Archive.org
Содержание:
- Что такое веб-архив и зачем он нужен?
- Зачем нужна информация об истории сайта в прошлом
- Переделка сайта
- Зачем проверять историю?
- Смотрим, как выглядела страница раньше
- Первый сайт в зоне .ru
- Использование сервиса WebArchive
- r-tools.org
- Кэш браузера
- Где взять уникальный контент для сателлитов?
- Сеть тематических сайтов
- Поисковые системы
- Альтернативы сохраненной копии Яндекса
- Утилиты для сохранения сайтов целиком
- Качаем сайт с web-arhive.ru
- Создание задачи
- Что такое исходящие ссылки
- Зачем был придуман первый веб-сайт
- Инструкция по получению уникальных статей с вебархива
Что такое веб-архив и зачем он нужен?
 Веб-архив — история миллионов сайтов
Веб-архив — история миллионов сайтов
Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
- Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
- Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
- Нужно восстановить сайт, когда нет его бэкапа.
- Нужно проанализировать конкурентов. Этот способ понадобится чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие “фишки” стоит позаимствовать.
- Необходимо посмотреть страницу, если она теперь недоступна напрямую.
- Интересно , как выглядел ресурс 10-20 лет назад.
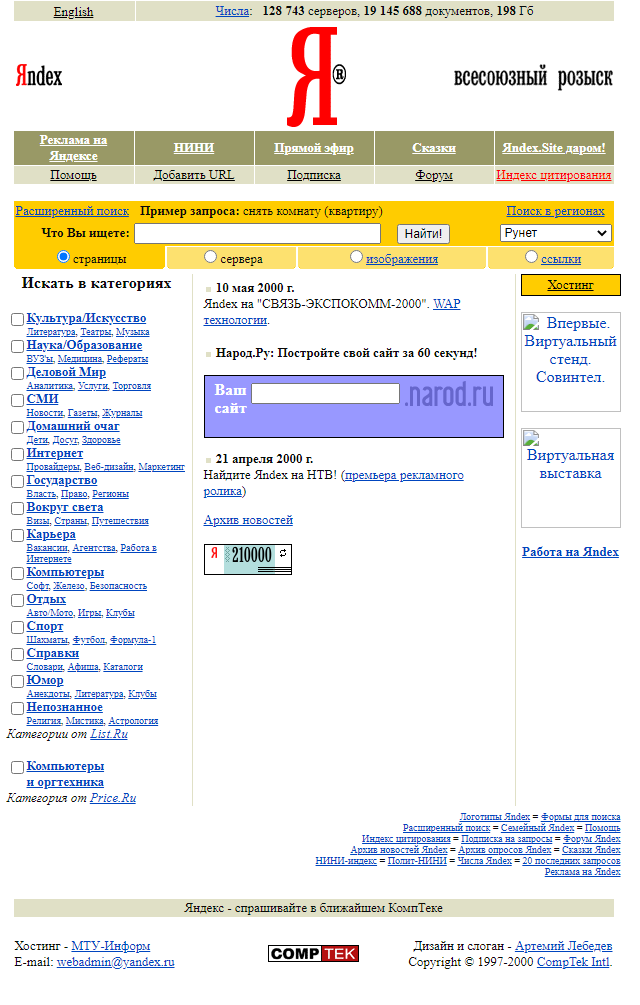
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
Переделка сайта
 Сегодня закончена очередная, небольшая переделка сайта для улучшения его показателей. Что-то сразу было сделано не так, что-то нужно сделать в связи с произошедшими изменениями в Интернете. Опыт показывает, периодические переделки сайтов вполне нормальное явление, хотя есть и минусы.
Сегодня закончена очередная, небольшая переделка сайта для улучшения его показателей. Что-то сразу было сделано не так, что-то нужно сделать в связи с произошедшими изменениями в Интернете. Опыт показывает, периодические переделки сайтов вполне нормальное явление, хотя есть и минусы.
Итак, мой блог был создан в начале 2013 года. Несмотря на наличие уроков, мной было допущено достаточно много различных ошибок, которые не позволяли блогу нормально развиваться. Приходилось учиться, вникать и понимать, какие вопросы должны быть обязательно сделаны. Кроме того в Интернете многое меняется и то, что работало еще год назад, сегодня может уже не работать. Теперь интересно сравнить новый и старый блог. Мы это обязательно сделаем, когда будем рассматривать вопрос, как посмотреть историю сайта.
В январе 2016 года, был полностью заменен шаблон моего блога, он был выполнен специалистами по дизайну и верстке. Старый шаблон поднадоел, да и был он серийным, не у меня одного был установлен такой шаблон. В процессе переделки блога, возникало много мелких вопросов, которые устранялись по ходу. В результате полученного опыта на блоге была опубликована статья «Как и где заказывать сайт». Думаю, статья многим помогла не наступать на грабли.
За прошедший год выявились небольшие недочеты, выявились резервы. По этой причине снова сделана его небольшая переделка. В футер перенесен виджет моей группы Вконтакте, дополнительно установлен виджет моей группы на Facebook, а также установлен виджет от Google+. Всё лишнее из футера удалено. Можете перейти в футер и посмотреть сами.
В последнее время были проблемы на хостинге из-за превышения нагрузки на CPU ядро. Естественно, нужно было решить часть вопросов. По рекомендации специалиста, который делал мне верстку блога и делал его переделку, установлен плагин WP Smush.
Плагин WP Smush ужимает все изображения, которые есть в статьях, это уменьшает время загрузки сайта. Оптимизирована и работа слайдера. Позже нужно будет с ним поработать еще. Убраны внешние ссылки, которые получались от привязки к JustClick. Любая переделка отрицательно влияет на позиции блога. В результате статьи, которые были в Топ 1-5, провалились и теперь они находятся на позициях 20-40. Сколько времени потребуется на их возврат в исходное состояние неизвестно. Вот такой получился краткий отчет о модернизации моего блога.
Если Вы тоже хотите сделать редизайн своего ресурса, блога, хотите сделать новый дизайн или оформить группу с оригинальным дизайном в соцсетях, могу рекомендовать Вам сайт Юлии — профессионала дизайнерского мастерства. Можно сделать, как обычный дизайн, строгий, графический, так и мультяшный.
Зачем проверять историю?
Если вы новичок и не знакомы с тем, что такое фильтры поисковых систем, репутация домена, индексация и ранжирование сайта, то давайте вкратце объясню простыми словами.
В интернете и в любой поисковой системе существует масса алгоритмов, анализирующих каждый ресурс по многим показателям. За время работы сайта он проходит тысячи проверок. Так как на сами данные ресурса не наложить никакие показатели, из-за того, что они постоянно меняются, все параметры проверок закрепляются за его адресом, то есть доменом.
В случае если на сайте долгое время находился неуникальный контент, вирусы, запрещающие материалы (для взрослых, экстремизм, пропаганда наркотиков и другое), покупались или продавались некачественные ссылки, публиковались переоптимизированные статьи, спам и т. д., то скорее всего доменное имя такого сайта находится под фильтрами и заблокировано.
Поэтому, когда вы покупаете подобный домен с плохой историей, будьте готовы, что возникнут проблемы с индексацией и продвижением. Такую ситуацию в онлайне можно сравнить с тюремным заключением, статус “ранее судимый” на имени останется надолго, возможно даже, навсегда, и будет мешать в развитии.
Узнать про все фильтры и блокировки нереально, можно лишь догадываться, анализируя данные, сохранившиеся в истории на некоторых специальных сервисах. Разберём подробно как ими пользоваться.
Смотрим, как выглядела страница раньше
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
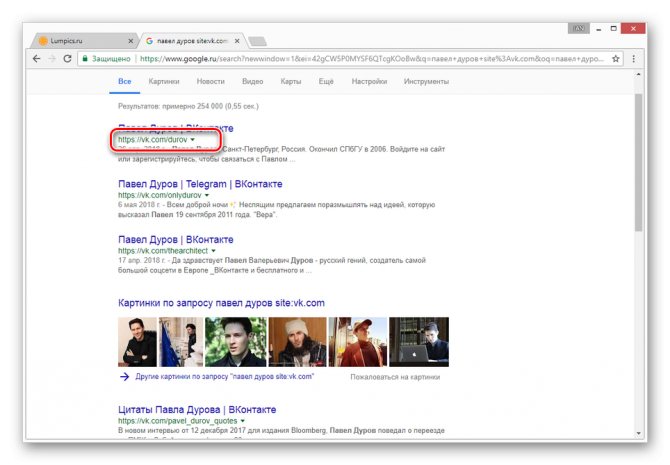
Из раскрывшегося списка выберите пункт «Сохраненная копия».
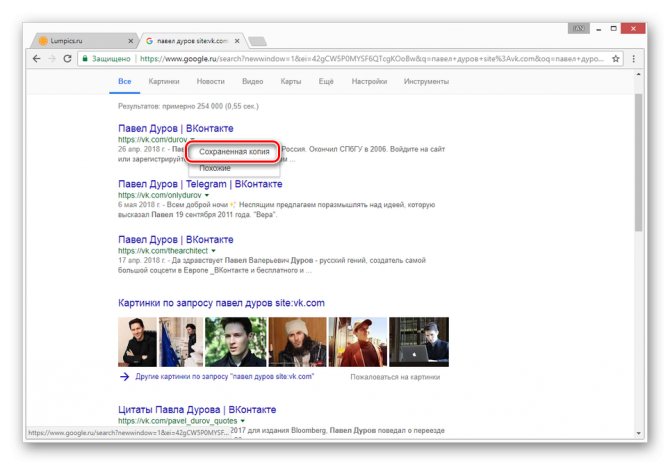
После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
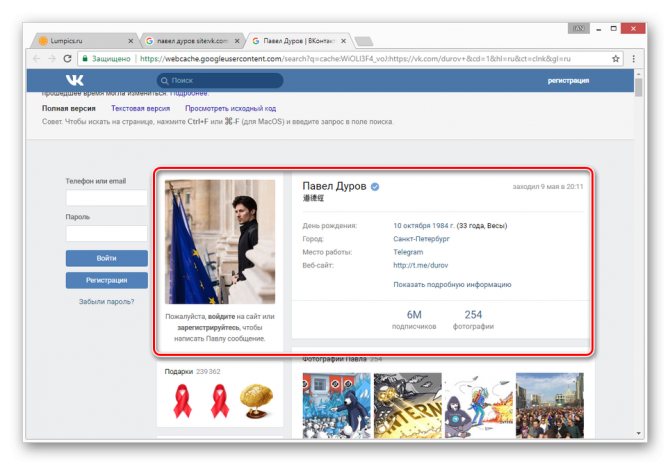
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
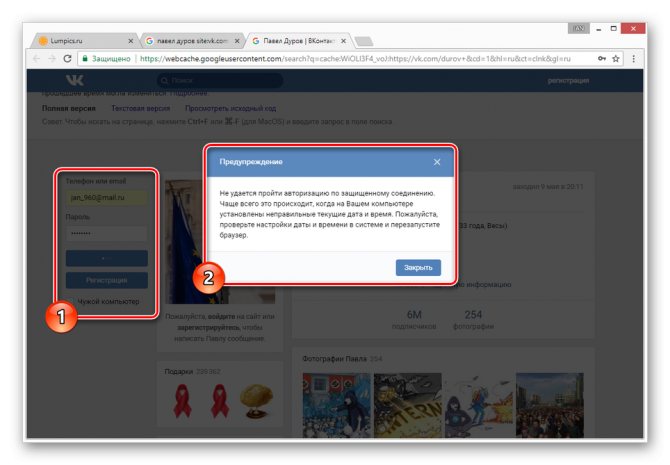
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
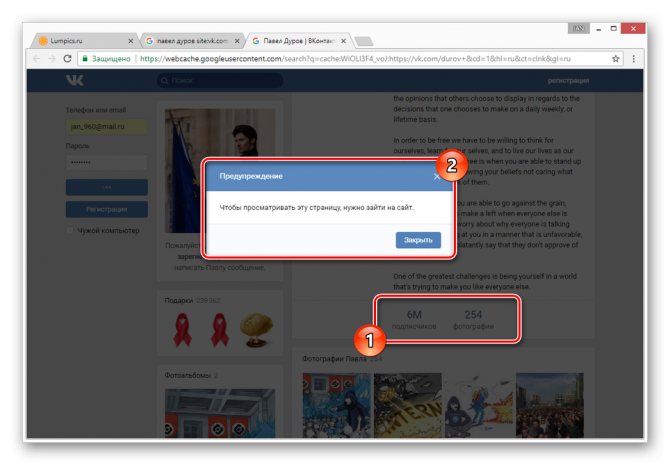
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
- После открытия ресурса по представленной выше ссылке в основное текстовое поле вставьте полный URL-адрес страницы, копию которой вам необходимо посмотреть.
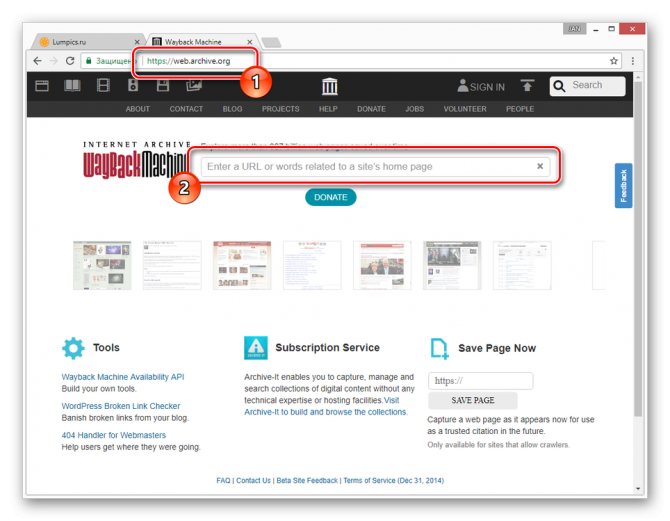
В случае успешного поиска вам будет представлена временная шкала со всеми сохраненными копиями в хронологическом порядке.
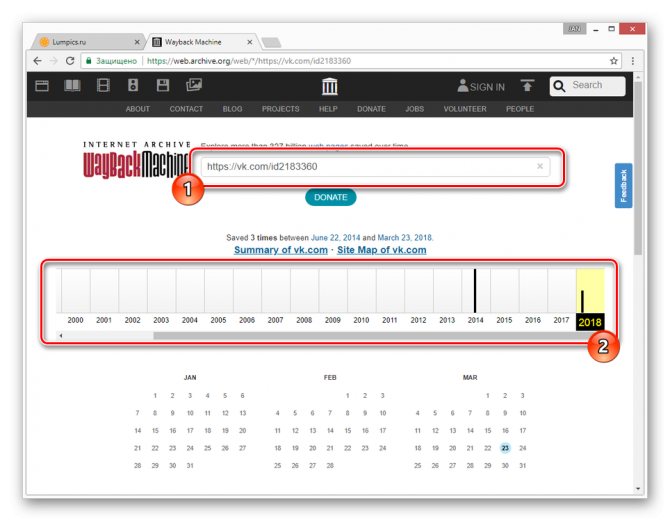
Переключитесь к нужной временной зоне, кликнув по соответствующему году.
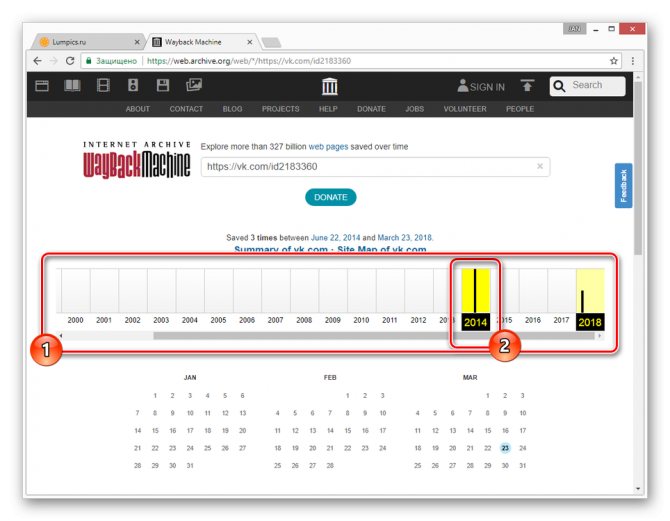
С помощью календаря найдите интересующую вас дату и наведите на нее курсор мыши. При этом кликабельными являются только подсвеченные определенным цветом числа.
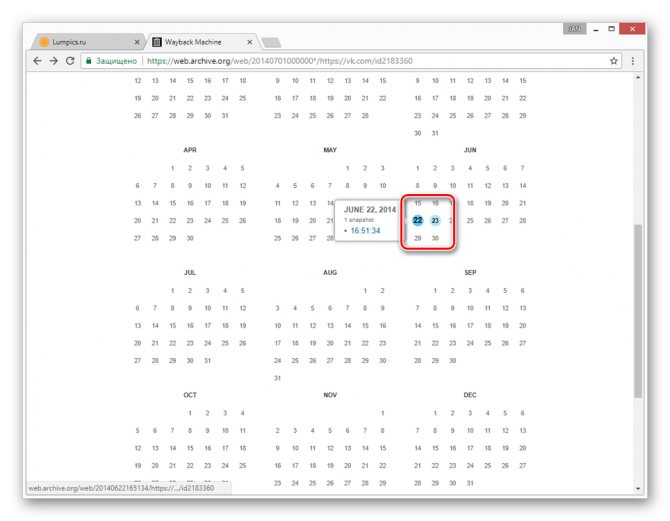
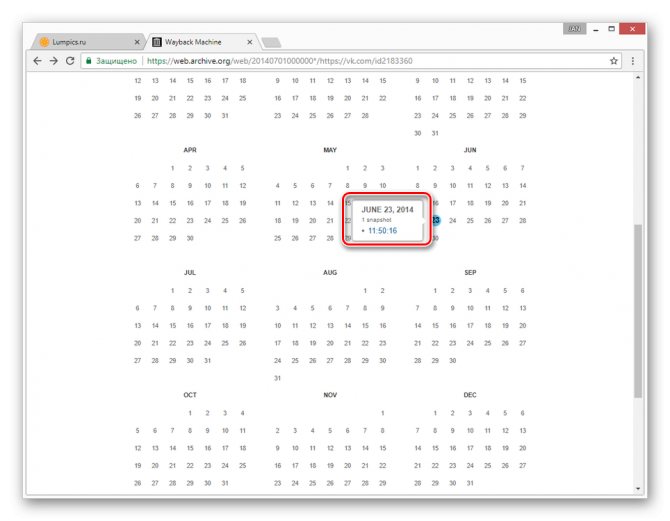
Теперь вам будет представлена страница пользователя, но лишь на английском языке.
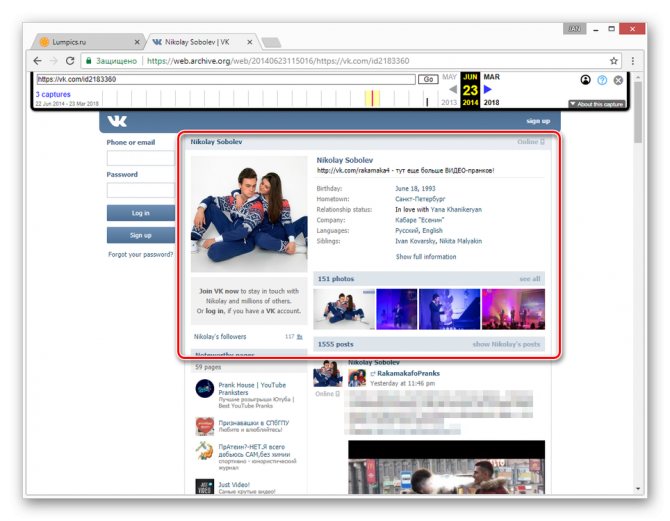
Вы можете просматривать только ту информацию, которая не была скрыта настройками приватности на момент ее архивирования. Любые кнопки и прочие возможности сайта будут недоступны.
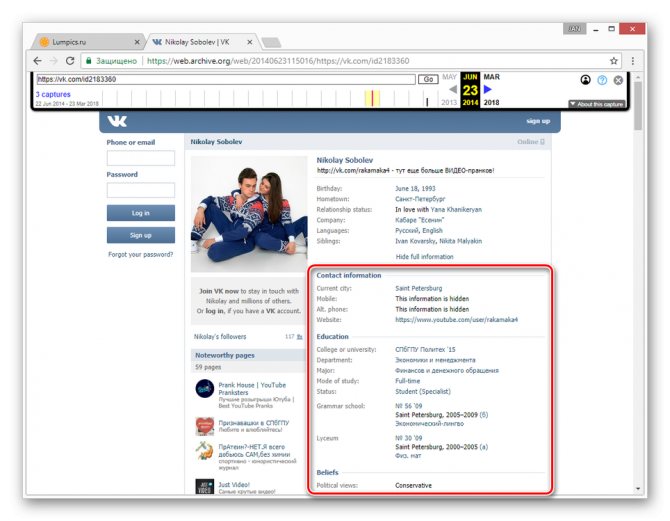
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Первый сайт в зоне .ru
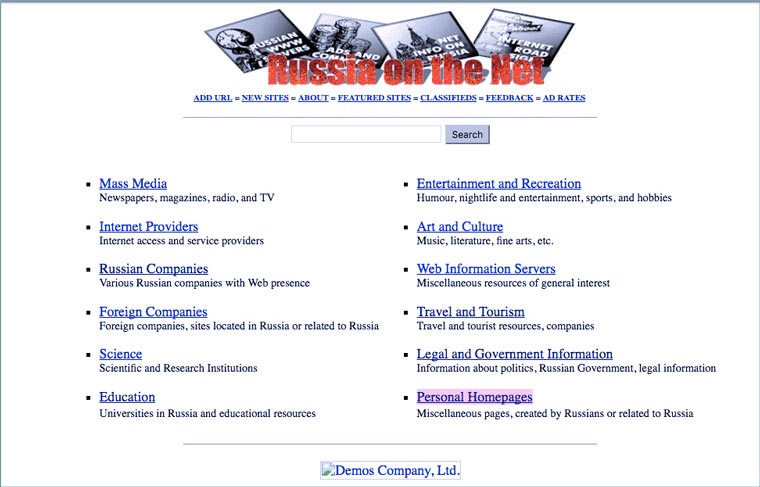
7 апреля 1994 года был зарегистрирован домен .ru. Вскоре на нем был размещен сайт http://www.ru, который назывался Russia on the Net. Это был каталог ссылок на русскоязычные страницы и англоязычные сайты отечественных компаний.
Создали этот сайт в фирме «Демос», бывшим программистском кооперативе, существовавшем с 1989 года. Ранее они участвовали в создании первой отечественной компьютерной сети «Релком» и регистрации доменной зоны .su, в которой с 1990 по 1994 год было размещено более 1000 сайтов (в основном научных учреждений).
К сожалению, найти первые сайты в зоне .su сейчас сложно и, поэтому, статья будет о первых сайтах в зоне .ru, которые засветились во Всемирном Архиве Интернета (основан в 1996 году).
Сохраненная страница: 14 ноября 1996 года.
Использование сервиса WebArchive
Всем, кто задается вопросом, где посмотреть старые версии сайтов, можно порекомендовать воспользоваться таким интересным сервисом как WebArchive.
Его функционал гораздо шире, чем у кэша поисковиков, можно просмотреть, как видоизменялся сайт за месяцы и годы своего существования, а также воспользоваться поиском по конкретному числу, когда была сохранена копия содержимого страницы.
Для того, чтобы воспользоваться сервисом, в поиске на сайте WebArchive введите адрес искомой страницы. Также поддерживается поиск по ключевым словам, относящимся к тематике ресурса — можно воспользоваться им. Как только вы это сделаете, появится статистика по годам. Черным цветом отмечено, в какое время создавалась резервная копия сайта, сохраненная в архиве.

Как только вы выберете нужный год и перейдете на него, откроется календарь, в котором можно выбрать число, за которое была сохранена резервная копия страницы сайта.
Зеленым и синим цветом отмечены даты, когда поисковые роботы заархивировали страницу и добавили ее к просмотру.
Как правило, возможность просмотра изображений отсутствует, однако текст сохраняется в полном объеме. А если вы ищете какую-либо конкретную статью на определенном ресурсе, есть вероятность, что ссылка на нее могла сохраниться.
r-tools.org

Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;
в этом подменю нажмите «Работать автономно».
Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
IT-специалист и продвинутый пользователь ВК. Зарегистрировался в соцсети в 2007 году.
Где взять уникальный контент для сателлитов?
Оригинальный контент, пожалуй, один из важнейших параметров для хорошего сателлита. Несколько способом его получить:
Копирайтинг:
Самый простой и самый дорогостоящий метод. Необходимо создать техническое задание и отдать его SEO-копирайтеру, который напишет для вас уникальный, оптимизированный текст. Остается только разместить его.
Рерайт :
Более практичный способ получить уникальный материал для сайта. Рерайт – это переписывание уже созданного кем-то текста. В интернете размещено огромное количество контента. Качественный рерайт также, как и копирайтинг, даст вам уникальный, читабельный материал. Такой контент будет хорошо восприниматься и посетителями, и роботами поисковых систем.
Генерация текстов по шаблонам:
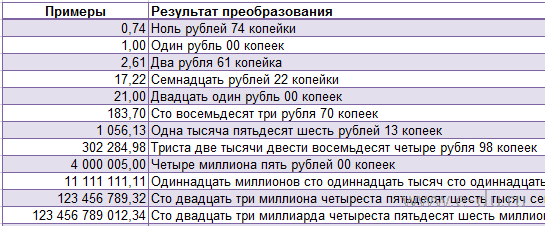
Можно назвать этот способ автоматическим рерайтом текста. Позволяет получить из одного материала множество новых. В этом вам помогут сервисы онлайн-генерации текстов. Например, Seogenerator. Принцип работы строится на использовании конструкций, которые заменяют фрагменты текущего текста на заданные варианты. Вот простой пример.
Задаем шаблон:
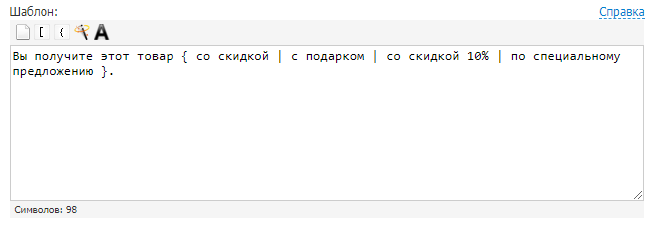
Получаем тексты:
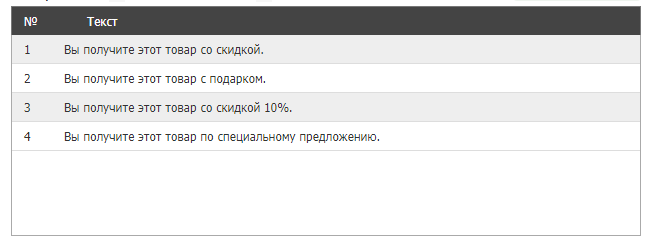
Важно следить за качеством, осмысленностью и уникальностью полученных материалов, объемные тексты проверять на возможный переспам. Вы формируете YML-выгрузку товаров
Почти все популярные CMS сегодня умеют экспортировать данные в YML-файлы. В полученную выгрузку вносите небольшие корректировки в ценах, размерах скидки, названиях товаров и используете ее для наполнения сателлита
Вы формируете YML-выгрузку товаров. Почти все популярные CMS сегодня умеют экспортировать данные в YML-файлы. В полученную выгрузку вносите небольшие корректировки в ценах, размерах скидки, названиях товаров и используете ее для наполнения сателлита.
Восстановление контента из веб-архива:
Ищем «дропы» – домены, у которых закончился срок регистрации – схожей тематики. Найти такие домены можно, например, с помощью Reg.ru. Проверяем историю, обратные ссылки, анкоры, не менялась ли тематика и т.д. Восстанавливаем нужный контент из веб-архива и получаем уникальный сайт. Для скачивания файлов из архива есть готовые сервисы, например, Archivarix. Все сайты имеют свои особенности, поэтому при восстановлении могут быть ошибки. Наш совет – заниматься восстановлением старых сайтов вместе с разработчиком.
Сеть тематических сайтов
Люди работающие в конкретной сфере, например «бухгалтерские услуги», ищут в веб-архиве сайты по данной тематике. После их восстановления могут использовать как для социальных сетей (разных групп), в качестве сайтов визиток, так и для того что бы «забить» поисковую выдачу. Таким образом получается создать большую сетку сайтов для продвижения своего бизнеса за маленькие деньги, т.к. стоимость восстановленного сайта очень низкая в сравнении даже с разработкой бюджетного проекта.
Еще данная сетка может служить в качестве источника ссылочной массы на основной продвигаемый ресурс. Ссылки постепенно «отмирают», но по-прежнему еще имеют вес в фактораъ ранжирования.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
Кеш Google
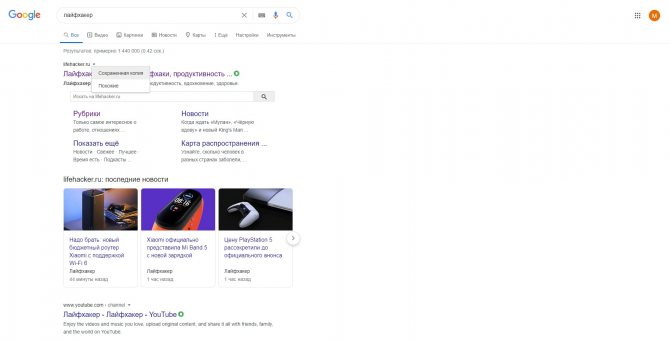
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: https://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
Кеш «Яндекса»
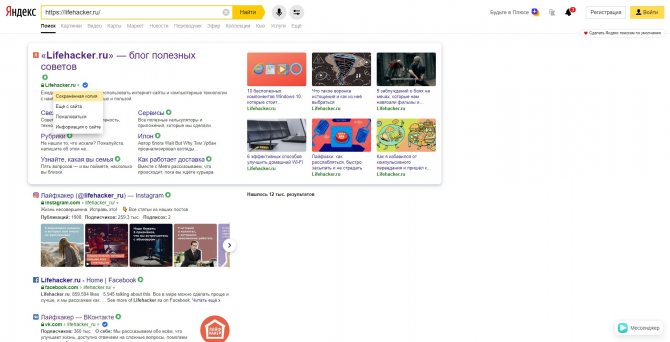
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
Кеш Bing
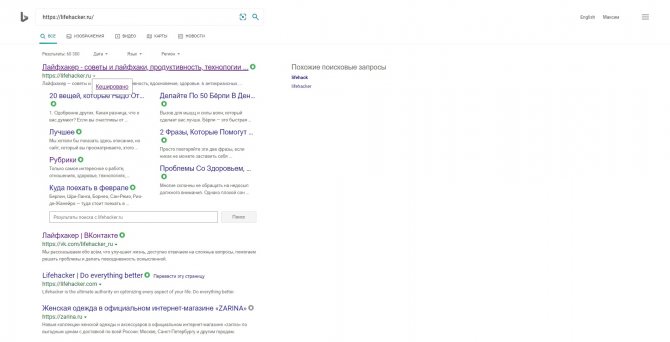
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
Кеш Yahoo
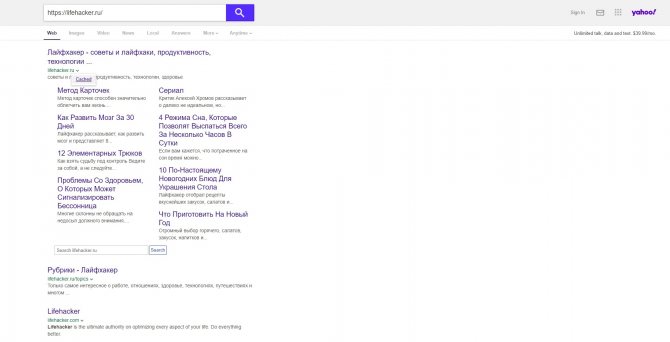
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Альтернативы сохраненной копии Яндекса
Яндекс — не единственный поисковик в мире. Просто он лучше адаптирован и ориентирован больше на русскоязычный сегмент интернета. Тем не менее, всегда есть альтернативные способы найти копию своего сайта в интернете:
- Google. Полный аналог Яндекс и по функционалу, и по возможности найти резервную копию сайта. Найти ее можно точно так же, как в российском поисковике — нажав стрелочку рядом с выбранным пунктом выдачи и открыв пункт «Сохраненная копия».
- Web.archive.org. Огромная база сохраненных сайтов с просторов всего интернета. Вероятность попадания туда относительно молодого сайта крайне мала, однако она есть.
- CachedView.com. Это поисковик по сохраненным копиям на различных ресурсах, в том числе и в Google.

Естественно, не стоит игнорировать и менее известные поисковые системы. Это может быть Рамблер, Yahoo, поиск от Mail.ru, Bing, Апорт. Возможно, кто-то из них закэшировал нужный веб-ресурс.
Утилиты для сохранения сайтов целиком
Есть программы для копирования ресурсов глобальной сети целиком. То есть со всем контентом, переходами, меню, ссылками. По такой странице можно будет «гулять», как по настоящей. Для этого подойдут следующие утилиты:
- HTTrack Website Copier.
- Local Website Archive.
- Teleport Pro.
- WebCopier Pro.
Есть много способов перенести страницу сайта на ПК. Какой выбрать — зависит от ваших нужд. Если хотите сохранить информацию, чтобы потом её изучить, достаточно обычного снимка экрана. Но когда надо работать с этими данными, редактировать их, добавлять в документы, лучше скопировать их или создать html-файл.
Качаем сайт с web-arhive.ru
Это самый геморройный вариант ибо у данного сервиса нет возможности скачать сайт как у описанного выше. Соответственно пользоваться этим вариантом есть смысл пользоваться только в случае если нужно скачать сайт, которого нет на web.archive.org. Но я сомневаюсь что такое возможно. Этим вариантом я пользовался по причине того, что не знал других вариантов,а поискать поленился.
В итоге я написал скрипт, который позволяет скачать архив сайта с web-arhive.ru. Но велика вероятность того, что это будет сопровождаться ошибками, поскольку скрипт сыроват и был заточен под скачивание определенного сайта. Но на всякий случай я выложу этот скрипт.
Вот ссылка: https://yadi.sk/d/zoMRxwPoSXh0Jw
Пользоваться им довольно просто. Для запуска скачивания необходимо запустить этот скрипт все в той же командной строке, где в качестве параметра вставить ссылку на копию сайта. Должно получиться что-то типа такого:
php get_archive.php «http://web-arhive.ru/view2?time=20160320163021&url=http%3A%2F%2Fremontistroitelstvo.ru%2F»
Заходим на сайт web-arhive.ru, в строке указываем домен и жмем кнопку «Найти». Ниже должны появится года и месяцы в которых есть копии.

Обратите внимание на то, что слева и справа от годов и месяцев есть стрелки, кликая которые можно листать колонки с годами и месяцами

Остается найти дату с нужной копией, скопировать ссылку из адресной строки и отдать её скрипту. Не забывает помещать ссылку в кавычки во избежание ошибок из-за наличия спецсимволов.
Мало того, что само скачивание сопровождается ошибками, более того, в выбранной копии сайта может не быть каких-то страниц и придется шерстить все копии на предмет наличия той или иной страницы.
Создание задачи

Вводим название задачи и переходим на следующий шаг к настройкам сбора. Тут есть чекбокс “Выбрать период”, чтобы скачать документы по установленной дате. Если чекбокс не будет активирован — система скачает документ по последней доступной дате.
Рекомендуем не включать этот чекбокс, если вы точно не знаете за какую дату вам нужна копия. Если домен, например, старый и вы точно знаете, за какую дату нужна копия, тогда просто выбираете в календаре:

Чекбоксы “Сделать пути относительными” и “Удалить счетчики статистики” рекомендуется всегда оставлять включенными — они помогут избежать различных проблем при переносе копии сайта на ваш сервер.
Далее, переходим на третий шаг и вводим адрес домена (без http и www), который нужно восстановить и после этого жмем “Добавить домен”:

Важно: на данный момент поддерживаются только задачи по 1 домену, поэтому если вам надо восстановить несколько сайтов, придется создать несколько задач. Далее нажимаем “Создать новую задачу” и подтверждаем запуск
Далее нажимаем “Создать новую задачу” и подтверждаем запуск.
Что такое исходящие ссылки
Для начала, немного теории и терминов. В SEO часто упоминаются два субъекта — донор и акцептор. Донор — это сайт, с которого ведет ссылка, акцептор, соответственно — сайт, на который ссылается донор. Исходящие ссылки — это линки, ведущие с сайта-донора на сайт-акцептор. Все очень просто. При добавлении на сайт исходящих ссылок, нужно руководствоваться некоторыми правилами и здравым смыслом. При чем здесь смысл, может спросить неопытный вебмастер? Да при том, что современные сеошники очень часто боятся исходящих ссылок, считая их вселенским злом, и пытаясь непременно закрыть от индексации даже ссылки на соцсети. Все это ерунда. Исходящие ссылки никакого вреда не несут, если сайт-акцептор — тематический, анкоры — некоммерческие, общий уровень заспамленности сайта-донора — невысокий. Более, того, ссылаясь на авторитетные ресурсы, вы только поднимете уровень доверия поисковиков к вашему ресурсу. Также, следует понимать, что если сайт — , то ни входящие, ни исходящие ссылки не помогут, нужно удалить все папочки с сервера, и не забыть про базу данных хотя бы довести его до ума в плане внутренней оптимизации.
Зачем был придуман первый веб-сайт
 Главная страница сайта
Главная страница сайта
Цель проекта банальна для эпохальной технологии на начальной стадии — упростить работу команде. Марк Цукерберг затем же создавал Facebook, чтобы ему и его одногруппникам было проще общаться друг с другом.
ЦЕРН отклонил идею, но Бернерс Ли проявил настойчивость и продолжил разрабатывать сайт, уже в команде с Робертом Кайо.
 Так раньше выглядел ЦЕРН, Европейская организация по ядерным исследованиям, крупнейшая в мире лаборатория физики высоких энергий.
Так раньше выглядел ЦЕРН, Европейская организация по ядерным исследованиям, крупнейшая в мире лаборатория физики высоких энергий.
Ученый предложил сделать так, чтобы гипертекст был доступен одновременно нескольким компьютерам, подключенным к интернету.
«Меня расстраивало, на разных компьютерах содержалась разная информация. И чтобы получить к ней доступ к нескольким источникам, нужно задействовать несколько компьютеров», — говорил Бернерс Ли.
 NeXT. Компьютер, на котором был создан первый веб-сайт.
NeXT. Компьютер, на котором был создан первый веб-сайт.
У британца была и более масштабная задача. В ЦЕРН приезжали люди из университетов со всего мира, и привозили с собой компьютеры со всеми видами программного обеспечения. Проблемой была невозможность использования одной программы на компьютерах с разными видами софта.
Бернерс Ли искал ее решение. Изначально он думал о создании ряда программ, берущих информацию из одной системы и конвертирующих ее формат для показа в другой.
Но оптимизировать программы под каждый софт — долго, энергозатратно и дорого. Британец выбрал другой способ: просто дать доступ к информации всем сразу.
Инструкция по получению уникальных статей с вебархива
1. Запускаем ваш любимый браузер и вводим адрес web.archive.org.
Главная страница вебархива, где будем искать статьи
2. В поисковой строке набираем интересующую вас тематику, например «траляля»
3. Смотрим выдачу сайтов из вебархива
4. Анализируем домены по следующим признакам
4.1. Количество страниц в вебархиве должно быть больше 50
Выдача вебархива, где можно увидеть сколько страниц в архиве
4.2. Проверяем сайт на работоспособность, для этого копируем домен и вставляем в адресную строку браузера. В нашем случае это домен www.generix.com.ua, он оказался свободен.
4.3. Если же домен будет занят и на нем будет находится сайт по схожей тематике то повторите пункты 4.1 и 4.2
4.4. Проверяем таким образом все домены в выдаче вебархива и сохраняем в блокнот те домены которые нам подходят.
5. Скачиваем программу Web Archive Downloader и с помощью нее сохраняем на компьютер архивные копии сайтов, более подробно по работе с программой вы можете ознакомиться в разделе FAQ.
6. Проверяем полученные статьи на уникальность (как читайте ниже)
7. Используем полученные уникальные статьи по назначению
В принципе все, как вы видите ничего сложного нет, осталось разобраться как проверять статьи на уникальность массово. Ведь вы скачаете их
большое количество.