Кодировка utf
Содержание:
- UTF-8 Basic Latin
- Тег
- Range: Decimal 768-879. Hex 0300-036F.
- keywords (ключевые слова)
- Резюме
- Немного теории
- Кодирование и декодирование
- Недостатки и достоинства
- How does it work?
- Range: Decimal 8448-8527. Hex 2100-214F.
- Неправильная кодировка результатов из базы данных MySQL
- Мета тег nofollow
- What is meta charset?
UTF-8 Basic Latin
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| 32 | 0020 | SPACE | ||
| ! | 33 | 0021 | EXCLAMATION MARK | |
| « | 34 | 0022 | " | QUOTATION MARK |
| # | 35 | 0023 | NUMBER SIGN | |
| $ | 36 | 0024 | DOLLAR SIGN | |
| % | 37 | 0025 | PERCENT SIGN | |
| & | 38 | 0026 | & | AMPERSAND |
| ‘ | 39 | 0027 | APOSTROPHE | |
| ( | 40 | 0028 | LEFT PARENTHESIS | |
| ) | 41 | 0029 | RIGHT PARENTHESIS | |
| * | 42 | 002A | ASTERISK | |
| + | 43 | 002B | PLUS SIGN | |
| , | 44 | 002C | COMMA | |
| — | 45 | 002D | HYPHEN-MINUS | |
| . | 46 | 002E | FULL STOP | |
| 47 | 002F | SOLIDUS | ||
| 48 | 0030 | DIGIT ZERO | ||
| 1 | 49 | 0031 | DIGIT ONE | |
| 2 | 50 | 0032 | DIGIT TWO | |
| 3 | 51 | 0033 | DIGIT THREE | |
| 4 | 52 | 0034 | DIGIT FOUR | |
| 5 | 53 | 0035 | DIGIT FIVE | |
| 6 | 54 | 0036 | DIGIT SIX | |
| 7 | 55 | 0037 | DIGIT SEVEN | |
| 8 | 56 | 0038 | DIGIT EIGHT | |
| 9 | 57 | 0039 | DIGIT NINE | |
| 58 | 003A | COLON | ||
| ; | 59 | 003B | SEMICOLON | |
| < | 60 | 003C | < | LESS-THAN SIGN |
| = | 61 | 003D | EQUALS SIGN | |
| > | 62 | 003E | > | GREATER-THAN SIGN |
| ? | 63 | 003F | QUESTION MARK | |
| @ | 64 | 0040 | COMMERCIAL AT | |
| A | 65 | 0041 | LATIN CAPITAL LETTER A | |
| B | 66 | 0042 | LATIN CAPITAL LETTER B | |
| C | 67 | 0043 | LATIN CAPITAL LETTER C | |
| D | 68 | 0044 | LATIN CAPITAL LETTER D | |
| E | 69 | 0045 | LATIN CAPITAL LETTER E | |
| F | 70 | 0046 | LATIN CAPITAL LETTER F | |
| G | 71 | 0047 | LATIN CAPITAL LETTER G | |
| H | 72 | 0048 | LATIN CAPITAL LETTER H | |
| I | 73 | 0049 | LATIN CAPITAL LETTER I | |
| J | 74 | 004A | LATIN CAPITAL LETTER J | |
| K | 75 | 004B | LATIN CAPITAL LETTER K | |
| L | 76 | 004C | LATIN CAPITAL LETTER L | |
| M | 77 | 004D | LATIN CAPITAL LETTER M | |
| N | 78 | 004E | LATIN CAPITAL LETTER N | |
| O | 79 | 004F | LATIN CAPITAL LETTER O | |
| P | 80 | 0050 | LATIN CAPITAL LETTER P | |
| Q | 81 | 0051 | LATIN CAPITAL LETTER Q | |
| R | 82 | 0052 | LATIN CAPITAL LETTER R | |
| S | 83 | 0053 | LATIN CAPITAL LETTER S | |
| T | 84 | 0054 | LATIN CAPITAL LETTER T | |
| U | 85 | 0055 | LATIN CAPITAL LETTER U | |
| V | 86 | 0056 | LATIN CAPITAL LETTER V | |
| W | 87 | 0057 | LATIN CAPITAL LETTER W | |
| X | 88 | 0058 | LATIN CAPITAL LETTER X | |
| Y | 89 | 0059 | LATIN CAPITAL LETTER Y | |
| Z | 90 | 005A | LATIN CAPITAL LETTER Z | |
| 91 | 005B | LEFT SQUARE BRACKET | ||
| \ | 92 | 005C | REVERSE SOLIDUS | |
| 93 | 005D | RIGHT SQUARE BRACKET | ||
| ^ | 94 | 005E | CIRCUMFLEX ACCENT | |
| _ | 95 | 005F | LOW LINE | |
| ` | 96 | 0060 | GRAVE ACCENT | |
| a | 97 | 0061 | LATIN SMALL LETTER A | |
| b | 98 | 0062 | LATIN SMALL LETTER B | |
| c | 99 | 0063 | LATIN SMALL LETTER C | |
| d | 100 | 0064 | LATIN SMALL LETTER D | |
| e | 101 | 0065 | LATIN SMALL LETTER E | |
| f | 102 | 0066 | LATIN SMALL LETTER F | |
| g | 103 | 0067 | LATIN SMALL LETTER G | |
| h | 104 | 0068 | LATIN SMALL LETTER H | |
| i | 105 | 0069 | LATIN SMALL LETTER I | |
| j | 106 | 006A | LATIN SMALL LETTER J | |
| k | 107 | 006B | LATIN SMALL LETTER K | |
| l | 108 | 006C | LATIN SMALL LETTER L | |
| m | 109 | 006D | LATIN SMALL LETTER M | |
| n | 110 | 006E | LATIN SMALL LETTER N | |
| o | 111 | 006F | LATIN SMALL LETTER O | |
| p | 112 | 0070 | LATIN SMALL LETTER P | |
| q | 113 | 0071 | LATIN SMALL LETTER Q | |
| r | 114 | 0072 | LATIN SMALL LETTER R | |
| s | 115 | 0073 | LATIN SMALL LETTER S | |
| t | 116 | 0074 | LATIN SMALL LETTER T | |
| u | 117 | 0075 | LATIN SMALL LETTER U | |
| v | 118 | 0076 | LATIN SMALL LETTER V | |
| w | 119 | 0077 | LATIN SMALL LETTER W | |
| x | 120 | 0078 | LATIN SMALL LETTER X | |
| y | 121 | 0079 | LATIN SMALL LETTER Y | |
| z | 122 | 007A | LATIN SMALL LETTER Z | |
| { | 123 | 007B | LEFT CURLY BRACKET | |
| | | 124 | 007C | VERTICAL LINE | |
| } | 125 | 007D | RIGHT CURLY BRACKET | |
| ~ | 126 | 007E | TILDE |
Тег
Тег <title> является частью метаданных и используется для указания заголовка страницы. Заголовок страницы можно сравнить с названием главы книги, так как он должен говорить пользователям и поисковым системам об информации представленной на странице.
Заголовок должен содержать важные ключевые слова для того, чтобы поисковые системы могли включить вашу страницу в результаты поиска по определенным запросам. Также он может помочь пользователям решить, стоит ли посетить ваш сайт или нет, так как они будут видеть заголовок в качестве текста ссылки в результатах поиска:
Тег <title> является одним из наиболее важных тегов на странице. Рассмотрим небольшой список рекомендаций, которых нужно придерживаться для написания оптимизированного заголовка для поисковых систем:
- Длина заголовка не должна превышать 70 символов, включая пробелы.
- Самые важные ключевые слова нужно располагать первыми в заголовке, т.е. поисковые системы будут определять ценность ключевых слов по их очередности в заголовке: первое будет считаться наиболее важным, последнее — наименее.
- Для разделения ключевых слов или фраз лучше использовать вертикальную черту «|». Знаки пунктуации, подчеркивания и другие символы разделители желательно не использовать или использовать в тех случаях, когда ключевое слово или фразу без них написать нельзя.
- Старайтесь исключить из заголовка разные частицы речи (например: и, если, но, потом и т.д.).
- Можно включить в заголовок название сайта или фирмы, если название является частью ключей фразы, или если это бренд, видя который, пользователи будут заходить именно на ваш сайт.
- Не дублируйте текст тега <title>, заголовок должен быть уникальным для каждой страницы сайта.
- Заголовок должен быть актуален для страницы, он должен описывать то, что в данный момент представлено на странице, например его можно написать так:
<title>Тема страницы|Ключевые слова|Название компании или сайта</title> <!-- или так --> <title>Ключевые слова|О нас|Название компании или сайта</title>
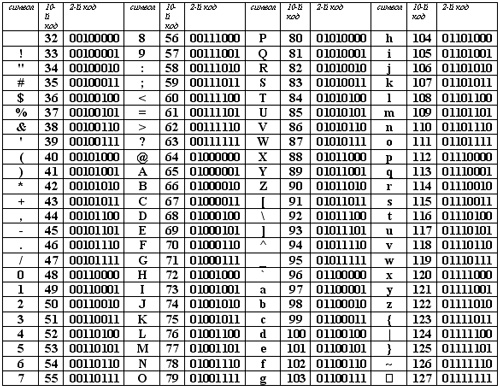
Range: Decimal 768-879. Hex 0300-036F.
If you want any of these characters displayed in HTML, you can use the HTML entity found in the table below.
If the character does not have an HTML entity, you can use the decimal (dec) or hexadecimal (hex) reference.
Will display as:
I will display a
I will display ̃
I will display ã
Older browsers may not support all the HTML5 entities in the table below.
Chrome and Opera have good support, and IE 11+ and Firefox 35+ support all the entities.
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| ò | 768 | 0300 | GRAVE ACCENT | |
| ó | 769 | 0301 | ACUTE ACCENT | |
| ô | 770 | 0302 | CIRCUMFLEX ACCENT | |
| õ | 771 | 0303 | TILDE | |
| ō | 772 | 0304 | MACRON | |
| o̅ | 773 | 0305 | OVERLINE | |
| ŏ | 774 | 0306 | BREVE | |
| ȯ | 775 | 0307 | DOT ABOVE | |
| ö | 776 | 0308 | DIAERESIS | |
| ỏ | 777 | 0309 | HOOK ABOVE | |
| o̊ | 778 | 030A | RING ABOVE | |
| ő | 779 | 030B | DOUBLE ACUTE ACCENT | |
| ǒ | 780 | 030C | CARON | |
| o̍ | 781 | 030D | VERTICAL LINE ABOVE | |
| o̎ | 782 | 030E | DOUBLE VERTICAL LINE ABOVE | |
| ȍ | 783 | 030F | DOUBLE GRAVE ACCENT | |
| o̐ | 784 | 0310 | CANDRABINDU | |
| ȏ | 785 | 0311 | INVERTED BREVE | |
| o̒ | 786 | 0312 | TURNED COMMA ABOVE | |
| o̓ | 787 | 0313 | COMMA ABOVE | |
| o̔ | 788 | 0314 | REVERSED COMMA ABOVE | |
| o̕ | 789 | 0315 | COMMA ABOVE RIGHT | |
| o̖ | 790 | 0316 | GRAVE ACCENT BELOW | |
| o̗ | 791 | 0317 | ACUTE ACCENT BELOW | |
| o̘ | 792 | 0318 | LEFT TACK BELOW | |
| o̙ | 793 | 0319 | RIGHT TACK BELOW | |
| o̚ | 794 | 031A | LEFT ANGLE ABOVE | |
| ơ | 795 | 031B | HORN | |
| o̜ | 796 | 031C | LEFT HALF RING BELOW | |
| o̝ | 797 | 031D | UP TACK BELOW | |
| o̞ | 798 | 031E | DOWN TACK BELOW | |
| o̟ | 799 | 031F | PLUS SIGN BELOW | |
| o̠ | 800 | 0320 | MINUS SIGN BELOW | |
| o̡ | 801 | 0321 | PALATALIZED HOOK BELOW | |
| o̢ | 802 | 0322 | RETROFLEX HOOK BELOW | |
| ọ | 803 | 0323 | DOT BELOW | |
| o̤ | 804 | 0324 | DIAERESIS BELOW | |
| o̥ | 805 | 0325 | RING BELOW | |
| o̦ | 806 | 0326 | COMMA BELOW | |
| o̧ | 807 | 0327 | CEDILLA | |
| ǫ | 808 | 0328 | OGONEK | |
| o̩ | 809 | 0329 | VERTICAL LINE BELOW | |
| o̪ | 810 | 032A | BRIDGE BELOW | |
| o̫ | 811 | 032B | INVERTED DOUBLE ARCH BELOW | |
| o̬ | 812 | 032C | CARON BELOW | |
| o̭ | 813 | 032D | CIRCUMFLEX ACCENT BELOW | |
| o̮ | 814 | 032E | BREVE BELOW | |
| o̯ | 815 | 032F | INVERTED BREVE BELOW | |
| o̰ | 816 | 0330 | TILDE BELOW | |
| o̱ | 817 | 0331 | MACRON BELOW | |
| o̲ | 818 | 0332 | LOW LINE | |
| o̳ | 819 | 0333 | DOUBLE LOW LINE | |
| o̴ | 820 | 0334 | TILDE OVERLAY | |
| o̵ | 821 | 0335 | SHORT STROKE OVERLAY | |
| o̶ | 822 | 0336 | LONG STROKE OVERLAY | |
| o̷ | 823 | 0337 | SHORT SOLIDUS OVERLAY | |
| o̸ | 824 | 0338 | LONG SOLIDUS OVERLAY | |
| o̹ | 825 | 0339 | RIGHT HALF RING BELOW | |
| o̺ | 826 | 033A | INVERTED BRIDGE BELOW | |
| o̻ | 827 | 033B | SQUARE BELOW | |
| o̼ | 828 | 033C | SEAGULL BELOW | |
| o̽ | 829 | 033D | X ABOVE | |
| o̾ | 830 | 033E | VERTICAL TILDE | |
| o̿ | 831 | 033F | DOUBLE OVERLINE | |
| ò | 832 | 0340 | GRAVE TONE MARK | |
| ó | 833 | 0341 | ACUTE TONE MARK | |
| o͂ | 834 | 0342 | GREEK PERISPOMENI (combined with theta) | |
| o̓ | 835 | 0343 | GREEK KORONIS (combined with theta) | |
| ö́ | 836 | 0344 | GREEK DIALYTIKA TONOS (combined with theta) | |
| oͅ | 837 | 0345 | GREEK YPOGEGRAMMENI (combined with theta) | |
| o͆ | 838 | 0346 | BRIDGE ABOVE | |
| o͇ | 839 | 0347 | EQUALS SIGN BELOW | |
| o͈ | 840 | 0348 | DOUBLE VERTICAL LINE BELOW | |
| o͉ | 841 | 0349 | LEFT ANGLE BELOW | |
| o͊ | 842 | 034A | NOT TILDE ABOVE | |
| o͋ | 843 | 034B | HOMOTHETIC ABOVE | |
| o͌ | 844 | 034C | ALMOST EQUAL TO ABOVE | |
| o͍ | 845 | 034D | LEFT RIGHT ARROW BELOW | |
| o͎ | 846 | 034E | UPWARDS ARROW BELOW | |
| o͏ | 847 | 034F | GRAPHEME JOINER | |
| o͐ | 848 | 0350 | RIGHT ARROWHEAD ABOVE | |
| o͑ | 849 | 0351 | LEFT HALF RING ABOVE | |
| o͒ | 850 | 0352 | FERMATA | |
| o͓ | 851 | 0353 | X BELOW | |
| o͔ | 852 | 0354 | LEFT ARROWHEAD BELOW | |
| o͕ | 853 | 0355 | RIGHT ARROWHEAD BELOW | |
| o͖ | 854 | 0356 | RIGHT ARROWHEAD AND UP ARROWHEAD BELOW | |
| o͗ | 855 | 0357 | RIGHT HALF RING ABOVE | |
| o͘ | 856 | 0358 | DOT ABOVE RIGHT | |
| o͙ | 857 | 0359 | ASTERISK BELOW | |
| o͚ | 858 | 035A | DOUBLE RING BELOW | |
| o͛ | 859 | 035B | ZIGZAG ABOVE | |
| ͜o | 860 | 035C | DOUBLE BREVE BELOW | |
| ͝o | 861 | 035D | DOUBLE BREVE | |
| ͞o | 862 | 035E | DOUBLE MACRON | |
| ͟o | 863 | 035F | DOUBLE MACRON BELOW | |
| ͠o | 864 | 0360 | DOUBLE TILDE | |
| ͡o | 865 | 0361 | DOUBLE INVERTED BREVE | |
| ͢o | 866 | 0362 | DOUBLE RIGHTWARDS ARROW BELOW | |
| oͣ | 867 | 0363 | LATIN SMALL LETTER A | |
| oͤ | 868 | 0364 | LATIN SMALL LETTER E | |
| oͥ | 869 | 0365 | LATIN SMALL LETTER I | |
| oͦ | 870 | 0366 | LATIN SMALL LETTER O | |
| oͧ | 871 | 0367 | LATIN SMALL LETTER U | |
| oͨ | 872 | 0368 | LATIN SMALL LETTER C | |
| oͩ | 873 | 0369 | LATIN SMALL LETTER D | |
| oͪ | 874 | 036A | LATIN SMALL LETTER H | |
| oͫ | 875 | 036B | LATIN SMALL LETTER M | |
| oͬ | 876 | 036C | LATIN SMALL LETTER R | |
| oͭ | 877 | 036D | LATIN SMALL LETTER T | |
| oͮ | 878 | 036E | LATIN SMALL LETTER V | |
| oͯ | 879 | 036F | LATIN SMALL LETTER X |
❮ Previous
Next ❯
keywords (ключевые слова)
У любого сайта есть набор ключевых слов и словосочетаний, по которым поисковые системы ищут нужные ресурсы в сети. Именно эти слова и должны составлять содержимое keywords.
Самый простой способ подобрать нужные ключевые слова для текущей страницы — это определить по каким словам вы сами стали бы искать материал, представленный на ней? Вот это и будут нужные ключевые слова. Пример:
<meta name="keywords" content="мета тег, meta, метаданные, keywords, description">
Ключевые слова указываются через запятую или пробел и могут быть написаны в любом регистре. Рекомендуется указывать не более 10-15 ключевых слов или словосочетаний.
В настоящее время поисковые системы стали более продвинутые и определяют категорию, к которой относится информация, по содержимому веб-страницы, а ключевые слова отошли на второй план или полностью игнорируются.
Резюме
- Кодировка — это соответствие между визуальными символами и числами.
- Кодировки необходимы, так как компьютеры созданы для работы с числами и не понимают текст.
- До 1990-х годов не существовало единой кодировки, это приводило к тому, что текст, написанный в одной кодировке, становится совершенно нечитаемым на других.
- Unicode — единый стандарт кодирования символов. Развитие интернета и необходимость обмена большим количеством текстовой информации приводило к тому, что сейчас все пользуются этим стандартом.
- UTF-8, UTF-16, UTF-32 и т.п. — это варианты кодировок, основанные на Unicode. Отличаются они тем, что по-разному хранят информацию.
- UTF-8 — самая популярная кодировка. Особенность её в том, что самые популярные символы кодируются 1-2 байтами, а редко встречающиеся занимают 3-4 байта. Это приводит к существенной экономии памяти, например, при работе с английским текстом.
Ильнар Шафигуллин
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Кодирование и декодирование
Кодирование— это процесс формирования определенного представления информации,переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.То есть любой символ, который мы видим или вводим, для компьютера в реальности — всего лишь набор битов (набор нулей и единиц). Именно эти биты и перегоняются от устройства к устройству. А чтобы показать результат этих перегонок человеку, компьютер преобразует с помощью таблицы (той самой кодировки) код символа в соответствующий внешний вид.
UTF-32LE в UTF-8
Схемой можете воспользоваться при кодировании и раскодировании.
Эта схема сделана так, чтобы вы видели какие биты куда попадают как при кодировании, так и раскодировании.
По ней видно что при этих обоих процессах просто нужные биты выставляются на нужные позиции при нужных значениях контрольных бит.
Можно заметить что компоновка в больших байтовых последовательностях осуществляется по 6 бит (в так называемых лидирующих байтах).
При этом старшие биты предусматриваемого кода будут в первых байтах (схоже с порядком Big-Endian).

Кодирование
Порядок действий такой:
- Каждый символ превращаем в Unicode.
- Проверяем из какого диапазона символ.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h40
b2 = (c - b1) &h40
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h40
b2 = ((c - b1) &h40) Mod &h40
b3 = (c - b1 - (&h40 * b2)) &h1000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < Then
ToLong = CLng(intVal) + &H10000
Else
ToLong = CLng(intVal)
End If
End Function
Декодирование
Декодирование — преобразование зашифрованной информации в понятный, пригодный для непосредственного использования вид.
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Unicode.
Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h3F
b2 = c and &h1F
c = b1 + b2 * &h40
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h3F
b2 = asc(mid(s,i+1,1)) and &h3F
b3 = c and &h0F
c = b3 * &H1000 + b2 * &H40 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
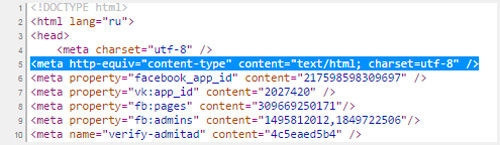
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей. Для этого необходимо вставить в тег head следующие данные
После символов «charset=» идет либо утф, либо виндовс, как в примере ниже
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"> |
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова «Создание и Раскрутка сайта от А до Я».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова. Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
How does it work?
Meta Charset is what determines how text is transmitted and stored. This text data is usually converted to binary first and then there needs to be a kind of cipher that connects characters with their correct binary equivalents.
When this data is eventually decoded, the character encoding must be known beforehand or there could be complications. An example of these can be seen in browsers when you’re looking at a webpage. Information about the kind of character set used comes from the server or is written directly by the developer. Unfortunately, there is a myriad of character sets and this means diverse ways of matching binary codes to characters and bytes.
For content developers and authors, choosing the UTF-8 character set for your content means that you can use a single character set to multiple characters needs thereby simplifying things greatly without the need to track and convert multiple times. This means it would be easier to surf through your content without getting confusing characters and garbage
Range: Decimal 8448-8527. Hex 2100-214F.
If you want any of these characters displayed in HTML, you can use the HTML
entity found in the table below.
If the character does not have an HTML entity, you can use the decimal (dec)
or hexadecimal (hex) reference.
Will display as:
I will display
I will display
I will display
Older browsers may not support all the HTML5 entities in the table below.
Chrome and Opera have good support, and IE 11+ and Firefox 35+ support all the entities.
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| ℀ | 8448 | 2100 | ACCOUNT OF | |
| ℁ | 8449 | 2101 | ADDRESSED TO THE SUBJECT | |
| ℂ | 8450 | 2102 | DOUBLE-STRUCK CAPITAL C | |
| ℃ | 8451 | 2103 | DEGREE CELSIUS | |
| ℄ | 8452 | 2104 | CENTRE LINE SYMBOL | |
| ℅ | 8453 | 2105 | CARE OF | |
| ℆ | 8454 | 2106 | CADA UNA | |
| ℇ | 8455 | 2107 | EULER CONSTANT | |
| ℈ | 8456 | 2108 | SCRUPLE | |
| ℉ | 8457 | 2109 | DEGREE FAHRENHEIT | |
| ℊ | 8458 | 210A | SCRIPT SMALL G | |
| ℋ | 8459 | 210B | SCRIPT CAPITAL H | |
| ℌ | 8460 | 210C | BLACK-LETTER CAPITAL H | |
| ℍ | 8461 | 210D | DOUBLE-STRUCK CAPITAL H | |
| ℎ | 8462 | 210E | PLANCK CONSTANT | |
| ℏ | 8463 | 210F | PLANCK CONSTANT OVER TWO PI | |
| ℐ | 8464 | 2110 | SCRIPT CAPITAL I | |
| ℑ | 8465 | 2111 | ℑ | BLACK-LETTER CAPITAL I |
| ℒ | 8466 | 2112 | SCRIPT CAPITAL L | |
| ℓ | 8467 | 2113 | SCRIPT SMALL L | |
| ℔ | 8468 | 2114 | L B BAR SYMBOL | |
| ℕ | 8469 | 2115 | DOUBLE-STRUCK CAPITAL N | |
| № | 8470 | 2116 | NUMERO SIGN | |
| ℗ | 8471 | 2117 | SOUND RECORDING COPYRIGHT | |
| ℘ | 8472 | 2118 | ℘ | SCRIPT CAPITAL P |
| ℙ | 8473 | 2119 | DOUBLE-STRUCK CAPITAL P | |
| ℚ | 8474 | 211A | DOUBLE-STRUCK CAPITAL Q | |
| ℛ | 8475 | 211B | SCRIPT CAPITAL R | |
| ℜ | 8476 | 211C | ℜ | BLACK-LETTER CAPITAL R |
| ℝ | 8477 | 211D | DOUBLE-STRUCK CAPITAL R | |
| ℞ | 8478 | 211E | PRESCRIPTION TAKE | |
| ℟ | 8479 | 211F | RESPONSE | |
| ℠ | 8480 | 2120 | SERVICE MARK | |
| ℡ | 8481 | 2121 | TELEPHONE SIGN | |
| 8482 | 2122 | ™ | TRADE MARK SIGN | |
| ℣ | 8483 | 2123 | VERSICLE | |
| ℤ | 8484 | 2124 | DOUBLE-STRUCK CAPITAL Z | |
| ℥ | 8485 | 2125 | OUNCE SIGN | |
| Ω | 8486 | 2126 | Ω | OHM SIGN |
| ℧ | 8487 | 2127 | ℧ | INVERTED OHM SIGN |
| ℨ | 8488 | 2128 | BLACK-LETTER CAPITAL Z | |
| ℩ | 8489 | 2129 | TURNED GREEK SMALL LETTER IOTA | |
| K | 8490 | 212A | KELVIN SIGN | |
| Å | 8491 | 212B | ANGSTROM SIGN | |
| ℬ | 8492 | 212C | SCRIPT CAPITAL B | |
| ℭ | 8493 | 212D | BLACK-LETTER CAPITAL C | |
| ℮ | 8494 | 212E | ESTIMATED SYMBOL | |
| ℯ | 8495 | 212F | SCRIPT SMALL E | |
| ℰ | 8496 | 2130 | SCRIPT CAPITAL E | |
| ℱ | 8497 | 2131 | SCRIPT CAPITAL F | |
| Ⅎ | 8498 | 2132 | TURNED CAPITAL F | |
| ℳ | 8499 | 2133 | SCRIPT CAPITAL M | |
| ℴ | 8500 | 2134 | SCRIPT SMALL O | |
| ℵ | 8501 | 2135 | ℵ | ALEF SYMBOL |
| ℶ | 8502 | 2136 | BET SYMBOL | |
| ℷ | 8503 | 2137 | GIMEL SYMBOL | |
| ℸ | 8504 | 2138 | DALET SYMBOL | |
| 8505 | 2139 | INFORMATION SOURCE | ||
| ℺ | 8506 | 213A | ROTATED CAPITAL Q | |
| ℻ | 8507 | 213B | FACSIMILE SIGN | |
| ℼ | 8508 | 213C | DOUBLE-STRUCK SMALL PI | |
| ℽ | 8509 | 213D | DOUBLE-STRUCK SMALL GAMMA | |
| ℾ | 8510 | 213E | DOUBLE-STRUCK CAPITAL GAMMA | |
| ℿ | 8511 | 213F | DOUBLE-STRUCK CAPITAL PI | |
| ⅀ | 8512 | 2140 | DOUBLE-STRUCK N-ARY SUMMATION | |
| ⅁ | 8513 | 2141 | TURNED SANS-SERIF CAPITAL G | |
| ⅂ | 8514 | 2142 | TURNED SANS-SERIF CAPITAL L | |
| ⅃ | 8515 | 2143 | REVERSED SANS-SERIF CAPITAL L | |
| ⅄ | 8516 | 2144 | TURNED SANS-SERIF CAPITAL Y | |
| ⅅ | 8517 | 2145 | DOUBLE-STRUCK ITALIC CAPITAL D | |
| ⅆ | 8518 | 2146 | DOUBLE-STRUCK ITALIC SMALL D | |
| ⅇ | 8519 | 2147 | DOUBLE-STRUCK ITALIC SMALL E | |
| ⅈ | 8520 | 2148 | DOUBLE-STRUCK ITALIC SMALL I | |
| ⅉ | 8521 | 2149 | DOUBLE-STRUCK ITALIC SMALL J | |
| ⅊ | 8522 | 214A | PROPERTY LINE | |
| ⅋ | 8523 | 214B | TURNED AMPERSAND | |
| ⅌ | 8524 | 214C | PER SIGN | |
| ⅍ | 8525 | 214D | AKTIESELSKAB | |
| ⅎ | 8526 | 214E | TURNED SMALL F | |
| ⅏ | 8527 | 214F | SYMBOL FOR SAMARITAN SOURCE |
❮ Previous
Next ❯
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename);
if ($this->mysqli->connect_error) {
$this->errorHandler_c->logError(1, 'Connect Error (' . $this->mysqli->connect_errno . ') ' . $this->mysqli->connect_error, $_SERVER );
}
$this->mysqli->query("SET NAMES UTF8");
$this->mysqli->query("SET CHARACTER SET UTF8");
$this->mysqli->query("SET character_set_client = UTF8");
$this->mysqli->query("SET character_set_connection = UTF8");
$this->mysqli->query("SET character_set_results = UTF8");
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
Мета тег nofollow
Внешние, исходящие ссылки – это ссылки вашего сайта, указывающие на другие веб-проекты. Они используются для перенаправления пользователей на проверенные источники информации или по какой-либо другой причине.
Эти ссылки имеют большое значение для SEO. Они могут сделать ваш контент похожим на, бережно созданный вручную, исчерпывающий материал по теме, подкреплённый надёжными источниками, или на, сгенерированную роботом, свалку ссылок.
Поисковые системы уже давно научились распознавать сайты без дополнительной ценности для пользователей, основной целью которых является продажа ссылок в биржах. Пингвин, Минусинск и другие типы санкций активно применяются поисковиками к сайтам вебмастеров за манипуляцию ссылочной массой.
С другой стороны, в эпоху семантического поиска, Google и Яндекс могут рассматривать источники, на которые вы ссылаетесь, как контекст, чтобы лучше понимать контент на страницах сайта.
По обеим этим причинам определённо стоит обращать внимание на то, где и как вы ставите ссылки. По умолчанию все ссылки являются открытыми для роботов поисковых систем
Их обычно называют dofollow-ссылками. Боты свободно переходят по таким ссылкам и сканируют всё, что находится «на том конце». То есть, ставя открытую ссылку на другой сайт, вы заочно выражаете ему доверие
По умолчанию все ссылки являются открытыми для роботов поисковых систем. Их обычно называют dofollow-ссылками. Боты свободно переходят по таким ссылкам и сканируют всё, что находится «на том конце». То есть, ставя открытую ссылку на другой сайт, вы заочно выражаете ему доверие.
Каждый специалист самостоятельно поддерживает SEO-гигиену на своём проекте, сохраняя здоровый баланс между nofollow и dofollow ссылками. Обычно мета тег nofollow устанавливают на следующие типы ссылок:
- Ссылки на любые ресурсы, которые по каким-либо причинам могут рассматриваться, как «ненадёжный контент».
- Любые платные или спонсорские ссылки (вы же не хотите, чтобы поисковые системы уличили вас в продаже ссылок).
- Ссылки из комментариев или другой пользовательский контент, который может подвергаться спаму, помимо вашего желания.
- Внутренние ссылки «Вход» или «Регистрация», так как это является пустой тратой краулингового бюджета.
What is meta charset?
A charset or character set in full is essentially a set of characters recognized by the computer the same way the calculator can identify numbers. Each of these characters is represented by a number known as code point and this creates a communication channel for encoding and decoding content.
A character set, therefore, contains characters that serve a specific or particular purpose. The computer stores the characters as one or more bytes. An example is the ASCII character set which represents all English characters and special control characters with numbers from 0-127.
However, most character sets only work for specific languages and recognize limited characters and this makes the coding and encoding difficult or impossible. In modern times, however, the Unicode is the most reliable and universally accepted character set due to its ability to translate codes and numbers easily.
You can see the meta charset in the header of your html code