Postgresso 28
Содержание:
- Завязка
- Краткая история создания
- Microsoft Access
- Сообщение об ошибке
- Системы управления базами данных
- Архитектура PostgreSQL
- 2.1. Поддержка АТД в системе баз данных
- 2019
- pgAdmin
- Compatibility
- Преимущества и особенности СУБД PostgreSQL
- Our users us
- Notes
- Основные операции с БД
- Общие параметры настройки Permalink
- Что нового полезно знать про базы данных?
- PostgreSQL 14: Часть 5 или «весенние заморозки» (Коммитфест 2021-03)
Завязка
Я поддерживаю относительно большой проект, в котором есть публичный поиск по документам. В базе лежит ~500 тысяч документов общим объемом ~3,6 Гб. Суть поиска такова: пользователь заполняет форму, в которой есть и полнотекстовый запрос, и фильтрация по множеству полей в БД, в том числе и с join-ами.
Поиск работает (точнее, работал) через Sphinx, и работал не очень хорошо. Основные проблемы были такими:
- Индексирование отъедало порядка 8 Гб оперативной памяти. На сервере с 8 Гб ОЗУ это проблема. Память свопилась, это приводило к ужасной производительности.
- Индекс строился примерно 40 минут. Ни о какой консистентности поисковых результатов речи не шло, индексирование запускалось раз в день.
- Поиск работал долго. Особенно долго осуществлялись запросы, которым соответствовало большое количество документов: огромное количестов id-шников приходилось передавать из сфинкса в базу, и сортировать по релевантности на бэкэнде.
Из-за этих проблем возникла задача — оптимизировать полнотекстовый поиск. У этой задачи есть два решения:
- Подтюнить Sphinx: настроить realtime-индекс, хранить в индексе атрибуты для фильтрации.
- Использовать встроенный FTS PostgreSQL.
Решено было реализовывать второе решение: так можно нативно обеспечить автообновление индекса, избавиться от долгого общения между двумя сервисами и мониторить один сервис вместо двух.
Казалось бы, хорошее решение. Но проблемы поджидали впереди.
Начнем с самого начала.
Краткая история создания
PostgreSQL, первоначально называемый Postgres, был создан в UCB профессором по информатике Майклом Стоунбрейкером. Он начал работу в 1986 году в Postgres в качестве обновленного проекта своего предшественника Ingres и теперь принадлежит Computer Associates.

Основные периоды:
- 1977-1985 гг. — период, в котором был разработан проект под названием Ingres, а также найдено доказательство концепции для реляционных БД. В 1980 году была основана компания Ingres, которая в 1994 году была приобретена Computer Associates.
- 1986-1994 гг. — период, в котором была принята кодовая база POSTGRES. Хотя первоначальный вариант был в том, что это PostgreSQL не использовала кодовую базу в качестве своей основы. Кроме того, была разработана концепция в Ingres с акцентом на ориентацию объектов и язык запросов – Quel и коммерциализирован как Illustra.
- 1994-1995 гг. — в этот период была добавлена поддержка SQL. Выпущен Postgres 95, который позже, в 1996 году, был переиздан как PostgreSQL 6.0. Была создана глобальная команда разработчиков PostgreSQL с бесплатной системой постреляционной БД с открытым исходным кодом. Она применяется сегодня во всех операционных системах.
25-летняя история совершенствования PostgreSQL предоставляет огромный набор возможностей для разработчиков и администраторов баз данных, поставляемых на надежном сервере программного обеспечения, используемом во всем мире. PostgreSQL оценивается в 5 лучших базах данных DBEngine.
Microsoft Access
for TT in $(mdb-tables file.mdb); do
mdb-export -Q -d '\t' -D '%Y-%m-%d %H:%M:%S' file.mdb "$TT" > "${TT}.tsv"
done
for TT in $(mdb-tables file.mdb); do
mdb-export -D '%Y-%m-%d %H:%M:%S' file.mdb "$TT" > "${TT}.csv"
done
If the tablenames have embedded spaces…
mdb-tables -1 file.mdb| while read TT
do
mdb-export -D '%Y-%m-%d %H:%M:%S' file.mdb "$TT" > "${TT}.csv"
done
A shell script that may be useful for converting entire databases:
#!/bin/sh -e
mdbfn=$1
schemafn=$2
fkfn=$3
datafn=$4
schema=$5
tf=$(tempfile)
pre=""
&& pre="\"${schema}\"."
mdb-schema "${mdbfn}" postgres > "${tf}"
# Schema file
echo "BEGIN;\n" > "${schemafn}"
sp=""
&& echo "CREATE SCHEMA \"${schema}\";\n" >> "${schemafn}"
&& sp="SET search_path = \"${schema}\", pg_catalog;\n"
echo ${sp} >> "${schemafn}"
awk '($0 !~ /^ALTER TABLE.*FOREIGN KEY.*REFERENCES/) {print;}' "${tf}" >> "${schemafn}"
echo "\nEND;" >> "${schemafn}"
# Foreign keys file
echo "BEGIN;\n" > "${fkfn}"
echo ${sp} >> "${fkfn}"
awk '($0 ~ /^ALTER TABLE.*FOREIGN KEY.*REFERENCES/) {print;}' "${tf}" >> "${fkfn}"
echo "\nEND;" >> "${fkfn}"
# Data file
echo "BEGIN;\n" > "${datafn}"
echo "SET CONSTRAINTS ALL DEFERRED;\n" >> "${datafn}"
mdb-tables -1 "${mdbfn}" | while read TT
do
mdb-export -Q -d '\t' -D '%Y-%m-%d %H:%M:%S' "${mdbfn}" "$TT" > "${tf}"
awk -v pre="${pre}" -v TT="${TT}" \
'(NR==1) {gsub(/\t/,"\",\""); print "COPY " pre "\"" TT "\"(\"" $0 "\") FROM stdin;";}' "${tf}" >> "${datafn}"
awk '(NR>1) {gsub(/\t\t/,"\t\\N\t"); gsub(/\t$/,"\t\\N"); gsub(/\t\t/,"\t\\N\t"); print;}' "${tf}" >> "${datafn}"
echo "\\.\n" >> "${datafn}"
done
echo "END;" >> "${datafn}"
rm -f "${tf}"
If this script is saved to the file access2psql.sh and made executable, then it would be used as follows:
access2psql.sh file.mdb schema.sql foreignkeys.sql data.sql pg_schema_name psql -f schema.sql pg_db_name psql -f data.sql pg_db_name psql -f foreignkeys.sql pg_db_name
This script won’t work properly if there are tab characters in text columns, though the call to mdb-export could be modified to export INSERT statements to fix this. Also, mdb-schema has trouble representing multi-column foreign keys, so foreignkeys.sql may need some manual editing.
- Microsoft Access to PostgreSQL Conversion by Jon Hutchings (2001-07-20)
Сообщение об ошибке
Пользователи иногда получают сообщение об ошибке Postgresql:
ERROR: must be owner of relation .
Но не стоить беспокоиться, это сообщение означает, что пользователь не владеет таблицей, которую пытается изменить. Например, у него возникла проблема с запуском некоторых ALTER TABLE операторов. И оказалось, что пользователь не зарегистрировал свое имя, поэтому не имеет права исправлять таблицы.
Для исправления этого сбоя нужно просто отправить электронное письмо администратору базы данных, рассказать ему, в чем проблема, и он исправит разрешение. После этого все ALTER TABLE команды будут работать отлично. Можно также посмотреть таблицы в базе данных, выполнив эту команду из командной строки: \ d. Данная команда Postgresql покажет что-то вроде этого (см. фото).

Системы управления базами данных
Базы данных предназначены для структурированного хранения и быстрого доступа к различным данным. Каждая база данных, кроме самих данных, должна иметь определенную модель работы, по которой будет выполняться обработка данных. Для управления базами данных используются СУБД или системы управления базами данных, именно к таким программам относятся MySQL и Postgresql.
Реляционные системы управления базами данных позволяют размещать данные в таблицах, связывая строки из разных таблиц и, таким образом, связывая разные, объединенные логически данные. Перед тем, как вы сможете сохранять данные, необходимо создать таблицы определенного размера и указать тип данных для каждого столбца. Столбы представляют поля данных, а сами данные размещены в строках. Обе системы управления базами данных, и MySQL vs Postgresql принадлежат к реляционным. Дальше мы рассмотрим подробнее чем отличаются обе программы. А теперь перейдем к более детальному рассмотрению.
Архитектура PostgreSQL
Одной из наиболее сильных сторон СУБД PostgreSQL является архитектура. Как и в случаях со многими коммерческими СУБД, PostgreSQL можно применять в среде клиент-сервер — это предоставляет множество преимуществ и пользователям, и разработчикам.
В основе PostgreSQL — серверный процесс базы данных, выполняемый на одном сервере. Также стоит сказать, что в Postgres пока не реализована технология высокой готовности, как это сделано в ряде других коммерческих систем управления базами данных уровня предприятия (они способны распределять нагрузку между некоторым количеством серверов, достигая дополнительной масштабируемости и повышенной устойчивости к внешним воздействиям).
Доступ из приложений к данным базы PostgreSQL производится с помощью специального процесса базы данных. То есть клиентские программы не могут получать самостоятельный доступ к данным даже в том случае, если они функционируют на том же ПК, на котором осуществляется серверный процесс.
Таким образом мы получаем разделение клиентов и сервера, что даёт возможность создавать распределённые системы. К примеру, мы можем отделить клиентов от сервера с помощью сети, разрабатывая клиентские приложения в среде, которая удобна для пользователя. Допустим, появляется возможность реализовать базу данных под UNIX, создав клиентские приложения, которые станут работать в ОС Microsoft Windows.
Давайте посмотрим на типичную модель распределенного приложения СУБД PostgreSQL:
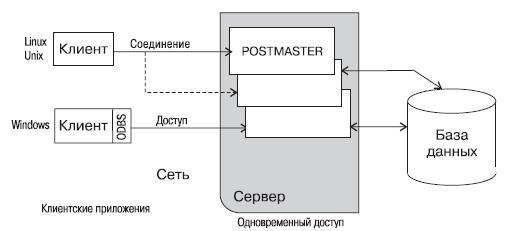
Мы видим, что несколько клиентов подсоединены к серверу по сети. СУБД PostgreSQL ориентирована на протокол TCP/IP (локальная сеть либо Интернет), при этом каждый клиент соединён с главным серверным процессом БД (на схеме этот процесс называют Postmaster). Именно Postmaster создаёт новый серверный процесс специально в целях обслуживания запросов на доступ к данным определённого клиента.
Так как манипулирование с данными сосредотачивается на сервере, СУБД PostgreSQL не приходится контролировать многочисленных клиентов, которые получают доступ в совместно используемый серверный каталог. В результате база данных PostgreSQL способна поддерживать целостность данных даже в случае одновременного доступа большого числа пользователей.
Соединение с базой данных клиентских приложений осуществляется по специальному протоколу СУБД PostgreSQL. В принципе, никто не мешает инсталлировать на стороне клиента ПО, предоставляющее стандартный интерфейс, обеспечивающий работу с нужным приложением, допустим, по стандарту ODBC/JDBC. И это хорошо, ведь доступность ODBC-драйвера даёт возможность использовать СУБД PostgreSQL в качестве базы данных для множества уже существующих приложений, включая продукты Microsoft Office — Excel и Access.
Идём дальше. Клиент-серверная архитектура, реализованная в СУБД PostgreSQL, делает возможным разделение труда. То есть машина-сервер прекрасно подходит для хранения и управления доступом к огромным объёмам данных, то есть её можно использовать в качестве надёжного репозитория. При этом для клиентов возможна разработка сложных графических приложений. Также можно создать внешний онлайн-интерфейс, предоставляющий доступ к данным и возвращающий результат в виде web-страниц в стандартный web-браузер, не требуя при этом никакого дополнительного клиентского ПО.
2.1. Поддержка АТД в системе баз данных
2.1.3. Расширяемые методы доступа для новых типов данных
Многообещающие возможности расширяемых методов доступа Postgres вдохновили один из моих первых исследовательских проектов в конце аспирантуры: обобщенные деревья поиска (Generalized Search Trees—GiST) [] и последующую концепцию теории индексируемости []. Я реализовал GiST в Postgres в течение семестра после получения докторской степени, что сделало добавление новой логики индексирования в Postgres еще проще. В диссертации Марселя Корнакера из Беркли (Marcel Kornacker) решены сложные задачи восстановления и одновременного доступа, поставленные расширяемым «шаблонным» типом индекса GiST [].
2.1.4. Оптимизатор обработки запросов с дорогостоящими UDF
Когда я поступил в аспирантуру, это была одна из трех тем, которые Стоунбрейкер написал на доске в своем кабинете как варианты для выбора темы моей диссертации. Кажется, второй темой было индексирование функций, а третьей я не помню.По иронии судьбы, код, написанный мною в аспирантуре, был полностью удален из дерева исходных текстов PostgreSQL молодым программистом по имени Нил Конвей (Neil Conway), который несколько лет спустя начал делать кандидатскую диссертацию под моим руководством в Калифорнийском университете в Беркли и теперь является одним из «кандидатских внуков» Стоунбрейкера.
2019
Включение в продукты DeviceLock
22 октября 2019 года стало известно, что DeviceLock включил в свои продукты поддержку Postgres Pro и PostgreSQL. Подробнее .
Запуск программы сертификации специалистов по СУБД PostgreSQL
21 мая 2019 года Postgres Professional сообщил о запуске программы сертификации специалистов по СУБД PostgreSQL.
Программа сертификации предусматривает три уровня с возрастающей квалификацией:
- «Профессионал»
- «Эксперт»
- «Мастер»
Для получения сертификата необходимо пройти тестирование в офисе компании Postgres Professional и набрать проходной балл. Материалом для подготовки могут служить авторские курсы Postgres Professional, доступные на сайте, а также регулярно читаемые в сертифицированных учебных центрах. Ежегодно слушателями курсов становятся более 500 человек.
Тест для первого уровня — «Профессионал» — включает в себя 50 вопросов по основам администрирования PostgreSQL и длится 75 минут. Поскольку для каждого релиза PostgreSQL характерны свои особенности администрирования, сертификация соотносится с конкретной версией СУБД. Например, на май 2019 года доступен тест для 10-ой версии PostgreSQL DBA1-10. Для прошедших тестирование на знание PostgreSQL 10 и желающих в будущем подтвердить свои навыки для 11-ой версии достаточно будет пройти короткое дополнительное тестирование, сфокусированное на отличиях продуктов.
Для получения сертификата уровня «Эксперт» понадобится успешно пройти уже три теста:
- DBA2-10 (настройка и мониторинг PostgreSQL)
- DBA3-10 (резервное копирование и репликация PostgreSQL)
- QPT-10 (оптимизация запросов)
А переход на уровень «Мастер» предполагает выполнение практических заданий по работе с PostgreSQL. В дальнейших планах компании Postgres Professional – запуск программы сертификации для разработчиков приложений на PostgreSQL.
Иван Панченко прокомментировал запуск программы сертификации:
|
Специалисты по Postgres становятся все более востребованными на российском рынке, что подтверждают данные кадровых агентств. В такой ситуации необходимы единые стандарты и критерии для оценки уровня знаний. Во многом наша программа сертификации стала ответом на запросы заказчиков и партнеров, заинтересованных в независимом инструменте оценки и повышения квалификации своих сотрудников. Иван Панченко, заместитель генерального директора Postgres Professional |
Совместимость с Live Universal Interface
15 апреля 2019 года компания ФОРС Телеком сообщила о появлении в экосистеме программно-инструментальных средств, совместимых с открытой платформой Postgres Pro/PostgreSQL конструктора пользовательских веб-интерфейсов к базам данных — Live Universal Interface (LUI). Подробнее здесь.
Совместимость с TerraLink xDE
12 марта 2019 года TerraLink сообщил, что TerraLink xDE поддерживает OC семейства Linux и СУБД PostgreSQL. Подробнее .
pgAdmin
Им многие пользуются, но, скорее по привычке. Или потому что это бесплатно. pgAdmin4 — продукт странноватый, при этом в описании сказано, что это самый лучший опенсорс продукт для разработки и администрирования.
Как его использовать для администрирования — не очень понятно. pgAdmin’ом нельзя «заинитить» новый сервер, нельзя подправить pg_hba.conf или postgresql.conf. Видимо, имеются в виду скудные графики запросов в секунду, вывод подробностей конфигурации сервера и статистика в таблицах. Не уверен, в общем. Как вы испольуете pgAdmin для администрирования?
Как его использовать с точки зрения разработки — еще менее понятно. Субъективно, интерфейс в целом не удобен для разработки. Несмотря на то, что четвертую версию переписали на python + JS с jQuery, по сути, осталось всё то же самое.
Чтобы немного пояснить ситуацию, в голове разработчика такая картина: есть база на каком-то серваке, в ней — схемы, в схемах — таблицы и вьюхи. Т.е. таблица — максимум, 3-й уровень. А если база одна, то вообще второй уровень. Ткнул по таблице — увидел несколько первых строк.
В голове разработчика pgAdmin как-то так: «Смерть Кощеева на конце иглы, та игла в яйце, то яйцо в утке, та утка в зайце, тот заяц в сундуке, а сундук стоит на высоком дубу, и то дерево Кощей как свой глаз бережёт», а именно (см. картинку):
Есть группа серверов, в ней есть сервер, на сервере существуют базы, роли и т.д., из баз можно выбрать конкретную базу, в ней видно схемы, языки, еще бог знает что. В схемах можно выбрать нужную схему, в схеме 100500 всего, и где-то в конце списка «таблицы». В таблицах можно выбрать нужную таблицу, по ней надо кликнуть правой кнопкой мыши, там в большом списке выбираешь «view data», в этой «view data» есть «view first 100 rows» и уже там наконец-то смерть кощеева несколько строк для ознакомления.
Киллер-фичей pgAdmin является возможность дебажить хранимые процедуры pl/pgsql. Других бесплатных программ с этой возможностью я не встречал.
Compatibility
This command conforms to the SQL standard, except that the FROM and RETURNING
clauses are PostgreSQL
extensions, as is the ability to use WITH with UPDATE.
According to the standard, the column-list syntax should allow
a list of columns to be assigned from a single row-valued
expression, such as a sub-select:
UPDATE accounts SET (contact_last_name, contact_first_name) =
(SELECT last_name, first_name FROM salesmen
WHERE salesmen.id = accounts.sales_id);
This is not currently implemented — the source must be a list
of independent expressions.
Some other database systems offer a FROM option in which the target table is supposed
to be listed again within FROM. That is
not how PostgreSQL interprets
FROM. Be careful when porting
applications that use this extension.
Преимущества и особенности СУБД PostgreSQL
СУБД PostgreSQL использует для своих баз данных реляционную модель, поддерживая стандартный язык запросов SQL. При этом PostgreSQL предоставляет широкий спектр возможностей. Можно сказать, что Postgres обладает почти всеми возможностями, существующими в других базах данных (как коммерческих, так и Open Source), а также рядом дополнительных.
Сегодня СУБД PostgreSQL работает почти на всех UNIX-платформах, в том числе и на UNIX-подобных системах (FreeBSD и Linux). Вы сможете использовать эту базу данных и на Windows NT Server, и на Windows 2000 Server, и для разработки рабочих станций ME.
Рассмотрим краткий перечень преимуществ и функциональных возможностей СУБД PostgreSQL:
1. Надежность. Надёжность СУБД PostgreSQL проверена и доказана. Она обеспечивается соответствием принципам ACID (атомарность, изолированность, непротиворечивость, сохранность данных), многоверсионностью, наличием Write Ahead Logging (WAL) — общепринятого механизма протоколирования всех существующих транзакций. Сюда же стоит отнести и возможность восстановления базы данных Point in Time Recovery (PITR), репликацию, поддержку целостности данных на уровне схемы.
2. Производительность. В СУБД PostgreSQL она основана на применении индексов, наличии гибкой системы блокировок и интеллектуального планировщика запросов, использовании системы управления буферами памяти и кэширования. Не стоит забывать и про отличную масштабируемость при конкурентной работе.
3. Расширяемость. Для СУБД PostgreSQL это означает, что пользователь может настроить систему посредством определения новых функций, типов, языков, агрегатов, индексов и операторов. А объектная ориентированность СУБД PostgreSQL даёт возможность переносить логику приложения на уровень базы данных, а это, в свою очередь, заметно упрощает разработку клиентов, ведь вся бизнес-логика находится в БД. При этом функции в Postgres однозначно определяются названием, типами и числом аргументов.
4. Поддержка SQL. Её уже упоминали, однако кроме главных возможностей, которые присущи любой SQL-базе, PostgreSQL поддерживает схемы, подзапросы, внешние связки, правила, курсоры, наследование таблиц, триггеры и много чего ещё.
5. Поддержка многочисленных типов данных. СУБД PostgreSQL поддерживает численные (целые, денежные, с фиксированной/плавающей точкой), булевые, символьные, составные, сетевые типы данных, а также перечисление, типы «дата/время», геометрические примитивы, массивы, XML- и JSON-данные. Плюс можно создавать свои типы данных.
Конечно, это далеко не всё, но для общего понимания возможностей СУБД PostgreSQL вполне достаточно. Естественно, база данных заслуживает внимания, особенно если учесть, что она имеет открытый исходный код и распространяется свободно. Освоить эту СУБД вы cможете на курсе в OTUS.
Our users us
We are eagerly awaiting and will make it available in Early Access as soon as it’s released by the PostgreSQL community.
Ines Sombra, Engine Yard
… our customers are typically homeless shelters and food banks that don’t have thousands of dollars per-core to throw away, so we switched to PostgreSQL.
Jonathon Sisson, Database Administrator, Bowman Systems LLC
Quorum commit for synchronous replication in PostgreSQL 10 gives more options to extend our ability to promote database infrastructure with nearly zero downtime from the application perspective. This allows us to continuously deploy and update our database infrastructure without incurring long maintenance windows.
Curt Micol, Simple Finance
Skype has been using PostgreSQL as the main DB for most of our business needs right from the start.
Hannu Krosing, Skype
There was quite a bit of debate when we were deciding what tools would best serve as the foundation of FlightAware’s ambitious goals. For the underlying database, however, the choice to use PostgreSQL was quite clear from the very beginning.
David McNett, Chief Information Officer, FlightAware.com
Notes
See Chapter 11 for information
about when indexes can be used, when they are not used, and in
which particular situations they can be useful.
| Caution |
|
Hash index operations are not presently WAL-logged, so |
Currently, only the B-tree, GiST and GIN index methods support
multicolumn indexes. Up to 32 fields can be specified by default.
(This limit can be altered when building PostgreSQL.) Only B-tree currently supports
unique indexes.
An operator class can be specified
for each column of an index. The operator class identifies the
operators to be used by the index for that column. For example, a
B-tree index on four-byte integers would use the int4_ops class; this operator class includes
comparison functions for four-byte integers. In practice the
default operator class for the column’s data type is usually
sufficient. The main point of having operator classes is that for
some data types, there could be more than one meaningful
ordering. For example, we might want to sort a complex-number
data type either by absolute value or by real part. We could do
this by defining two operator classes for the data type and then
selecting the proper class when making an index. More information
about operator classes is in Section 11.9 and in Section 35.14.
For index methods that support ordered scans (currently, only
B-tree), the optional clauses ASC,
DESC, NULLS
FIRST, and/or NULLS LAST can be
specified to modify the sort ordering of the index. Since an
ordered index can be scanned either forward or backward, it is
not normally useful to create a single-column DESC index — that sort ordering is already
available with a regular index. The value of these options is
that multicolumn indexes can be created that match the sort
ordering requested by a mixed-ordering query, such as SELECT ... ORDER BY x ASC, y DESC. The NULLS options are useful if you need to support
«nulls sort low» behavior, rather than
the default «nulls sort high», in
queries that depend on indexes to avoid sorting steps.
For most index methods, the speed of creating an index is
dependent on the setting of .
Larger values will reduce the time needed for index creation, so
long as you don’t make it larger than the amount of memory really
available, which would drive the machine into swapping.
Use DROP INDEX to remove an
index.
Основные операции с БД
Чтобы выполнять базовые действия в СУБД, нужно знать язык запросов к базе данных SQL.
Создание базы данных
Для создания базы данных используется команда:
create database
В приведенном ниже примере создается база данных с именем proglib_db.
Рисунок 3 — Создание базы данных с именем proglib_db
Если забыть точку с запятой в конце запроса, знак «=» в приглашении postgres заменяется на «-». Это зачастую указывает на то, что необходимо завершить (дописать) запрос.
Рисунок 4 — вывод ошибки при создании базы данных
На рисунке 4 видно сообщение об ошибке из-за того, что в нашем случае база уже создана.
Создание нового юзера
Для создания пользователя существует команда:
create user
В приведенном ниже примере создается пользователь с именем author.
Рисунок 5 — Создание пользователя с именем author
При создании пользователя отобразится сообщение CREATE ROLE. Каждый пользователь имеет свои права (доступ к базам, редактирование, создание БД / пользователей и т. д.). Вы могли заметить, что столбец Attributes для пользователя author пуст. Это означает, что пользователь author не имеет прав администратора. Он может только читать данные и не может создать другого пользователя или базу.
Можно установить пароль для существующего пользователя.
С этой задачей справится команда :
postgres=#\password author
Чтобы задать пароль при создании пользователя, можно использовать следующую команду:
postgres=#create user author with login password 'qwerty';
Удаление базы или пользователя
Для этой операции используется команда : она умеет удалять как пользователя, так и БД.
drop database <database_name> drop user <user_name>
Данную команду нужно использовать очень осторожно, иначе удаленные данные будут потеряны, а восстановить их можно только из бэкапа (если он был).
Если вы укажете psql postgres (без имени пользователя), то postgreSQL пустит вас под стандартным суперюзером (postgres). Чтобы войти в базу данных под определенным пользователем, можно использовать следующую команду:
psql
Войдем в базу proglib_db под пользователем author. Выполним команду , чтобы выйти из текущей БД, а затем выполните следующую команду:
Рисунок 6 — Вход в базу данных proglib_db
Общие параметры настройки Permalink
Конфигурирование базы данных PostgreSQL может быть сложным процессом. Ниже приведены некоторые основные параметры конфигурации, рекомендуемые при использовании PostgreSQL в Linode. Все эти параметры более подробно описаны в руководстве по настройке PostgreSQL.
Директива Задача listen_addresses = ‘localhost’ По умолчанию Postgres прослушивает только localhost. Однако, редактируя этот раздел и заменяя localhostIP, можно заставить Postgres прослушивать другой IP-адрес. Используйте ‘*’ для прослушивания всех IP-адресов. max_connections = 50 Устанавливает точное максимальное количество подключений клиентов. Чем выше значение, тем больше ресурсов потребует Postgres. Необходимо отрегулировать это значение в зависимости от размера Linode и трафика, который ожидается от базы данных. shared_buffers = 128 МБ Как указано в официальной документации, эта директива изначально устанавливается на низкое значение. На платформе Linode это может быть 1/4 ОЗУ
wal_level При настройке экземпляра Postgres важно учитывать запись в журнале записи (WAL). WAL может сохранять базу данных в чрезвычайной ситуации, одновременно записывая и регистрируя
Поэтому изменения записываются, даже если машина теряет мощность. Перед настройкой рекомендуется прочитать руководство DSHL по пониманию WAL и официальную главу о надежности WAL . synchronous_commit = off При использовании Linode можно включить настоящую Директиву off. archive_mode = on Включение режима архивирования — это жизнеспособная стратегия увеличения избыточности ваших резервных копий.
Что нового полезно знать про базы данных?
В СУБД растут объемы данных и нагрузки. А это значит, что нужно держать нос по ветру и узнавать больше об инструментах и методах взаимодействия с базами данных. Чтобы этого добиться, лучше всего сходить на профильную конференцию (было бы странно, если бы мы не дали вам этот совет, правда?), или хотя бы почитать о самых актуальных проблемах области.
Какие тренды последних лет усиливаются в PostgreSQL прямо сейчас? Как не устроить highload на ровном месте? Где почитать про мифы и реальность СУБД в облаках? Об этом и многом другом мы поговорили с Николаем Самохваловым.
Николай — член программного комитета конференции HighLoad++, куратор секции Базы данных, а также основатель Postgres.ai и #RuPostgres.
PostgreSQL 14: Часть 5 или «весенние заморозки» (Коммитфест 2021-03)
8 апреля 2021 г. в 15:00 по московскому времени закончился мартовский коммитфест, а вместе с ним и прием изменений в PostgreSQL 14.
Напомню, что всё самое интересное о первых четырех коммитфестах можно найти в предыдущих статьях серии: июльский, сентябрьский, ноябрьский, январский.
В этой пойдет речь о последнем, мартовском. Заранее предупреждаю, что статья получилась огромная. Но плохо ли это? Чем длиннее список новых возможностей, тем лучше PostgreSQL 14! Это с одной стороны. А с другой, вовсе не обязательно читать всё подряд от начала и до конца. Текст состоит из описания патчей. В любом месте можно остановиться, с любого места можно начать.
А почитать есть о чем. Не верите? Вопросы на засыпку:
- Может ли один запрос параллельно выполняться на разных серверах?
- Как найти запрос из pg_stat_activity в pg_stat_statements?
- Можно ли добавлять и удалять секции секционированной таблицы не останавливая приложение?
- Как пустить разработчиков на прод чтобы они могли всё видеть, но ничего не могли изменить?
- Почему VACUUM после COPY FREEZE заново переписывает всю таблицу и что с этим делать?
- Можно ли сжимать TOAST чем-то кроме медленного zlib?
- Как понять сколько времени длится блокировка найденная в pg_locks?
- Для чего нужны CYCLE и SEARCH рекурсивному запросу?
- Текст функций на каких языках (кроме C) не интерпретируется при вызове?
Приступим.