к примерам, давайте рассмотрим опции утилиты:
- -q — выводить только отличия файлов;
- -s — выводить только совпадающие части;
- -с — выводить нужное количество строк после совпадений;
- -u — выводить только нужное количество строк после отличий;
- -y — выводить в две колонки;
- -e — вывод в формате ed скрипта;
- -n — вывод в формате RCS;
- -a — сравнивать файлы как текстовые, даже если они не текстовые;
- -t — заменить табуляции на пробелы в выводе;
- -l — разделить на страницы и добавить поддержку листания;
- -r — рекурсивное сравнение папок;
- -i — игнорировать регистр;
- -E — игнорировать изменения в табуляциях;
- -Z — не учитывать пробелы в конце строки;
- -b — не учитывать пробелы;
- -B — не учитывать пустые строки.
Это были основные опции утилиты, теперь давайте рассмотрим как сравнить файлы Linux. В выводе утилиты кроме, непосредственно, отображения изменений, выводит строку в которой указывается в какой строчке и что было сделано. Для этого используются такие символы:
- a — добавлена;
- d — удалена;
- c — изменена.
К тому же, линии, которые отличаются, будут обозначаться символом <, а те, которые совпадают — символом >.
Вот содержимое наших тестовых файлов:

Теперь давайте выполним сравнение файлов diff:

В результате мы получим строчку: 2,3c2,4. Она означает, что строки 2 и 3 были изменены. Вы можете использовать опции для игнорирования регистра:
Можно сделать вывод в две колонки:

А с помощью опции -u вы можете создать патч, который потом может быть наложен на такой же файл другим пользователем:

Чтобы обработать несколько файлов в папке удобно использовать опцию -r:

Для удобства, вы можете перенаправить вывод утилиты сразу в файл:

Как видите, все очень просто. Но не очень удобно. Более приятно использовать графические инструменты.
Expressions
The most common expression you will use is -name, which searches for the name of a file or folder.
There are, however, other expressions you can use:
- -amin n: The file was last accessed +/- n minutes ago, depending on how you enter the time.
- -anewer: Takes another file as reference to find any files that were accessed more recently and the reference file.
- -atime n: The file was last accessed more/fewer than n days ago, depending on the how you enter the target time (n).
- -cmin n: The file was last changed n minutes ago, depending on how you enter the target time (n).
- -cnewer: Takes another file as reference to find any files that were accessed more recently and the reference file.
- -ctime n: The file was last accessed more/fewer than n days ago, depending on the how you enter the target time (n).
- -empty: The file is empty.
- -executable: The file is executable.
- -false: Always false.
- -fstype type: The file is on the specified file system.
- -gid n: The file belongs to group with the ID n.
- -group groupname: The file belongs to the named group.
- -ilname pattern: Search for a symbolic link but ignore the case.
- -iname pattern: Search for a file but ignore the case.
-inum n: Search for a file with the specified inode.
-ipath path: Search for a path but ignore the case.
-iregex expression: Search for an expression but ignore the case.
-links n: Search for a file with the specified number of links.
-lname name: Search for a symbolic link.
-mmin n: The file was last accessed +/- n minutes ago, depending on how you enter the time.
-mtime n: The file was last accessed more/fewer than n days ago, depending on the how you enter the target time (n).
-name name: Search for a file with the specified name.
-newer name: Search for a file edited more recently than the reference file given.
-nogroup: Search for a file with no group id.
-nouser: Search for a file with no user attached to it.
-path path: Search for a path.
-readable: Find files that are readable.
-regex pattern: Search for files matching a regular expression.
-type type: Search for a particular type. Type options include:
- -type d: Directoris
- -type f: Files
- -type l: Symlinks
-uid uid: The file numeric user id is the same as the uid.
-user name: The file is owned by the user that is specified.
-writable: Search for files that can be written to.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая~шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
- $ — последняя строка в файле;
- /регулярное_выражение/ — любая строка, которая подходит по регулярному выражению. Модификатор l указывает, что регулярное выражение должно быть не чувствительным к регистру;
- номер, номер — начиная от строки из первой части и заканчивая строкой из второй части;
- номер, /регулярное_выражение/ — начиная от сроки из первой части и до сроки, которая будет соответствовать регулярному выражению;
- номер, +количество — начиная от номера строки указанного в первой части и еще плюс количество строк после него;
- номер, ~число — начиная от строки номер и до строки номер которой будет кратный числу.
Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \{i\} — любой символ в количестве i;
- \{i,j\} — любой символ в количестве от i до j;
- \{i,\} — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Найти файлы по типу
Иногда вам может потребоваться поиск определенных типов файлов, таких как обычные файлы, каталоги или символические ссылки. В Linux все является файлом.
Для поиска файлов по их типу используйте параметр и один из следующих дескрипторов, чтобы указать тип файла:
- : обычный файл
- : каталог
- : символическая ссылка
- : символьные устройства
- : блочные устройства
- : именованный канал (FIFO)
- : сокет
Например, чтобы найти все каталоги в текущем рабочем каталоге , вы должны использовать:
Типичным примером может быть рекурсивное изменение разрешений файлов веб-сайтов на и разрешений каталогов на с помощью команды :