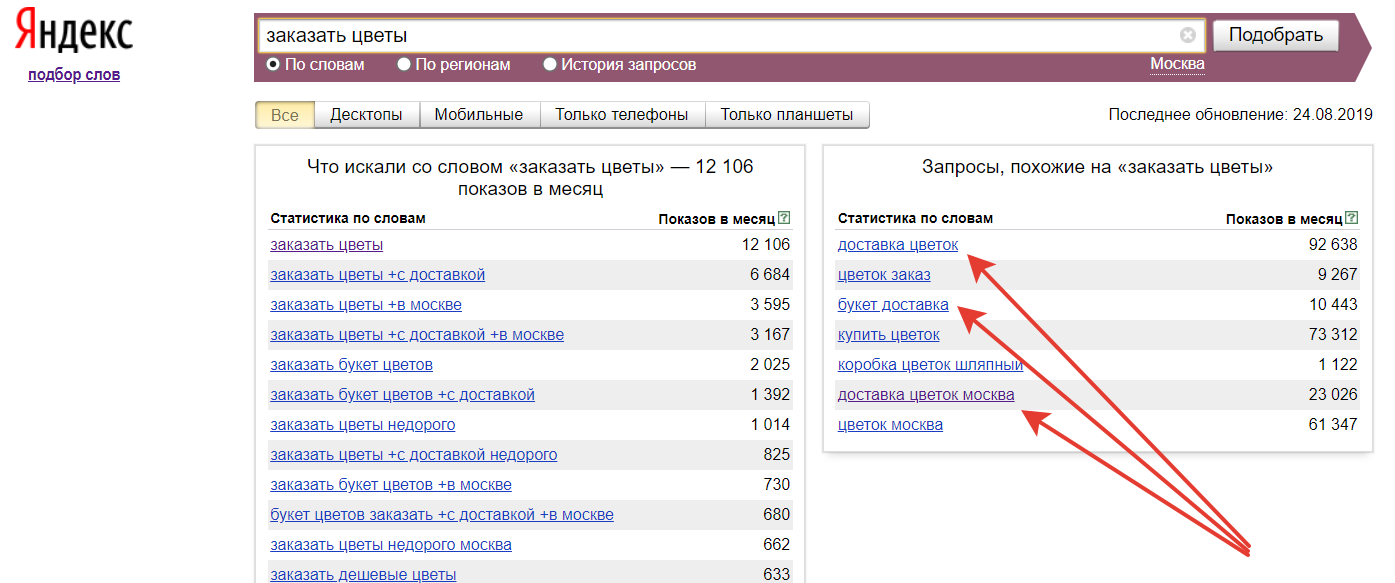
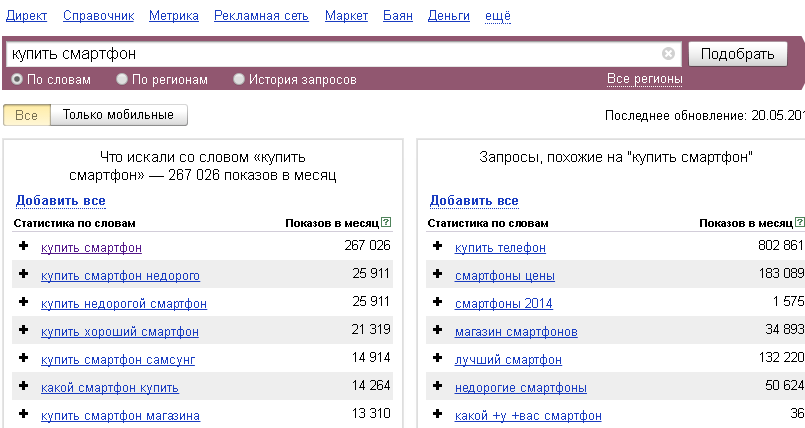
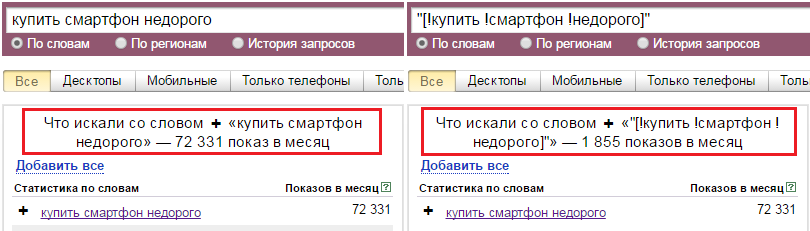
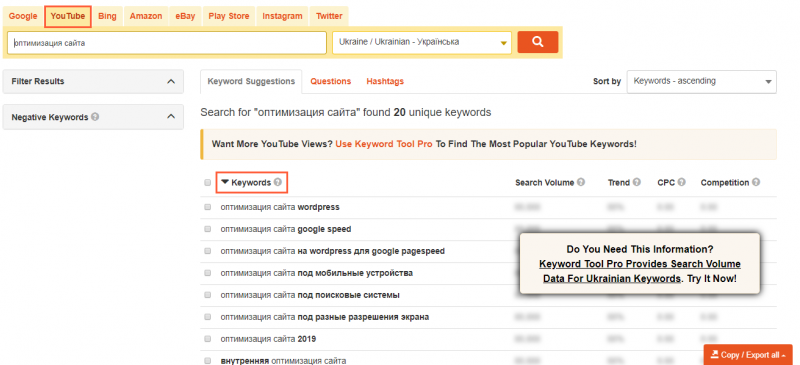
Парсер ключевых слов
Содержание:
- Парсинг вопросов-ответов в результатах поиска
- Основные возможности:
- Где и что парсить?
- Виды парсеров по сферам применения
- Советы и рекомендации по использованию программ для парсинга
- Как создать семантическое ядро?
- Варианты разбора
- Маркерные запросы
- Исключаем из парсинга отдельные группы товаров/услуг
- Зачем нужны парсеры
- Традиционный софт
Парсинг вопросов-ответов в результатах поиска
Вопросы/ответы можно извлекать и вручную из результатов поиска. Но зачем, если есть шаблон от Hannah Rampton?
Это один из шаблонов, который мы используем при поиске идей для контента и постановке ТЗ копирайтерам. Анализ вопросов, связанных с основным запросом, позволяет углубиться в тему и создать интент-ориентированный контент (подробнее — в нашей статье об алгоритме Neural Matching).
Для выгрузки вопросов/ответов:
- создайте копию шаблона Google Q&A Extraction_v2;
- установите бесплатное расширение Scraper для Chrome (оно парсит данные с веб-страниц с помощью XPath);
- измените в настройках поисковика язык с русского на английский (это нужно для корректной работы формул в шаблоне).
Приступаем к парсингу вопросов/ответов:
в открывшемся окне в блоке «Selector» выбираем «XPath», вводим в поле запрос для парсинга раскрывающихся списков с вопросами/ответами: //g-accordion-expander (обратите внимание, чтобы блок Columns был заполнен так же, как на скриншоте);
нажимаем «Scrape»;
- после парсинга нажимаем «Copy to clipboard»;
- открываем шаблон, переходим на лист «Google Questions and Answers», наводим курсор на ячейку А10 и нажимаем Ctrl+Shift+V.
Если все сделано верно, то поля с вопросами, ответами и URL заполнятся автоматически.
На листе «Clean Data» та же информация представлена в юзабельном текстовом формате (кроме того, здесь исключены дубли).
На листе «Search by Keyword» вы можете найти вопросы по заданному ключевому слову (или его части).
Также вы можете выбрать вопросы по домену — для этого на листе «Search by Domain» введите полный URL или его часть.
Таким образом, вы быстро и бесплатно найдете релевантные вопросы по вашей тематике.
Основные возможности:
Если Вы новичок, Вы научитесь создавать статейные сайты без затрат и рутины:
Вы хотите научится создавать сайты и даже сделали свой первый сайт, но столкнулись с тем, что нужен контент? Вы написали или купили несколько сотен статей, но Вам хочется иметь на сайте десятки тысяч страниц, чтобы собирать хороший трафик? И Вы видите, что вручную такой объем контента сделать не реально? И тут Вам поможет именно автоматический парсер статей по ключевым словам, который мы предлагаем. Если Ваш сайт сделан на WordPress, Вы с помощью одного лишь X-Parser, сможете создать и опубликовать тысячи качественных статей совершенно бесплатно. Вам всего лишь нужно задать ключевые слова, по которым бы Вы хотели парсить новости, выбрать формат сохранения WordPressXML в настройках, запустить парсер и уже через несколько минут будут собраны сотни статей по заданной Вами теме, готовые к публикации на сайте.
Наполнение сайтов контентом станет для Вас практически бесплатным:
Каждый, кто делает сайты знает, что наполнение сайта самый сложный процесс в его создании. Написание уникального текста занимает много времени, либо требует вложений на оплату работы копирайтера. Итого цена наполнения сайта контентом становится весьма ощутимой. X-Parser сэкономит Вам и то и другое, и поможет Вам автоматически создавать и публиковать качественные статьи с хорошими поведенческими факторами совершенно бесплатно. Если Ваш сайт уже находится в выдаче, получает трафик и Вы публикуете на нем какие-то материалы, Вы смело можете брать на вооружение наш парсер, собирать статьи по нужным ключевым словам и публиковать их в пропорции 70/30, где 70% — это копипаст, а 30% — это Ваши уникальные материалы. В результате объем материалов на Вашем сайта существенно возрастет, и Вы сэкономите солидную часть бюджета.
Вы сможете без затрат создавать сайты массово на любых языках, даже которыми не владеете:
Представьте, что Вы, не зная английский или румынский язык, создаете полноценные сайты на нем, он собирают трафик, люди их читают и все понимают. Как такое может быть? Ведь это видится не возможным. Это, безусловно, так, если Вы пишите контент сами, но если за Вас работает парсер контента, то все вполне реально. Как же это сделать спросите Вы? Для этого Вам нужно взять ключевые слова на интересующем Вас языке, распределить их по группам, спарсить контент при помощи X-Parser и опубликовать. X-Parser превосходно парсит контент на любых языках и с ним Вы сможете занимать ниши в любых языковых зонах. А если посмотреть на конкуренцию во многих из этих зон, то легко увидеть, что в отличие от русскоязычного сегмента она будет крайне низкой. А низкая конкуренция – это высокие позиции и больший траф.
Где и что парсить?
В прошлый раз мы смотрели объявления по ссылкам вида
Заголовок и текст объявления вы уже знаете как находить. Отсюда же можно взять и сайт компании. Остальная информация есть в карточке объявления. Нужно найти признаки этих ссылок:
- Сайт компании находится внутри тега span с классом domain.
- Ссылка на карточку имеет класс vcard.
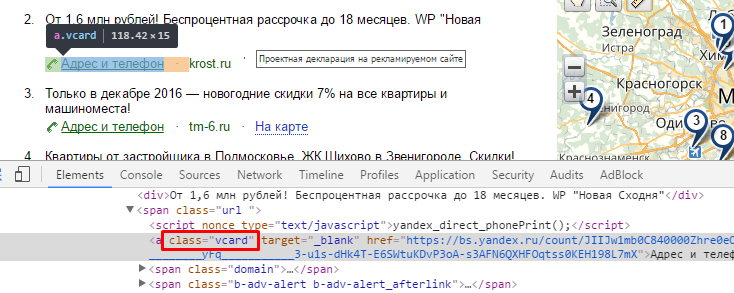 Ссылка на карточку имеет класс vcard
Ссылка на карточку имеет класс vcard
 Сайт компании находится внутри тега span с классом domain
Сайт компании находится внутри тега span с классом domain
На карточке объявления также ищем признаки нужных элементов. Нас будут интересовать:
- Название компании. Находится в заголовке с тегом h1.
- Телефон находится внутри элементов с классами contact-item call-button-container → large-text.
- Почта имеет класс email.
 Карточка объявления, где есть интересующие нас данные: название компании, телефон и электронная почта
Карточка объявления, где есть интересующие нас данные: название компании, телефон и электронная почта
Соберу всё в кучу:
1. Пройдитесь по всем ссылкам вида https://direct.yandex.ru/search?&rid=213&text=запрос&page=номер_страницы.
2. С этих страниц запишите в файл заголовок и текст объявления, а также домен сайта.
3. Найдите ссылку на карточку объявления, если она есть.
4. Соберите название компании, почту и номер телефона с карточки и запишите в файл.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Советы и рекомендации по использованию программ для парсинга
Специалисты советуют сочетать ручной и автоматический выбор запросов для составления семантического ядра, особенно для новичков. Пользуясь штатным инструментом Яндекс Вордстат Ассистент, вы нарабатываете навыки интуитивного подбора поисковых фраз, которые приводят на сайт целевых клиентов с помощью средне- и низкочастотных ключей. Высокочастотные фразы не всегда работают, особенно в конкурентной нише.
Если у вас нет времени на ручной парсинг в Яндекс Вордстат, используйте специальные инструменты. В интернете можно найти различное программное обеспечение, но большинство русскоязычных специалистов по SEO-оптимизации делают парсинг выдачи Яндекса с помощью Key Collector.
Это десктопный продукт, позволяющий создавать и хранить в локальной памяти компьютера проекты для каждого сайта, загружать и сохранять файлы и делать парсинг ключевых слов в соответствии с региональными настройками. Программа требует привязки к аккаунту. Для работы с ключевыми поисковыми запросами в Кей Коллекторе имеются пиктограммы основных поисковых систем в Рунете (в нашем случае это Yandex-парсер, хотя можно выбрать Google, Bing и другие).
Среди других полезных сервисов для SEO такие:
- Serpstat – многофункциональная платформа для профессионалов, имеющая триальную версию с ограниченным функционалом, а также платную подписку от 19 до 299$ в месяц;
- Ahrefs – веб-сервис с множеством полезных опций, включая мониторинг ниши, анализ конкурентов и улучшение индексации сайта. Для сбора семантического ядра предусмотрен инструмент Keywords Explorer. Протестировать его можно от 7$ в неделю;
- Semrush — аналог Ahrefs по части функционала, более дорогой по тарифам (от 99$ и выше).
Специалисты утверждают, что Кей Коллектор – это самая удобная и функциональная программа, позволяющая значительно облегчить жизнь оптимизатора. У нее есть множество полезных опций для точной настройки параметров парсера Yandex (например, глубины поиска, избирательного поиска запросов по базовой частотности и т.п.).
Но у программы есть нюанс – она платная. Стоимость лицензии составляет 1800-1900 рублей по электронному и безналичному расчету соответственно.
Совет! Если по какой-то причине вы не хотите пользоваться этим продуктом, можете попробовать его бесплатный аналог «Словоёб». Подойдет и более простой вариант — Букварикс – бесплатный сервис для сбора ключевых слов и формирования семантического ядра.
Парсинг Яндекс Вордстат можно делать самостоятельно и с помощью специальных программ. Ручной сбор посредством инструмента Wordstat Assistant оправдывает себя в том случае, если ваша ниша имеет узкую направленность и мало конкурентов, а перечень поисковых запросов относительно невелик. При больших объемах работ рекомендуется пользоваться специальными программами для парсинга и аналитики.
Как создать семантическое ядро?
Формирование семантического ядра — это комплексный процесс, включающий анализ тематики и структуры сайта, работу со специальными сервисами и программами, редактирование базы ключей вручную. Есть два основных принципа создания СЯ:
- подбор максимального количества ключей и дальнейшей очистки;
- подбор точных ключевых фраз с самого начала с последующим расширением базы.
Мы обратились к нескольким SEO-экспертам, чтобы узнать, какой подход они предпочитают.
Тарас Гуща, СЕО в SEO.UA, склоняется к первому методу:
Лучше много ключей и потом чистить. Потому как иногда можно упустить весьма стоящие ключевые фразы. Нам как профессионалам продвижения сайтов надо давать клиентам максимальный результат. Поэтому каждая ключевая фраза, которая может конвертировать потенциальную аудиторию в клиента, очень важна.
А вот Катерина Золотарева, Founder & CEO в Site24, считает, что в зависимости от выбранной стратегии можно использовать оба подхода:
Если проект небольшой или в сложной для формирования семантики нише, например, технологические услуги, то однозначно надо собирать все и даже больше, потом вычеркивать нерелевантное, а околотематические ключи отправлять в блог.
Также имеет смысл глубоко заниматься семантикой, если проект уже имеет позиции, трафик, а стандартные базовые ключи и так уже включены в метатеги и текст. Тогда глубокая проработка семантики поможет вам значительно улучшить видимость и трафик.
Этапы создания семантического ядра
Создание СЯ можно разделить на три этапа.
- Выбор подхода для создания СЯ.
Есть несколько стратегий того, как можно собрать семантического ядро. Их применяют в зависимости от того, имеет ли ресурс структуру или только находится в процессе разработки, какой у него уровень оптимизации, какие позиции по ключевым словам он занимает и т.д..
- Сбор запросов с помощью специальных инструментов.
Сервисы подбора ключевых слов дают возможность охватить максимальное число запросов и поисковых подсказок. Для лучшего результата стоит задействовать инструменты для анализа семантики конкурентов.
- Формирование СЯ из общей базы запросов.
Этапы преобразования облака тематических запросов в семантическое ядро включают два основных этапа:
- очистка базы ключей от ненужных запросов;
- кластеризация путем деления семантики на группы.
Также в процессе анализа ключей можно отделить минус-слова. Кластеризация базы запросов предшествует распределению ключевых фраз по URL. В следующих разделах мы рассмотрим все этапы разработки семантического ядра подробно.
Подходы при создании семантического ядра
Рассмотрим стандартные схемы для создания баз ключей. В зависимости от конкретного случая можно использовать один из подходов, приведенных ниже, или же индивидуальную стратегию.
ПЕРВЫЙ ПОДХОД — ФОРМИРОВАНИЕ СТРУКТУРЫ НОВОГО САЙТА НА ОСНОВЕ СЯ.
- Исследование рыночной ниши/торговой линейки/брифа клиента.
- Определение списка основных запросов (seed keywords).
- Сбор максимального количества фраз для каждого основного ключа.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Очистка полученного списка запросов от дублей и мусорных фраз (при наличии списка минус-слов).
- Автоматическая кластеризация через SE Ranking.
- Окончательная очистка запросов.
- Создание структуры сайта по разделам, категориям, страницам на основе кластеризации.
ВТОРОЙ ПОДХОД — СБОР СЯ ПОД ГОТОВУЮ СТРУКТУРУ САЙТА
- Анализ структуры и разделов сайта.
- Определение списка основных запросов.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Сбор максимального количества релевантных ключевых фраз для запросов из п. 2 и 3.
- Очистка от мусорных и нерелевантных фраз.
- Разделение собранных запросов под существующие категории и страницы.
ТРЕТИЙ ПОДХОД — ОБНОВЛЕНИЕ СЕМАНТИЧЕСКОГО ЯДРА ДЛЯ САЙТА.
- Анализ существующей семантики сайта.
- Поиск «слабых мест»: сбор актуальных запросов в тематике, изучение поисковых подсказок, анализ конкурентов для определения недостающих ключей.
- Создание списка упущенных запросов и распределение их по разделам, категориям, страницам.
Варианты разбора
- Решать задачу в лоб, то есть анализировать посимвольно входящий поток и используя правила грамматики, строить АСД или сразу выполнять нужные нам операции над нужными нам компонентами. Из плюсов — этот вариант наиболее прост, если говорить об алгоритмике и наличии математической базы. Минусы — вероятность случайной ошибки близка к максимальной, поскольку у вас нет никаких формальных критериев того, все ли правила грамматики вы учли при построении парсера. Очень трудоёмкий. В общем случае, не слишком легко модифицируемый и не очень гибкий, особенно, если вы не имплементировали построение АСД. Даже при длительной работе парсера вы не можете быть уверены, что он работает абсолютно корректно. Из плюс-минусов. В этом варианте все зависит от прямоты ваших рук. Рассказывать об этом варианте подробно мы не будем.
- Используем регулярные выражения! Я не буду сейчас шутить на тему количества проблем и регулярных выражений, но в целом, способ хотя и доступный, но не слишком хороший. В случае сложной грамматики работа с регулярками превратится в ад кромешный, особенно если вы попытаетесь оптимизировать правила для увеличения скорости работы. В общем, если вы выбрали этот способ, мне остается только пожелать вам удачи. Регулярные выражения не для парсинга! И пусть меня не уверяют в обратном. Они предназначены для поиска и замены. Попытка использовать их для других вещей неизбежно оборачивается потерями. С ними мы либо существенно замедляем разбор, проходя по строке много раз, либо теряем мозговые клеточки, пытаясь измыслить способ удалить гланды через задний проход. Возможно, ситуацию чуть улучшит попытка скрестить этот способ с предыдущим. Возможно, нет. В общем, плюсы почти аналогичны прошлому варианту. Только еще нужно знание регулярных выражений, причем желательно не только знать как ими пользоваться, но и иметь представление, насколько быстро работает вариант, который вы используете. Из минусов тоже примерно то же, что и в предыдущем варианте, разве что менее трудоёмко.
- Воспользуемся кучей инструментов для парсинга BNF! Вот этот вариант уже более интересный. Во-первых, нам предлагается вариант типа lex-yacc или flex-bison, во вторых во многих языках можно найти нативные библиотеки для парсинга BNF. Ключевыми словами для поиска можно взять LL, LR, BNF. Смысл в том, что все они в какой-то форме принимают на вход вариацию BNF, а LL, LR, SLR и прочее — это конкретные алгоритмы, по которым работает парсер. Чаще всего конечному пользователю не особенно интересно, какой именно алгоритм использован, хотя они имеют определенные ограничения разбора грамматики (остановимся подробнее ниже) и могут иметь разное время работы (хотя большинство заявляют O(L), где L — длина потока символов). Из плюсов — стабильный инструментарий, внятная форма записи (БНФ), адекватные оценки времени работы и наличие записи БНФ для большинства современных языков (при желании можно найти для sql, python, json, cfg, yaml, html, csv и многих других). Из минусов — не всегда очевидный и удобный интерфейс инструментов, возможно, придется что-то написать на незнакомом вам ЯП, особенности понимания грамматики разными инструментами.
- Воспользуемся инструментами для парсинга PEG! Это тоже интересный вариант, плюс, здесь несколько побогаче с библиотеками, хотя они, как правило, уже несколько другой эпохи (PEG предложен Брайаном Фордом в 2004, в то время как корни BNF тянутся в 1980-е), то есть заметно моложе и хуже выглажены и проживают в основном на github. Из плюсов — быстро, просто, часто — нативно. Из минусов — сильно зависите от реализации. Пессимистичная оценка для PEG по спецификации вроде бы O(exp(L)) (другое дело, для создания такой грамматики придется сильно постараться). Сильно зависите от наличия/отсутствия библиотеки. Почему-то многие создатели библиотек PEG считают достаточными операции токенизации и поиска/замены, и никакого вам AST и даже привязки функций к элементам грамматики. Но в целом, тема перспективная.
Маркерные запросы
Маркерные запросы — это запросы, которые четко отвечают продвигаемой странице. Такие запросы обычно имеют значимую частотность ключевых слов по Wordstat и являются средне-частотными (СЧ), или «жирными» низкочастотниками (НЧ), и могут породить «хвост» запросов, например при добавлении слов «купить», «цена», «отзывы».
Примеры:
Платья
Красные платья
Красные платья в пол
Телевизоры
Телевизоры Samsung
Телевизоры Самсунг
LED телевизоры Samsung
Стиральные машины
Стиральные машины для дачи
Стиральные машины шириной 40 см
Другими словами, эти ключевые слова часто являются названием страниц/категорий/статей/карточек товара и прочих типов страниц, которые вообще можно продвигать в поисковых системах.
Часто задаваемые вопросы про маркеры:
Q: Могут ли для страницы быть несколько маркеров?
A: Да — конечно — это довольно частый случай.
Например, на одну страницу могут идти такие маркеры как:
Телевизоры Samsung
Телевизоры Samsung купить
Телевизоры Самсунг
Телевизоры Самсунг купить
Телевизоры самсунг цена
Все эти запросы четко отвечают одной странице
Так же на одну страницу могут идти два маркера-синонима, не связанных лингвистически:
Спецоджеда
Рабочая одежда
или
электроплита бош
электрическая плита bosch
Это вполне нормально и логично.
НЕ маркеры — облако запросов. Это все второстепенные запросы, которые уточняют маркерные запросы — т.е. по факту это маркеры + 1/2/3 слова или синонимы маркеров. Как правило запросы из облака — менее частотные и поэтому мы будем привязывать их к маркерам
Как найти маркерные запросы?
Вариант №1: можно получить поисковые запросы из Яндекс Метрики. Плюсы такого метода — что вы сразу будете знать релевантные URL для этих запросов.
Вариант №2: Берем названия категорий/услуг своего сайта и расширяем их логическими гипотезами:«Как, по каким запросам пользователи еще могут искать эту страницу моего сайта? Какие есть синонимы?»
NB!: Отличным подспорьем в определении маркеров является старый добрый Яндекс Wordstat, при всех его недостатках. Рекомендуем использовать браузерный плагин Yandex Wordstat Assistant от компании Semantica — очень удобный — выполняет роль своего рода «заметок на полях» — в него можно в один клик добавить интересующие слова.
Мы понимаем, что не у каждого оптимизатора/владельца бизнеса есть под рукой департамент разработки, который быстро сможет выгрузить для сайта связку URL — название категории/страницы.
Что такое связка URL-название категории/страницы?
Поэтому есть 3 варианта как получить связку URL — название категории/страницы:
Фактически маркеры для вашего сайта будут состоять из:
- Запросов, выгруженных из Яндекс Метрики
- Названий категорий/страниц, взятых с сайта
- Расширений названий категорий/страниц т.е. логических гипотез
Важно выполнить эту часть работы по подбору семантического ядра максимально тщательно т.к. если вы потеряете большую часть маркеров — вы потеряете большую часть семантического ядра
Часто задаваемые вопросы по подбору маркеров:
Q: У меня большой сайт и маркеров сотни или тысячи — как быть?!
Q: На сколько низкочастотное слово может быть маркером?
A: Здесь все зависит от тематики. В узких тематиках даже ключевые слова с частотностью 15 по кавычкам «» могут быть маркерными запросами. Главное правило — спросите себя — хотел бы мой пользователь видеть отдельную страницу под этот запрос (и связанные с ним?). Удобно ли ему будет пользоваться той структурой, что я создаю?
Q: Как мне держать маркеры в Excell, чтобы потом мне было удобно с ними работать?
A: Идеальный и единственно правильный вариант — всегда держать связку URL-маркер в Excel — так вы всегда сможете понимать какие маркеры идут на один URL, даже если ваш список перемешается.
В дальнейшем таким образом вы сможете фильтровать целые кластеры, которые идут на одну страницу — это может быть и 10 и 50 ключевых слов. Очень удобно.
Пример правильного оформления маркеров в Excel
Итак, после N времени работы мы собрали маркеры для всего сайта (или части сайта), что дальше?
Естественно, что маркеры, это далеко не полная семантика — теперь нам нужно собрать облако запросов — расширить наше семантическое ядро.
Исключаем из парсинга отдельные группы товаров/услуг
Ассортимент товаров или услуг конкурентов не всегда совпадает с вашим. Например, конкуренты могут предлагать дополнительные услуги, которых нет у вас. Или охватывают более широкий ассортимент.
Соответственно, в рекламных кампаниях таких конкурентов будут ключевые слова и объявления, которые не подойдут вам.
Исключите нерелевантные ключи и объявления при парсинге, чтобы получить «чистые» результаты.
Перед запуском парсинга добавьте в поле «Минус-слова» перечень товаров или услуг, которые необходимо исключить из результатов. Также исключите сущности, которые не подходят для рекламы ваших товаров: «бесплатно», «подарок», «бу» и т. д.
Снимите галочку с пункта «Точное вхождение без учета морфологии».
В нашем примере система спарсит релевантные ключевые слова, исключив фразы типа «кухни на заказ», «офисная мебель недорого», «ремонт мебели» и т. д.
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
- Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
- Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
- Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
- Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Традиционный софт
Ниже представлена надежная классика среди инструментов для подбора ключевых запросов.
1. Microsoft Office Excel
Excel был и остается самой лучшей программой для сбора семантического ядра и дальнейшей работы с ним. После использования различных кластеризаторов, группировщиков, все в итоге попадает в Excel для дальнейшей доработки.
2. OpenOffice + Скрипт для упрощения классификации запросов от Сергея Кокшарова
OpenOffice — офисный программный пакет с открытым исходным кодом для обработки текстов, электронных таблиц, презентаций, графики, баз данных и многого другого.
Он доступен на многих языках. Хранит все ваши данные в международном формате открытого стандарта, а также может читать и записывать файлы из других распространённых офисных пакетов программного обеспечения. Его можно скачать и использовать совершенно бесплатно для любых целей.
OpenOffice — аналог Microsoft Excel, но в комбинации с макросом от Сергея Кокшарова (Devaka), он превращается в кластеризатор запросов с возможностью дальнейшей быстрой доработки.
3. Google Sheets
Google Sheets — все чаще используются как альтернатива Excel, но функционал и возможности еще не сопоставимы. Бесплатный функционал, удобный интерфейс и функция автосохранения делает Google Sheets еще привлекательнее для специалистов.
4. XMind
XMind — удобная программа для проектирования наглядной структуры сайта, создания схем перелинковки и mind maps с маркетинговыми стратегиями.
Подходит для платформ: Windows, macOS, Linux, iOS и Android.
Платная — 39,99$/6 мес., 59,99$/год. Есть тестовая версия.
5. MindMeister
MindMeister — онлайн-сервис для построения структуры сайта. При количестве страниц более 1000, начинает притормаживать. Удобен для использования, когда необходима одновременная работа нескольких членов команды над структурой.
Платная — от 2,49$ до 6,29$ в месяц в зависимости от выбранного тарифного плана.
Есть базовая тестовая версия.
|
Название |
Описание |
Тарифы |
Trial |
|
Microsoft Office Excel |
Программа для создания сводных таблиц |
от 69,99$/год (пакет Microsoft Office) |
Есть |
|
OpenOffice + Скрипт Devaka |
Программа для создания сводных таблиц + кластеризация запросов |
Бесплатно |
Есть |
|
Google Sheets |
Аналог Excel от Google |
Бесплатно |
Есть |
|
XMind |
Программа для проектирования наглядной структуры сайта |
39,99$/6 мес., 59,99$/год. |
Есть |
|
MindMeister |
Онлайн-сервис для построения структуры сайта |
от 2,49$ до 6,29$ в месяц |
Есть |