Как открыть сохраненную копию сайта
Содержание:
- Как посмотреть удаленную страницу в веб-архиве
- Просмотр копии страницы в поисковиках
- Что такое кэш сайта?
- Что такое файлы cookie и кэш браузера?
- Сохранить как HTML-файл
- Что если сохраненной страницы нет?
- Как посмотреть кэшированную копию в Яндексе: основные способы
- Вариант 2: копии страниц в поисковых системах
- The Wayback Machine
- Скриншот
- Типы Кэширования Сайта
- Http заголовки для управления клиентским кэшированием
- Но что, если мой контент изменяется?
- Как найти страницу из кэша Гугла и Яндекса.
- Архивы веб-страниц, постоянные
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
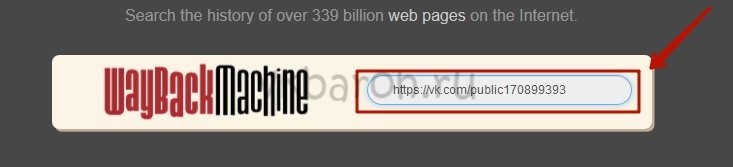
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.
Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.

Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.

Попытайте удачу в поисках архивной версии профиля на этих сайтах:
- archive.is;
- webcitation.org;
- freezepage.com;
- perma.cc.
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Просмотр копии страницы в поисковиках
Зная алгоритмы работы поисковых роботов, можно использовать их возможности в своих целях. Каждый созданный сайт, попадает в Яндекс и Гугл не сразу. Он размещается на специальном сервере и ждет, пока поисковик найдет его и добавит в свою базу. Такие обходы поисковые системы выполняют в среднем один раз в 14 дней. Во время этого процесса они не только добавляют в свою базу новые сайты, но удаляют неработающие. Это значит, что если страничка ВКонтакте была удалена совсем недавно, то возможно ее копия еще сохранилась на серверах поисковиков.
- Скопируйте адрес страницы, которую нужно найти, из адресной строки браузера.
- Вставьте эту ссылку в поисковую строку Яндекса или Гугла и нажмите «Поиск».
- Если страница все еще храниться в поисковике, то она будет первой в результатах выдачи. Справа от ссылки находится еле заметный треугольник. Нажмите на него.
- В открывшемся меню выберите «Сохранённая копия».
Перед вами откроется последняя версия страницы, которую сохранил Яндекс или Гугл. Сохраните фото, видео и всю прочую необходимую информацию себе на компьютер, так как совсем скоро сохраненная копия будет удалена с серверов поисковых машин.
Что такое кэш сайта?
Ответить на вопрос, что такое кэш сайта довольно просто. Это наиболее используемые элементы в работе: изображения, html-шаблонов, файлов js, css и т.д. Суть заключается в том, что с помощью сохраненной информации вэб-ресурс, программы, сервисы значительно ускоряются в работе.
Скорость обуславливается тем, что извлечение обработанных данных из кэша гораздо проще и занимает меньше времени, чем запрос из основного хранилища. Стоит отметить, что показатель CR сможет Вас порадовать, если решитесь на данную процедуру для своего сайта.
Существует четкая схема взаимодействия приложений с кэшом:
- Во время первого запроса все данные заносятся в кэш;
- При повторном запросе материалы берутся из кэша;
- Когда кэш пуст или его информация устарела, то алгоритм перезапускается;
- Настройки хранения находятся в файлах конфигурации вэб-ресурсов и самого сервера.
Данный термин очень универсален и встретить его можно в различных сферах жизнедеятельности. Например, в мобильных дэкстопных приложениях, аппаратном обеспечении и т.д. Даже на сайтах, посвященных тому, что такое сторителлинг можно увидеть успешное использование кэширования.
Кеш вашего браузера — это место на вашем компьютере, где хранится кэшированный веб-контент (или кеш).
Ваш веб-браузер хранит полные или частичные копии страниц, которые вы недавно просматривали, вместе с мультимедиа (изображения, аудио и видео) в файле на вашем компьютере, который называется кешем. Кэшированные файлы являются временными файлами, которые помогают интернет-страницам загружаться быстрее. Вот почему, когда вы очищаете кеш браузера, вы часто видите, что сайты загружаются медленнее, чем обычно.
Файлы cookie — это файлы, которые содержат небольшие фрагменты данных, связанных с посещаемыми вами веб-страницами. Они хранятся на вашем компьютере, пока вы используете браузер. Их основная цель — отслеживать вашу онлайн-активность.
Cookies записывают информацию, такую как ваше последнее посещение веб-сайта или ваши данные для входа. По этой причине вам часто приходится заходить на каждый сайт заново после удаления файлов cookie.
Сохранить как HTML-файл
Вот как сохранить страницу ресурса глобальной сети на компьютер в формате html. Впоследствии его можно будет конвертировать в другой тип. При таком копировании картинки с веб-портала помещаются в отдельную папку, которая будет иметь то же название, что html-файл, и находится в том же месте, что и он.
- Откройте сайт.
- Кликните правой кнопкой мышки в любом месте, свободном от рисунков, фонов, видео и анимации.
- Выберите «Сохранить как». В Mozilla Firefox аналогичную кнопку можно найти в меню. Для этого нужно нажать на значок с тремя горизонтальными чёрточками. В Opera эти настройки вызываются кликом на логотип.
- Задайте имя. Укажите путь.
- Подтвердите действие.
Что если сохраненной страницы нет?
Иногда в выдаче при нажатии на зеленую стрелку отсутствует пункт «Сохраненная копия». Этому может быть несколько причин:
- Иногда некоторые браузеры, в которых установлены плагины для блокировки рекламы, могут не отображать эту ссылку. Стоит попробовать приостановить плагин или удалить его и просмотреть сайт снова;
- Яндекс вообще не гарантирует попадание страницы сайта в сохраненные копии. То есть если ресурса нет, значит по какой-то причине поисковик решил не делать резервной копии. Ничего страшного, стоит проверить, не сохранила ли страницы сайта другая поисковая система — например, Google;
- Сайт отказал поисковым роботам в индексации своих страниц. Файл robots.txt, который может лежать в корне сайта, содержит инструкции для поисковых роботов, каким образом они должны сканировать его. Например, он может содержать требование не сканировать сайт совсем или сканировать только отдельные его страницы;
- Схожая с предыдущим пунктом причина. В html коде веб-ресурса может быть указан мета-тег Robots с атрибутом noarchive. Эта директива запрещает поисковому роботу делать копию сохраненной страницы.

Как посмотреть кэшированную копию в Яндексе: основные способы
Перед тем как открыть сохраненную копию сайта в Яндексе, выберите удобный способ — с помощью сервисов (Page Promoter в Firefox или RDS bar в Google Chrome) или вручную. Плагины — это удобно, но они могут давать сбой, поэтому стоит освоить и ручной метод просмотра.
Способ № 1 — плагины
Расширения для браузеров, плагины и различные онлайн-сервисы позволяют быстро открывать кэш сайтов. Один из самых популярных на сегодня сервисов — это RDS bar. Плагин отличается интуитивным пользовательским интерфейсом и позволяет посмотреть последние изменения страницы, отсканированной роботами. Но если нужная страница еще не проиндексировалась, то и плагин ничего не покажет. 
Способ № 2 — вручную
Самый простой и эффективный «механический» способ просмотра. Что нужно сделать:
- Найти в поисковике нужную страницу — по запросу или вбив в поисковую строку адрес сайта.
- В результате поиска в сниппете нажать на маленькую стрелочку.
- В выпавшем окошке нажать «Сохраненная копия».
- Нажать и посетить сайт с данными, сохраненными с последнего визита робота на страницу.
Вариант 2: копии страниц в поисковых системах
Я уже как-то отмечал , что пользователям поисковых систем нет смысла заходить на сайты, ведь можно просматривать копии их страниц в самой поисковой системе. Так или иначе, но это хороший способ просмотреть удалённую страницу.
, Вы можете использовать оператор поискового запроса info: , с указанием нужного URL-адреса, например:
В случае с поисковой системой Яндекс
, Вы можете использовать оператор поискового запроса url: , с указанием нужного URL-адреса, например:
Здесь нам нужно навести курсор мыши на (зелёный)
URL-адресс в сниппете, а потом кликнуть появившуюся ссылку «копия
» и мы получим последнюю сохранённую в Яндекс версию удалённой страницы.
Проблема в том, что поисковые системы хранят только последние проиндексированные копии страниц. В том случае если страница была удалена, со временем она может стать недоступной и в кэше поисковых систем.
The Wayback Machine
В 1996 году Брюстер Кейл открыл некоммерческую организацию, которую сейчас называют архивом Интернета. Компания занимается сбором копий веб-страниц, видеоматериалов, графических изображений, аудиозаписей, программного обспечения. Собранный материал архивируется, а бесплатный доступ к нему может получить любой желающий.
Главная цель The Wayback Machine — сохранение культурных ценностей, созданных цивилизацией после широкого распространения Интернета, создание наиболее полной электронной библиотеки человечества. В настоящий момент в Архиве хранится более 10 петабайт данных, что позволяет пользователям ознакомиться с 85 миллиардами веб-страниц. Это значит, Архив — наиболее полный кэш сайтов.
Archive.org — сайт организации, на нем можно попытаться найти снимок необходимой страницы. Так как сохраняется не только последняя копия, а бот просматривает ресурсы периодически, можно изучить все изменения, сделанные на определенной странице с течением времени, даже если сайт уже не существует. В строке поиска желательно использовать префикс WWW.
Скриншот
Снимок экрана — это самый простой способ добавить какую-то информацию на компьютер. Она сохраняется в виде графического файла. Его можно открыть и просмотреть в любое время. Вот как сделать скрин:
- Зайдите на нужный портал.
- Нажмите на клавиатуре кнопку PrintScreen (иногда она называется «PrntScr» или «PrtSc»). Снимок экрана будет добавлен в буфер обмена — временное хранилище, используемое при операциях «Копировать-Вставить».
- Откройте любой графический редактор. В операционной системе Windows есть свой — называется «Paint». Можете воспользоваться им. В нём можно обрезать и немного подкорректировать скриншот. Для более серьёзного редактирования графики надо устанавливать на компьютер профессиональные программы (Adobe Photoshop, к примеру). Но чтобы просто сделать копию страницы, хватит и собственных средств Windows.
- Вставьте скрин в редактор. Для этого нажмите Ctrl+V.
- Можно добавить его и в текстовый процессор (тот же Word), который поддерживает работу с графикой.
Получить снимок страницы можно с помощью графических редакторов. Например, Paint.
Информация будет представлена в виде сплошной картинки, а не набора символов. Если понадобится скопировать какую-то часть материала, придётся перепечатывать его вручную. Ведь скриншот — не статья. Чтобы облегчить задачу, воспользуйтесь утилитами для распознавания текста с рисунков.
Так удобно копировать небольшие куски. Но вот с объёмным контентом сложнее. Придётся делать много снимков, прокручивать, часто открывать редактор. Но можно разобраться, как сделать скрин всей страницы портала, а не её части. Используйте специализированные программы.
Утилиты для создания скриншотов
Существуют программы для работы со снимками экрана. С их помощью можно охватить контент полностью, а не скринить по кускам.
- Популярное приложение с разнообразным функционалом.
- Расширение для веб-браузера. Можно сделать картинку всей страницы, просто нажав кнопку на панели инструментов.
- Снимает всё, что можно снять: произвольные области, окна, большие веб-ресурсы. Есть инструментарий для редактирования получившихся изображений и библиотека эффектов.
- Автоматически прокручивает, делает серию кадров и самостоятельно объединяет их в один скриншот.
Есть также онлайн-сервисы, которые могут сформировать снимок. Они работают по одному принципу: вставить адрес сайта — получить картинку. Вот некоторые из них.
- Capture Full Page
- Web Screenshots
- Thumbalizr
- Snapito
Типы Кэширования Сайта
Существует два типа кэширования — кэширование на стороне сервера и на стороне браузера.
Кэширование на стороне браузера происходит, когда вы пытаетесь загрузить один и тот же сайт дважды. Сначала браузер собирает данные для загрузки страницы, после чего становится их временным хранилищем.
Кэширование на стороне сервера аналогично кешированию на стороне браузера. Разница в том, что временным хранилищем становится сервер. Ещё одно отличие этого типа кэширования — сервер может хранить больше данных, чем браузер.
Существуют различные системы серверного кэширования, а именно кэширование страниц, кэширование объектов и фрагментарное кэширование.
Проще говоря, при кэшировании страниц сохраняется вся веб-страница. Это полезно для сайтов с большим потоком трафика.
Кэширование объектов используется для хранения части сайта, которая существует в разных местах.
Фрагментарное кэширование похоже на кэширование объектов, за исключением того, что оно предназначено для определённых частей сайта, таких как виджеты и расширения.
Http заголовки для управления клиентским кэшированием
Для начала давайте посмотрим, как сервер и браузер взаимодействуют при отсутствии какого-либо кэширования. Для наглядного понимания я попытался представить и визуализировать процесс общения между ними в виде текстового чата. Представьте на несколько минут, что сервер и браузер – это люди, которые переписываются друг с другом 🙂
Без кэша (при отсутствии кэширующих http-заголовков)
Как мы видим, каждый раз при отображении картинки cat.png браузер будет снова загружать ее с сервера. Думаю, не нужно объяснять, что это медленно и неэффективно.
Заголовок ответа и заголовок запроса .
Идея заключается в том, что сервер добавляет заголовок к файлу (ответу), который он отдает браузеру.
Теперь браузер знает, что файл был создан (или изменен) 1 декабря 2014. В следующий раз, когда браузеру понадобится тот же файл, он отправит запрос с заголовком .
Если файл не изменялся, сервер отправляет браузеру пустой ответ со статусом . В этом случае, браузер знает, что файл не обновлялся и может отобразить копию, которую он сохранил в прошлый раз.
Таким образом, используя мы экономим на загрузке большого файла, отделываясь пустым быстрым ответом от сервера.
Заголовок ответа и заголовок запроса .
Принцип работы очень схож с , но, в отличии от него, не привязан ко времени. Время – вещь относительная.
Идея заключается в том, что при создании и каждом изменении сервер помечает файл особой меткой, называемой , а также добавляет заголовок к файлу (ответу), который он отдает браузеру:
Теперь браузер знает, что файл актуальной версии имеет равный “686897696a7c876b7e”. В следующий раз, когда брузеру понадобится тот же файл, он отправит запрос с заголовком .
Сервер может сравнить метки и, в случае, если файл не изменялся, отправить браузеру пустой ответ со статусом . Как и в случае с браузер выяснит, что файл не обновлялся и сможет отобразить копию из кэша.
Заголовок
Принцип работы этого заголовка отличается от вышеописанных и . При помощи определяется “срок годности” (“срок акуальности”) файла. Т.е. при первой загрузке сервер дает браузеру знать, что он не планирует изменять файл до наступления даты, указанной в :
В следующий раз браузер, зная, что “дата истечения срока годности” еще не наступила, даже не будет пытаться делать запрос к серверу и отобразит файл из кэша.
Такой вид кэша особенно актуален для иллюстраций к статьям, иконкам, фавиконкам, некоторых css и js файлов и тп.
Заголовок с директивой .
Принцип работы очень схож с . Здесь тоже определяется “срок годности” файла, но он задается в секундах и не привязан к конкретному времени, что намного удобнее в большинстве случаев.
Для справки:
- 1 день = 86400 секунд
- 1 неделя = 604800 секунд
- 1 месяц = 2629000 секунд
- 1 год = 31536000 секунд
К примеру:
У заголовка , кроме , есть и другие директивы. Давайте коротко рассмотрим наиболее популярные:
public
Дело в том, что кэшировать запросы может не только конечный клиент пользователя (браузер), но и различные промежуточные прокси, CDN-сети и тп. Так вот, директива позволяет абсолютно любым прокси-серверам осуществлять кэширование наравне с браузером.
private
Директива говорит о том, что данный файл (ответ сервера) является специфическим для конечного пользователя и не должен кэшироваться различными промежуточными прокси. При этом она разрешает кэширование конечному клиенту (браузеру пользователя). К примеру, это актуально для внутренних страниц профиля пользователя, запросов внутри сессии и т.п.
no-cache
Позволяет указать, что клиент должен делать запрос на сервер каждый раз. Иногда используется с заголовком , описанным выше.
no-store
Указывает клиенту, что он не должен сохранять копию запроса или частей запроса при любых условиях. Это самый строгий заголовок, отменяющий любые кэши. Он был придуман специально для работы с конфиденциальной информацией.
must-revalidate
Эта директива предписывает браузеру делать обязательный запрос на сервер для ре-валидации контента (например, если вы используете eTag). Дело в том, что http в определенной конфигурации позволяет кэшу хранить контент, который уже устарел. обязывает браузер при любых условиях делать проверку свежести контента путем запроса к серверу.
proxy-revalidate
Это то же, что и , но касается только кэширующих прокси серверов.
s-maxage
Практически не отличается от , за исключением того, что эта директива учитывается только кэшем резличных прокси, но не самим браузером пользователя. Буква “s-” исходит из слова “shared” (например, CDN). Эта директива предназначена специально для CDN-ов и других посреднических кэшей. Ее указание отменяет значения директивы и заголовка . Впрочем, если вы не строите CDN-сети, то вам вряд ли когда-либо понадобится.
Но что, если мой контент изменяется?
Это звучит здорово, но что, если вы включили кэширование, а затем опубликуете новую запись? Не будет ли она находиться вне кэша и не окажется ли невидимой для посетителей? Правильно настроенные системы кэширования прекрасно справляются с такими сценариями.
Система кэширования состоит не только из механизма хранения подготовленных HTML-файлов, но и механизма очистки кэша, когда выполняются определенные условия. Например, происходит публикация нового контента.
Настроенный WordPress, должен очистить интернет кэш главной страницы и страниц архивов, когда будет опубликована хотя бы одна новая запись. При этом он должен оставить все остальные страницы, поскольку они не изменены.
Как найти страницу из кэша Гугла и Яндекса.
Для начала давайте рассмотрим как искать в поисковой системе Google.
Способ №1.
Прописываем название страницы, сайта в поисковую строку, нажимаем “Enter” и видим , где отображается страница которую вы искали. Смотрим на сниппет и там де УРЛ (адрес) с права от него есть не большая стрелочка вниз, нажимаем на нее и у нас появляется пункт “Сохранённая копия”. Нажимаем на него и нас перекинет на копию страницу от определенного числа.
Способ №2.
Способ можно назвать полуавтоматическим, так как необходимо скопировать адрес, что находится ниже и вместо site.ru подставить домен своего сайта. В результате Вы получите туже самую копию страницы.
Способ №3.
Можно просматривать кэш с помощью плагинов для браузеров или онлайн сервисов. Я использую для этих целей .
Здесь можно посмотреть когда последний раз заходил робот на ресурс, соответственно и копия страницы будет за это число.
Теперь рассмотрим как искать кэш в поисковой системе Яндекс.
Способ №1.
Прописываем название страницы, сайта в поисковую строку, нажимаем “Enter” и видим поисковую выдачу, где отображается страница которую вы искали. Смотрим на сниппет и там де УРЛ (адрес) с права от него есть не большая стрелочка вниз, нажимаем на нее и у нас появляется пункт “Сохранённая копия”. Нажимаем на него и нас перекинет на копию страницу от определенного числа.
Способ №2.
Используем дополнительные плагины для браузеров. Читайте немного выше всё так же как и для Google.
Если страница не находится в , то большая вероятность того, что ее нету и в кэше. Если страница была ранее в индексе, то возможно она сохранилась в нем.
Архивы веб-страниц, постоянные
Если вы хотите сохранять текстовый контент, то для этих целей рекомендуются Pocket и Instapaper. Вы можете сохранять страницы через электронную почту, расширения для браузеров или через приложения. Эти сервисы извлекают текстовый контент из веб-страниц и делают его доступным на всех ваших устройствах. Но вы не можете загрузить сохраненные статьи, а только прочитать их на сайте Pocket или через мобильное приложение сервиса. Дальше мы расскажем, как полностью скопировать страницу сайта.
Evernote и OneNote — это инструменты для архивирования контента в подборки. Они предоставляют в распоряжение пользователей веб-клипперы (или расширения), которые позволяют легко сохранять полные веб-страницы в один клик.
Захваченные веб-страницы могут быть доступны с любого устройства, сохраняется оригинальный дизайн и возможность поиска по странице. Эти сервисы могут даже выполнять оптическое распознавание, чтобы найти текст на фотографиях. Evernote также позволяет экспортировать сохраненные страницы как HTML-файлы, которые можно загрузить в другом месте.
Если нужен быстрый и простой доступ к веб-страницам, то сохраняйте их в виде PDF-файлов. Перед тем, как скопировать страницу сайта в виде картинки, выберите правильный инструмент.
Google Chrome имеет встроенный PDF-конвертер. Также можно использовать Google Cloud Print. На сервис добавлен новый виртуальный принтер «Сохранить в Google Drive«. В следующий раз, когда вы будете печатать страницу на компьютере или мобильном устройстве через Cloud Print, вы сможете сохранить ее PDF-копию в Google Drive. Но это не лучший вариант сохранения страниц со сложным форматированием.
Когда важно сохранить дизайн, то лучше всего использовать скриншотер. Выбор подобных программ довольно велик, но я бы рекомендовал официальное дополнение Chrome от
Оно не только захватывает полные скриншоты веб-страниц, но также загружает полученное изображение на Google Drive. Дополнение может сохранять веб-страницы в формате веб-архива (MHT), который поддерживается в IE и Firefox.
Wayback Machine на Internet Archive — это идеальное место для поиска предыдущих версий веб-страницы. Но этот же инструмент можно использовать, чтобы скопировать страницу сайта и сохранить ее. Перейдите на archive.org/web и введите URL-адрес любой веб-страницы. Архиватор скачает на сервер ее полную копию, включая все изображения. Сервис создаст постоянный архив страницы, который выглядит так же, как оригинал. Он останется на сервере, даже если исходная страница была переведена в автономный режим.
Internet Archive не предоставляет возможности загрузки сохраненных страниц, но для этого можно использовать Archive.Is. Этот сервис очень похож на archive.org в том, что вы вводите URL-адрес страницы, и он создает на своем сервере точный ее снимок. Страница будет сохранена навсегда, но здесь есть возможность загрузить сохраненную страницу в виде ZIP-архива. Сервис также позволяет создавать архивы по дате. Благодаря чему вы можете получить несколько снимков одной и той же страницы для разных дат.
Все популярные браузеры предоставляют возможность загрузить полную версию веб-страницы на компьютер. Они загружают на ПК HTML страницы, а также связанные с ней изображения, CSS и JavaScript. Поэтому вы сможете прочитать ее позже в автономном режиме.
Теперь разберемся, как полностью скопировать страницу сайта на электронную читалку. Владельцы eReader могут использовать dotEPUB, чтобы загрузить любую веб-страницу в формате EPUB или MOBI. Данные форматы совместимы с большинством моделей электронных книг. Amazon также предлагает дополнение, с помощью которого можно сохранить любую веб-страницу на своем Kindle-устройстве, но этот инструмент в основном предназначен для архивирования текстового контента.
Большинство перечисленных инструментов позволяют загружать одну страницу, но если вы хотите сохранить набор URL-адресов, решением может стать Wget. Также существует Google Script для автоматической загрузки веб-страниц в Google Drive, но таким образом можно сохранить только HTML-контент.