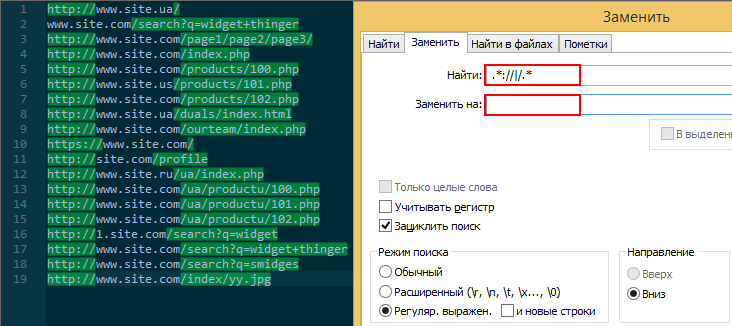
Элементы языка регулярных выражений
Содержание:
- Опережающие и ретроспективные проверки — (?=) and (?
- Заключение
- Применение регулярных выражений
- Метасимволы
- Максимализм квантификатора *
- Квантификаторы
- Строковые методы, поиск и замена
- Практические примеры сложных регулярных выражений
- Common Pitfalls
- Different Regular Expression Engines
- Флаги регулярных выражений
- Регулярные выражения
- Строковые методы, поиск и замена
- Принцип работы регулярных выраженийHow regular expressions work
- regexp.test(str)
- МетаСимволы
- Special characters
- Give Regexes a First Try
- Заключение
- Заключение
Опережающие и ретроспективные проверки — (?=) and (?
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> тест(?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения -> тест
Вы можете использовать оператор отрицания !
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> тест(?<!r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения -> тест
Заключение
Как вы могли убедиться, области применения регулярных выражений разнообразны. Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими:
- Валидация данных (например, правильно ли заполнена строка time)
- Сбор данных (особенно веб-скрапинг, поиск страниц, содержащих определённый набор слов в определённом порядке)
- Обработка данных (преобразование сырых данных в нужный формат)
- Парсинг (например, достать все GET параметры из URL или текст внутри скобок)
- Замена строк (даже во время написания кода в IDE, можно, например преобразовать Java или C# класс в соответствующий JSON объект, заменить “;” на “,”, изменить размер букв, избегать объявление типа и т.д.)
- Подсветка синтаксиса, переименование файла, анализ пакетов и многие другие задачи, где нужно работать со строками (где данные не должны быть текстовыми).
Перевод статьи Jonny Fox: Regex tutorial — A quick cheatsheet by examples
Применение регулярных выражений
Рассмотрим случаи, в которых используются регулярные выражения:
Поиск конкретных элементов в большом наборе текста. Например, вы можете выделить только адреса электронной почты из большого количества связанного (или несвязанного) текста.
Замена одних символов на другие. Например, вы можете очистить плохо отформатированные файлы с HTML-разметкой, заменив все теги, написанные в верхнем регистре, эквивалентами в нижнем регистре, используя текстовый редактор.
Проверка ввода. Например, вы можете проверить, соответствует ли пароль заданным критериям, таким как сочетание прописных и строчных букв, наличие цифр, знаков препинания и т.д.
Координация действий. Например, вы можете обрабатывать определенные файлы в каталоге только в том случае, если они удовлетворяют заданным критериям, описанным в командной строке.
И это не весь список применений регулярных выражений.
Давайте рассмотрим один простой пример. Следующее регулярное выражение выделит каждый экземпляр символа , за которым следует либо символ , либо символ :
Да, это не что-то сверхъестественное или мегаполезное. Но по мере того, как мы будем углубляться в тему регулярных выражений, примеры станут более практичными.
Метасимволы
Символ точки () является метасимволом. Метасимволы — это символы, которые имеют особое значение. Они помогают создавать более интересные шаблоны, чем просто набор конкретных символов. Практически всё, что мы будем рассматривать — будет метасимволами.
Точка () представляет собой любой символ. В следующем примере мы ищем символ , за которым следует любой символ, а за ним символ :
Важно отметить, что точка () соответствует только одному символу. Мы можем заставить её соответствовать более чем одному символу, используя множители, которые мы рассмотрим ниже
Кроме того, вы также можете искать несколько символов с помощью точки следующим образом:
В примере, приведенном выше, мы ищем букву , за которой следуют любые два символа, и за которыми следует .
Максимализм квантификатора *
Регулярное выражение .* всегда распространяет совпадение до конца строки. Это связано с тем, что .* стремится захватить все, что может. Впрочем, позднее часть захваченного может быть возвращена, если это необходимо для общего совпадения. Иногда это поведение вызывает немало проблем. Рассмотрим регулярное выражение для поиска текста, заключенного в кавычки. На первый взгляд напрашивается простое ».*», но попробуйте на основании того, что нам известно о .*, предположить, какое совпадение будет найдено в строке:
The name «McDonald’s» is said «makudonarudo» in Japanese
После совпадения первого символа » управление передается конструкции .*, которая немедленно захватывает все символы до конца строки. Она начинает нехотя отступать (под нажимом механизма регулярных выражений), но только до тех пор, пока не будет найдено совпадение для последней кавычки. Если прокрутить происходящее в голове, вы поймете, что найденное совпадение будет выглядеть так(выделено нижним подчеркиванием):
The name «McDonald’s» is said «makudonarudo» in Japanese
Найден совсем не тот текст, который мы искали. Это одна из причин, по которым не стоит злоупотреблять .*, – если не учитывать проблем максимального совпадения, эта конструкция часто приводит к неожиданным результатам.
Как же ограничить совпадение строкой «McDonald’s»? Главное – понять, что между кавычками должно находиться не «все, что угодно», а «все, что угодно, кроме кавычек». Если вместо .* воспользоваться выражением *, совпадение не пройдет дальше закрывающей кавычки.
При поиске совпадения для »*» механизм ведет себя практически так же. После совпадения первой кавычки * стремится захватить как можно большее потенциальное совпадение. В данном случае это совпадение распространяется до кавычки, следующей после McDonald’s. На этом месте поиск прекращается, поскольку не совпадает с кавычкой, после чего управление передается закрывающей кавычке в регулярном выражении. Она благополучно совпадает, обеспечивая общее совпадение:
The name «McDonald’s» is said «makudonarudo» in Japanese
На самом деле в этом примере возможен неожиданный поворот, связанный с тем, что в большинстве диалектов может совпадать с символом новой строки, a . – не может. Если вы хотите предотвратить возможный выход за границу логической строки, используйте выражение .
Квантификаторы
Квантификаторы можно использовать для сопоставления символов более одного раза. Существует несколько типов, которые перечислены в синтаксисе Java Regex. Наиболее часто используемые:
String regex = "Hello*";
Это регулярное выражение сопоставляет строки с текстом «Hell», за которым следует ноль или более символов. Таким образом, регулярное выражение будет соответствовать «Hell», «Hello», «Helloo» и т. д.
Если бы квантификатором был символ + вместо символа *, строка должна была бы заканчиваться 1 или более символами o.
String regex = "Hell\\+";
Будет соответствовать строке «Hell+»;
String regex = "Hello{2}";
Будет соответствовать строке «Helloo»(с двумя символами o в конце).
String regex = "Hello{2,4}";
Будет соответствовать строкам “Helloo”, “Hellooo” и “Helloooo”. Другими словами, строка «Hell» с 2, 3 или 4 символами в конце.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Практические примеры сложных регулярных выражений
Теперь, когда вы знаете теорию и основной синтаксис регулярных выражений в PHP, пришло время создать и проанализировать некоторые более сложные примеры.
1) Проверка имени пользователя с помощью регулярного выражения
Начнем с проверки имени пользователя. Если у вас есть форма регистрации, вам понадобится проверять на правильность имена пользователей. Предположим, вы не хотите, чтобы в имени были какие-либо специальные символы, кроме «» и, конечно, имя должно содержать буквы и возможно цифры. Кроме того, вам может понадобиться контролировать длину имени пользователя, например от 4 до 20 символов.
Сначала нам нужно определить доступные символы. Это можно реализовать с помощью следующего кода:
После этого нам нужно ограничить количество символов следующим кодом:
{4,20}
Теперь собираем это регулярное выражение вместе:
^{4,20}$
В случае Perl-совместимого регулярного выражения заключите его символами ‘‘. Итоговый PHP-код выглядит так:
<?php
$pattern = '/^{4,20}$/';
$username = "demo_user-123";
if (preg_match($pattern, $username)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
2) Проверка шестнадцатеричного кода цвета регулярным выражением
Шестнадцатеричный код цвета выглядит так: , также допустимо использование краткой формы, например . В обоих случаях код цвета начинается с и затем идут ровно 3 или 6 цифр или букв от a до f.
Итак, проверяем начало кода:
^#
Затем проверяем диапазон допустимых символов:
После этого проверяем допустимую длину кода (она может быть либо 3, либо 6). Полный код регулярного выражения выйдет следующим:
^#(({3}$)|({6}$))
Здесь мы используем логический оператор, чтобы сначала проверить код вида , а затем код вида . Итоговый PHP-код проверки регулярным выражением выглядит так:
<?php
$pattern = '/^#(({3}$)|({6}$))/';
$color = "#1AA";
if (preg_match($pattern, $color)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
3) Проверка электронной почты клиента с использованием регулярного выражения
Теперь давайте посмотрим, как мы можем проверить адрес электронной почты с помощью регулярных выражений. Сначала внимательно рассмотрите следующие примеры адресов почты:
john.doe@test.com john@demo.ua john_123.doe@test.info
Как мы можем видеть, символ является обязательным элементом в адресе электронной почты. Помимо этого должен быть какой-то набор символов до и после этого элемента. Точнее, после него должно идти допустимое доменное имя.
Таким образом, первая часть должна быть строкой с буквами, цифрами или некоторыми специальными символами, такими как . В шаблоне мы можем написать это следующим образом:
^+
Доменное имя всегда имеет, скажем, имя и tld (top-level domain) – т.е, доменную зону. Доменная зона – это , , и тому подобное. Это означает, что шаблон регулярного выражения для домена будет выглядеть так:
+\.{2,5}$
Теперь, если мы соберем все в кучу, то получим полный шаблон регулярного выражения для проверки адреса электронной почты:
^+@+\.{2,5}$
В коде PHP эта проверка будет выглядеть следующим образом:
<?php
$pattern = '/^+@+\.{2,5}$/';
$email = "john_123.doe@test.info";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Надеемся, что сегодняшняя статья помогла вам при знакомстве с регулярными выражениями в PHP, а практические примеры пригодятся вам при использовании регулярных выражений в собственных PHP скриптах.
-
3059
-
35
-
Опубликовано 16/04/2019
-
PHP, Уроки программирования
Common Pitfalls
Catastrophic Backtracking. If your regular expression seems to take forever, or simply crashes your application, it has likely contracted a case of catastrophic backtracking. The solution is usually to be more specific about what you want to match, so the number of matches the engine has to try doesn’t rise exponentially.
Making Everything Optional. If all the parts in your regex are optional, it will match a zero-length string anywhere. Your regex will need to express the facts that different parts are optional depending on which parts are present.
Repeating a Capturing Group vs. Capturing a Repeated Group. Repeating a capturing group will capture only the last iteration of the group. Capture a repeated group if you want to capture all iterations.
Mixing Unicode and 8-bit Character Codes. Using 8-bit character codes like \x80 with a Unicode engine and subject string may give unexpected results.
Different Regular Expression Engines
A regular expression “engine” is a piece of software that can process regular expressions, trying to match the pattern to the given string. Usually, the engine is part of a larger application and you do not access the engine directly. Rather, the application invokes it for you when needed, making sure the right regular expression is applied to the right file or data.
As usual in the software world, different regular expression engines are not fully compatible with each other. The syntax and behavior of a particular engine is called a regular expression flavor. This tutorial covers all the popular regular expression flavors, including Perl, PCRE, PHP, .NET, Java, JavaScript, XRegExp, VBScript, Python, Ruby, Delphi, R, Tcl, POSIX, and many others. The tutorial alerts you when these flavors require different syntax or show different behavior. Even if your application is not explicitly covered by the tutorial, it likely uses a regex flavor that is covered, as most applications are developed using one of the programming environments or regex libraries just mentioned.
Флаги регулярных выражений
| Флаг | Описание |
|---|---|
| g | Позволяет найти все совпадения, а не останавливаться после первого совпадения (global match flag). |
| i | Позволяет выполнить сопоставление без учета регистра (ignore case flag). |
| m | Сопоставление производится по нескольким строкам. Обработка начальных и конечных символов (^ и $) производится по нескольким строкам, то есть сопоставление происходит с началом или концом каждой строки (разделители \n или \r), а не только с началом, или концом всей строки (multiline flag). |
| u | Шаблон будет расценен как последовательность кодовых точек Юникода (unicode flag). |
| y | Сопоставление происходит по индексу на который указывает свойство lastIndex этого регулярного выражения, при этом сопоставление не производиться по более позднему, или раннему индексу (sticky flag). |
Регулярные выражения
Регулярное выражение (оно же «регэксп», «регулярка» или просто «рег»), состоит из шаблона (также говорят «паттерн») и необязательных флагов.
Существует два синтаксиса для создания регулярного выражения.
«Длинный» синтаксис:
…И короткий синтаксис, использующий слеши :
Слеши говорят JavaScript о том, что это регулярное выражение. Они играют здесь ту же роль, что и кавычки для обозначения строк.
Регулярное выражение в обоих случаях является объектом встроенного класса .
Основная разница между этими двумя способами создания заключается в том, что слеши не допускают никаких вставок переменных (наподобие возможных в строках через ). Они полностью статичны.
Слеши используются, когда мы на момент написания кода точно знаем, каким будет регулярное выражение – и это большинство ситуаций. А – когда мы хотим создать регулярное выражение «на лету» из динамически сгенерированной строки, например:
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Принцип работы регулярных выраженийHow regular expressions work
Главный компонент обработки текста с помощью регулярных выражений — это механизм регулярных выражений, представленный в .NET объектом System.Text.RegularExpressions.Regex.The centerpiece of text processing with regular expressions is the regular expression engine, which is represented by the System.Text.RegularExpressions.Regex object in .NET. Как минимум, для обработки текста с использованием в регулярных выражений механизму регулярных выражений необходимо предоставить два следующих элемента:At a minimum, processing text using regular expressions requires that the regular expression engine be provided with the following two items of information:
-
Шаблон регулярного выражения для определения текста.The regular expression pattern to identify in the text.
В .NET шаблоны регулярных выражений определяются специальным синтаксисом или языком, который совместим с регулярными выражениями Perl 5 и добавляет дополнительные возможности, например сопоставление справа налево.In .NET, regular expression patterns are defined by a special syntax or language, which is compatible with Perl 5 regular expressions and adds some additional features such as right-to-left matching. Дополнительные сведения см. в разделе Элементы языка регулярных выражений. Краткий справочник.For more information, see Regular Expression Language — Quick Reference.
-
Текст, который будет проанализирован на соответствие шаблону регулярного выражения.The text to parse for the regular expression pattern.
Методы класса Regex позволяют выполнять следующие операции:The methods of the Regex class let you perform the following operations:
-
Получить один или все экземпляры текста, соответствующего шаблону регулярного выражения с помощью метода Regex.Match или Regex.Matches.Retrieve one or all occurrences of text that matches the regular expression pattern by calling the Regex.Match or Regex.Matches method. Первый метод возвращает объект System.Text.RegularExpressions.Match, который предоставляет сведения о соответствующем тексте.The former method returns a System.Text.RegularExpressions.Match object that provides information about the matching text. Второй метод возвращает объект MatchCollection, содержащий один объект System.Text.RegularExpressions.Match для каждого соответствия, обнаруженного в обработанном тексте.The latter returns a MatchCollection object that contains one System.Text.RegularExpressions.Match object for each match found in the parsed text.
-
Заменить текст, соответствующий шаблону регулярного выражения, с помощью метода Regex.Replace.Replace text that matches the regular expression pattern by calling the Regex.Replace method. Примеры использования метода Replace для изменения форматов даты и удаления недопустимых символов из строки см. в разделах Руководство. Исключение недопустимых символов из строки и Руководство. Изменение форматов даты.For examples that use the Replace method to change date formats and remove invalid characters from a string, see How to: Strip Invalid Characters from a String and Example: Changing Date Formats.
Обзор объектной модели регулярных выражений см. в разделе Объектная модель регулярных выражений.For an overview of the regular expression object model, see The Regular Expression Object Model.
Дополнительные сведения о языке регулярных выражений см. в кратком справочнике по элементам языка регулярных выражений или в одной из следующих брошюр, который вы можете скачать и распечатать:For more information about the regular expression language, see Regular Expression Language — Quick Reference or download and print one of these brochures:
- Краткий справочник в формате Word (DOCX);Quick Reference in Word (.docx) format
- Краткий справочник в формате PDF (PDF).Quick Reference in PDF (.pdf) format
regexp.test(str)
The method looks for a match and returns whether it exists.
For instance:
An example with the negative answer:
If the regexp has flag , then looks from property and updates this property, just like .
So we can use it to search from a given position:
Same global regexp tested repeatedly on different sources may fail
If we apply the same global regexp to different inputs, it may lead to wrong result, because call advances property, so the search in another string may start from non-zero position.
For instance, here we call twice on the same text, and the second time fails:
That’s exactly because is non-zero in the second test.
To work around that, we can set before each search. Or instead of calling methods on regexp, use string methods , they don’t use .
МетаСимволы
Для указания регулярных выражений используются метасимволы. В приведенном выше примере ( ) является метасимволом.
Метасимволы — это символы, которые интерпретируются особым образом механизмом RegEx. Вот список метасимволов:
[]. ^ $ * +? {} () \ |
— Квадратные скобки
Квадратные скобки указывают набор символов, которые вы хотите сопоставить.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 2 совпадения | ||
| Не совпадает | ||
| 5 совпадений |
Здесь будет соответствовать, если строка, которую вы пытаетесь сопоставить, содержит любой из символов , или .
Вы также можете указать диапазон символов, используя дефис в квадратных скобках.
то же самое, что и .
то же самое, что и .
то же самое, что и .
Вы можете дополСтрока (инвертировать) набор символов, используя символ вставки в начале квадратной скобки.
означает любой символ, кроме или или .
означает любой нецифровой символ.
— Точка
Точка соответствует любому одиночному символу (кроме новой строки ).
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение | ||
| 1 совпадение | ||
| 2 совпадения (содержит 4 символа) |
— Каретка
Символ каретки используется для проверки того, начинается ли строка с определенного символа.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 1 совпадение | ||
| Не совпадает | ||
| 1 совпадение | ||
| Нет совпадений (начинается с , но не сопровождается ) |
— доллар
Символ доллара используется для проверки того, заканчивается ли строка определенным символом.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 1 совпадение | ||
| Не совпадает |
— Звездочка
Символ звездочки соответствует предыдущему символу повторенному 0 или более раз. Эквивалентно {0,}.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 1 совпадение | ||
| 1 совпадение | ||
| Нет совпадений ( не следует ) | ||
| 1 совпадение |
— Плюс
Символ плюс соответствует предыдущему символу повторенному 1 или более раз. Эквивалентно {1,}.
| Выражение | Строка | Совпадения |
|---|---|---|
| Нет совпадений (нет символа) | ||
| 1 совпадение | ||
| 1 совпадение | ||
| Нет совпадений ( не следует ) | ||
| 1 совпадение |
— Вопросительный знак
Знак вопроса соответствует нулю или одному вхождению предыдущего символа. То же самое, что и {0,1}. По сути, делает символ необязательным.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение (0 вхождений а) | ||
| 1 совпадение | ||
| Нет совпадений (более одного символа) | ||
| Нет совпадений ( не следует ) | ||
| 1 совпадение |
— Фигурные скобки
Рассмотрим следующий код: . Это означает, по крайней мере , и не больше повторений предыдущего символа. При m=n=1 пропускается..
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение (в ) | ||
| 2 совпадения (при и ) | ||
| 2 совпадения (при и ) |
Посмотрим еще один пример. Это RegEx соответствует как минимум 2 цифрам, но не более 4-х цифр.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение (совпадение в ) | ||
| 3 совпадения ( , , ) | ||
| Не совпадает |
— Альтернация (или)
Альтернация (вертикальная черта) – термин в регулярных выражениях, которому в русском языке соответствует слово «ИЛИ». (оператор ).
Например: gr(a|e)y означает точно то же, что и gry.
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение (совпадение в ) | ||
| 3 совпадения (в ) |
Здесь сопоставьте любую строку, содержащую либо, либо
Чтобы примеСтрока альтернацию только к части шаблона, можно заключить её в скобки:
- найдёт или .
- найдёт или .
— Скобочные группы
Круглые скобки используются для группировки подшаблонов. Так, например, соответствует любой строке, которая соответствует либо или или с последующим
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение (совпадение в ) | ||
| 2 совпадения (в ) |
— обратная косая черта
Обратная косая черта используется для экранирования различных символов, включая все метасимволы. Например,
соответствует, если строка содержит , за которым следует . Здесь механизм RegEx не интерпретирует особым образом.
Если вы не уверены, имеет ли символ особое значение или нет, вы можете экранировать его косой чертой . Это гарантирует, что экранированный символ не будет компилироваться по-особенному.
Special characters
Escapes also allow you to specify individual characters that are otherwise hard to type. You can specify individual unicode characters in five ways, either as a variable number of hex digits (four is most common), or by name:
-
: 2 hex digits.
-
: 1-6 hex digits.
-
: 4 hex digits.
-
: 8 hex digits.
-
, e.g. matches the basic smiling emoji.
Similarly, you can specify many common control characters:
-
: bell.
-
: match a control-X character.
-
: escape ().
-
: form feed ().
-
: line feed ().
-
: carriage return ().
-
: horizontal tabulation ().
-
match an octal character. ‘ooo’ is from one to three octal digits, from 000 to 0377. The leading zero is required.
Give Regexes a First Try
You can easily try the following yourself in a text editor that supports regular expressions, such as EditPad Pro. If you do not have such an editor, you can download the free evaluation version of EditPad Pro to try this out. EditPad Pro’s regex engine is fully functional in the demo version.
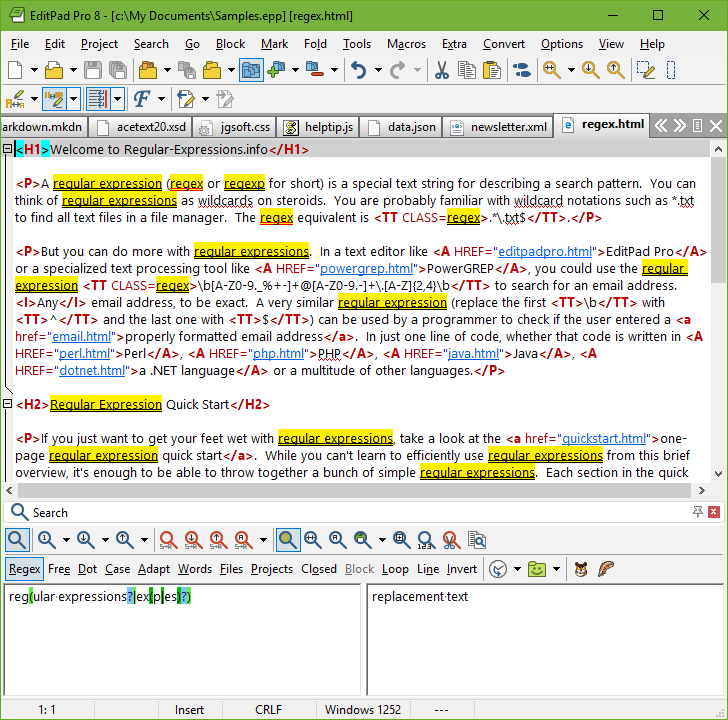
As a quick test, copy and paste the text of this page into EditPad Pro. Then select Search|Multiline Search Panel in the menu. In the search panel that appears near the bottom, type in regex in the box labeled “Search Text”. Mark the “Regular expression” checkbox, and click the Find First button. This is the leftmost button on the search panel. See how EditPad Pro’s regex engine finds the first match. Click the Find Next button, which sits next to the Find First button, to find further matches. When there are no further matches, the Find Next button’s icon flashes briefly.
Now try to search using the regex reg(ular expressions?|ex(p|es)?). This regex finds all names, singular and plural, I have used on this page to say “regex”. If we only had plain text search, we would have needed 5 searches. With regexes, we need just one search. Regexes save you time when using a tool like EditPad Pro. Select Count Matches in the Search menu to see how many times this regular expression can match the file you have open in EditPad Pro.
Заключение
В предыдущих статьях, были рассмотрены основы регулярных выражений, а также некоторые более сложные выражения, которые могут оказаться полезными. В следующих двух статьях объясняется, как разные символы или последовательности символов работают в регулярных выражениях.
Если после прочтения приведённых выше статей вы все еще путаетесь в регулярных выражениях, советуем вам продолжить практиковаться на примерах того, как другие люди придумывают регулярные выражения.
Оригинал статьи: https://code.tutsplus.com/tutorials/a-simple-regex-cheat-sheet—cms-31278/
Перевод: Земсков Матвей
Заключение
Резюмируем то, что мы узнали:
— соответствует любому символу;
— совпадает с символом из диапазона, содержащемуся в квадратных скобках;
— соответствует символам, которые не входят в диапазон, содержащийся в квадратных скобках;
— совпадение 0 или более раз с указанным элементом;
— совпадение 1 или более раз с указанным элементом;
— совпадение 0 или 1 раз с указанным элементом;
— точное совпадение раз с указанным элементом;
— точное совпадение от до раз с указанным элементом;
— точное совпадение или более раз с указанным элементом;
— экранирование или отмена специального значения указанного символа.