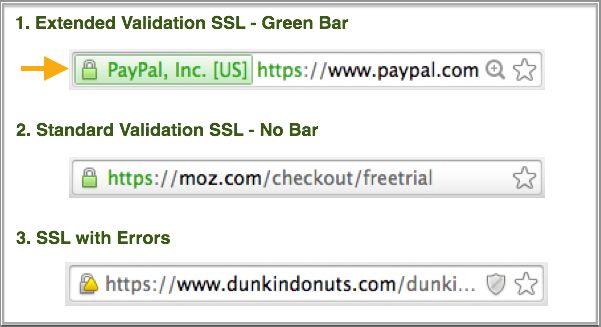
Протокол передачи данных http
Содержание:
- Glossary
- HTTP-заголовки
- HTTP Request Methods
- OPTIONS Method
- POST Method
- GET Method
- Request-URI
- HTTP POST
- HTML Справочник
- HTML Теги
- Exec — Выполнение кода, консоль запросов и не только!
- HTML Теги
- Специфика HTTP
- HTTP GET
- Параметры запроса
- Как работает HTTP, и зачем нам это знать
- HTTP-запросы
- Коды состояния
- 3.1 Content-Type: application/x-www-form-urlencoded.
- Основы
Glossary
Safe Methods
As per HTTP specification, the GET and HEAD methods should be used only for retrieval of resource representations – and they do not update/delete the resource on the server. Both methods are said to be considered “safe“.
This allows user agents to represent other methods, such as POST, PUT and DELETE, in a unique way so that the user is made aware of the fact that a possibly unsafe action is being requested – and they can update/delete the resource on server and so should be used carefully.
Idempotent Methods
The term idempotent is used more comprehensively to describe an operation that will produce the same results if executed once or multiple times. Idempotence is a handy property in many situations, as it means that an operation can be repeated or retried as often as necessary without causing unintended effects. With non-idempotent operations, the algorithm may have to keep track of whether the operation was already performed or not.
In HTTP specification, The methods GET, HEAD, PUT and DELETE are declared idempotent methods. Other methods OPTIONS and TRACE SHOULD NOT have side effects, so both are also inherently idempotent.
References:
https://www.w3.org/Protocols/rfc2616/rfc2616.txthttp://tools.ietf.org/html/rfc6902
HTTP-заголовки
HTTP-сообщение состоит из начальной строки, за которой следуют набор заголовков, пустая строка и некоторые данные. Начальная строка задает действие, требуемое от сервера, тип возвращаемых данных или код состояния.
HTTP-заголовки можно подразделить на три крупные категории: заголовки, посылаемые в запросе, заголовки, посылаемые в ответе, и те, которые можно включать как в запросы, так и в ответы. Заголовки запросов указывают возможности клиента, например, типы документов, которые может обработать клиент, в то время как заголовки ответов предоставляют информацию о возвращенном документе.
Заголовки запросов
К числу наиболее важных HTTP-заголовков, которые можно включать в запросы, но нельзя включать в ответы, относятся:
- Заголовок Accept
-
Это список MIME-типов, принимаемых клиентом, в формате тип/подтип. Элементы списка должны разделяться запятыми:
Accept: text/html, image/gif, */*
Элемент */* указывает, что все типы будут приняты и обработаны клиентом. Если тип запрошенного файла не может быть обработан клиентом, возвращается ошибка HTTP 406 «Not acceptable» (недопустимо).
- Заголовок From
-
Указывает адрес электронной почты в Интернете учетной записи пользователя, под которой работает клиент, направивший запрос:
From: alexerohinzzz@gmail.com
- Заголовок Referer
-
Позволяет клиенту указать адрес (URI) ресурса, из которого получен запрашиваемый URI. Этот заголовок дает возможность серверу сгенерировать список обратных ссылок на ресурсы для будущего анализа, регистрации, оптимизированного кэширования и т.д. Он также позволяет прослеживать с целью последующего исправления устаревшие или введенные с ошибками ссылки:
Referer: http://www.professorweb.ru
- Заголовок User-Agent
-
Представляет собой строку, идентифицирующую приложение-клиент (обычно браузер) и платформу, на которой оно выполняется. Общий формат имеет вид: программа/версия библиотека/версий, но это не неизменный формат:
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.56 Safari/537.17
Эта информация может использоваться в статистических целях, для отслеживания нарушений протокола и для автоматического распознавания клиента. Она позволяет приспособить ответ так, чтобы не нарушить ограниченные возможности конкретного клиента, например неспособность поддерживать HTML-таблицы.
Заголовки ответов
В ответы могут включаться следующие заголовки:
- Заголовок Content-Type
-
Используется для указания типа данных, отправляемых получателю или, в случае метода HEAD, тип данных, который был бы отправлен в ответ на запрос GET:
Content-Type: text/html
- Заголовок Expires
-
Представляет собой момент времени, после которого информация в документе становится недостоверной. Клиенты, использующие кэширование, в частности прокси-серверы, не должны хранить в кэше эту копию ресурса после заданного времени, если только состояние копии не было обновлено более поздним обращением к исходному серверу:
Expires: Fri, 19 Aug 2012 16:00:00 GMT
- Заголовок Location
-
Определяет точное расположение другого ресурса, к которому может быть перенаправлен клиент. Если это значение представляет собой полный URL, сервер возвращает клиенту «redirect» для непосредственного извлечения указанного объекта:
Location: http://www.samplesite.com
Если ссылка на другой файл относится к серверу, должен указываться частичный URL.
- Заголовок Server
-
Содержит информацию о программном обеспечении, используемом исходным сервером для обработки запроса:
Server: Microsoft-IIS/7.0
Общие заголовки
Несколько заголовков могут включаться как в запрос, так и в ответ, например:
- Заголовок Date
-
Используется для установки даты и времени создания сообщения:
Date: Tue, 16 Aug 2012 18:12:31 GMT
- Заголовок Connection
-
В НТТР/1.0 мы могли использовать в запросе заголовок Connection, указывая, что хотим сохранить соединение после отправки ответа. Теперь такое поведение принято по умолчанию, и в HTTP/1.1 можно использовать заголовок Connection, чтобы указать, что постоянное соединение не нужно:
Connection: close
HTTP Request Methods
The internet boasts a vast array of resources hosted on different servers. For you to access these resources, your browser needs to be able to send a request to the servers and display the resources for you. HTTP (Hypertext Transfer Protocol), is the underlying format that is used to structure request and responses for effective communication between a client and a server. The message that is sent by a client to a server is what is known as an HTTP request. When these requests are being sent, clients can use various methods.
Therefore, HTTP request methods are the assets that indicate the specific desired action to be performed on a given resource. Each method implements a distinct semantic, but there are some standard features shared by the various HTTP request methods.
OPTIONS Method
The OPTIONS method is used by the client to find out the HTTP methods and other options supported by a web server. The client can specify a URL for the OPTIONS method, or an asterisk (*) to refer to the entire server. The following example requests a list of methods supported by a web server running on tutorialspoint.com:
OPTIONS * HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT)
The server will send an information based on the current configuration of the server, for example:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Allow: GET,HEAD,POST,OPTIONS,TRACE Content-Type: httpd/unix-directory
POST Method
The POST method is used when you want to send some data to the server, for example, file update, form data, etc. The following example makes use of POST method to send a form data to the server, which will be processed by a process.cgi and finally a response will be returned:
POST /cgi-bin/process.cgi HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Content-Type: text/xml; charset=utf-8 Content-Length: 88 Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive
<?xml version="1.0" encoding="utf-8"?> <string xmlns="http://clearforest.com/">string</string>
The server side script process.cgi processes the passed data and sends the following response:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Vary: Authorization,Accept Accept-Ranges: bytes Content-Length: 88 Content-Type: text/html Connection: Closed
<html> <body> <h1>Request Processed Successfully</h1> </body> </html>
GET Method
A GET request retrieves data from a web server by specifying parameters in the URL portion of the request. This is the main method used for document retrieval. The following example makes use of GET method to fetch hello.htm:
GET /hello.htm HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive
The server response against the above HEAD request will be as follows:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Vary: Authorization,Accept Accept-Ranges: bytes Content-Length: 88 Content-Type: text/html Connection: Closed
<html> <body> <h1>Hello, World!</h1> </body> </html>
Request-URI
The Request-URI is a Uniform Resource Identifier and identifies the resource upon which to apply the request. Following are the most commonly used forms to specify an URI:
Request-URI = "*" | absoluteURI | abs_path | authority
| S.N. | Method and Description |
|---|---|
| 1 | The asterisk * is used when an HTTP request does not apply to a particular resource, but to the server itself, and is only allowed when the method used does not necessarily apply to a resource. For example:
OPTIONS * HTTP/1.1 |
| 2 | The absoluteURI is used when an HTTP request is being made to a proxy. The proxy is requested to forward the request or service from a valid cache, and return the response. For example:
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.1 |
| 3 | The most common form of Request-URI is that used to identify a resource on an origin server or gateway. For example, a client wishing to retrieve a resource directly from the origin server would create a TCP connection to port 80 of the host «www.w3.org» and send the following lines:
GET /pub/WWW/TheProject.html HTTP/1.1 Host: www.w3.org Note that the absolute path cannot be empty; if none is present in the original URI, it MUST be given as «/» (the server root). |
HTTP POST
Use POST APIs to create new subordinate resources, e.g., a file is subordinate to a directory containing it or a row is subordinate to a database table. When talking strictly in terms of REST, POST methods are used to create a new resource into the collection of resources.
Ideally, if a resource has been created on the origin server, the response SHOULD be HTTP response code and contain an entity which describes the status of the request and refers to the new resource, and a Location header.
Many times, the action performed by the POST method might not result in a resource that can be identified by a URI. In this case, either HTTP response code or is the appropriate response status.
Responses to this method are not cacheable, unless the response includes appropriate or Expires header fields.
Please note that POST is neither safe nor idempotent, and invoking two identical POST requests will result in two different resources containing the same information (except resource ids).
HTML Справочник
HTML Теги по алфавитуHTML Теги по категорииHTML ПоддержкаHTML АтрибутыHTML ГлобальныеHTML СобытияHTML Названия цветаHTML ХолстHTML Аудио/ВидеоHTML ДекларацииHTML Набор кодировокHTML URL кодHTML Коды языкаHTML Коды странHTTP СообщенияHTTP методыКовертер PX в EMКлавишные комбинации
HTML Теги
<!—…—>
<!DOCTYPE>
<a>
<abbr>
<acronym>
<address>
<applet>
<area>
<article>
<aside>
<audio>
<b>
<base>
<basefont>
<bdi>
<bdo>
<big>
<blockquote>
<body>
<br>
<button>
<canvas>
<caption>
<center>
<cite>
<code>
<col>
<colgroup>
<data>
<datalist>
<dd>
<del>
<details>
<dfn>
<dialog>
<dir>
<div>
<dl>
<dt>
<em>
<embed>
<fieldset>
<figcaption>
<figure>
<font>
<footer>
<form>
<frame>
<frameset>
<h1> — <h6>
<head>
<header>
<hr>
<html>
<i>
<iframe>
<img>
<input>
<ins>
<kbd>
<label>
<legend>
<li>
<link>
<main>
<map>
<mark>
<meta>
<meter>
<nav>
<noframes>
<noscript>
<object>
<ol>
<optgroup>
<option>
<output>
<p>
<param>
<picture>
<pre>
<progress>
<q>
<rp>
<rt>
<ruby>
<s>
<samp>
<script>
<section>
<select>
<small>
<source>
<span>
<strike>
<strong>
<style>
<sub>
<summary>
<sup>
<svg>
<table>
<tbody>
<td>
<template>
<textarea>
<tfoot>
<th>
<thead>
<time>
<title>
<tr>
<track>
<tt>
<u>
<ul>
<var>
<video>
<wbr>
Exec — Выполнение кода, консоль запросов и не только!
Незаменимый инструмент администратора БД и программиста:
Выполняйте произвольный код из режима 1С Предприятие; сохраняйте/загружайте часто используемые скрипты; выполняйте запросы с замером производительности запроса в целом и каждой из временных таблиц в частности, а также с просмотром содержимого временных таблиц; произвольным образом изменяйте любые объекты БД, редактируя даже не вынесенные на формы реквизиты и записывая изменения в режиме «ОбменДанными.Загрузка = Истина»; легко узнавайте ИД объектов БД; выполняйте прямые запросы к SQL с замером производительности и не только!
5 стартмани
HTML Теги
<!—…—><!DOCTYPE><a><abbr><acronym><address><applet><area><article><aside><audio><b><base><basefont><bdi><bdo><big><blockquote><body><br><button><canvas><caption><center><cite><code><col><colgroup><data><datalist><dd><del><details><dfn><dialog><dir><div><dl><dt><em><embed><fieldset><figcaption><figure><font><footer><form><frame><frameset><h1> — <h6><head><header><hr><html><i><iframe><img><input><ins><kbd><label><legend><li><link><main><map><mark><meta><meter><nav><noframes><noscript><object><ol><optgroup><option><output><p><param><picture><pre><progress><q><rp><rt><ruby><s><samp><script><section><select><small><source><span><strike><strong><style><sub><summary><sup><svg><table><tbody><td><template><textarea><tfoot><th><thead><time><title><tr><track><tt><u><ul><var><video>
Специфика HTTP
Интернет протокол HTTP отличается от других протоколов тем, что создает отдельную TCP-сессию на любой запрос. В следующих версиях протокола было разрешено выполнять несколько запросов во время одной TCP-сессии. Но при этом браузеры, как правило, делают запрос только на страницу и находящиеся в ней объекты (изображения, таблицы стилей и так далее), а затем сразу прерывают TCP-сессию.

TCP/IP
Чтобы поддерживать авторизованный доступ в протоколе HTTP используются файлы cookies, представляющие собой небольшие части данных, отосланные веб-сервером и сохраняемые на компьютере в браузере. Веб-клиент, пытаясь открыть страницу нужного сайта посылает этот фрагмент информации веб-серверу в виде HTTP-запроса.
HTTP GET
Use GET requests to retrieve resource representation/information only – and not to modify it in any way. As GET requests do not change the state of the resource, these are said to be safe methods. Additionally, GET APIs should be idempotent, which means that making multiple identical requests must produce the same result every time until another API (POST or PUT) has changed the state of the resource on the server.
If the Request-URI refers to a data-producing process, it is the produced data which shall be returned as the entity in the response and not the source text of the process, unless that text happens to be the output of the process.
For any given HTTP GET API, if the resource is found on the server, then it must return HTTP response code – along with the response body, which is usually either XML or JSON content (due to their platform-independent nature).
In case resource is NOT found on server then it must return HTTP response code . Similarly, if it is determined that GET request itself is not correctly formed then server will return HTTP response code .
Example request URIs
- HTTP GET http://www.appdomain.com/users
- HTTP GET http://www.appdomain.com/users?size=20&page=5
- HTTP GET http://www.appdomain.com/users/123
- HTTP GET http://www.appdomain.com/users/123/address
Параметры запроса
Мы привыкли, что на нашем сайте каждый PHP-сценарий отвечает за одну страницу. Посетитель сайта вводит в адресную строку путь, который состоит из имени домена и имени PHP-сценария. Например, так: .
Но как быть, если одна страница должна показывать разную информацию?
На сайте дневника наблюдений за погодой мы сделали отдельную страницу, чтобы показывать на ней информацию о погоде из истории за один конкретный день. То есть страница одна, но показывает разные данные, в зависимости от выбранного дня.
Также пользователи хотят добавить в закладки адреса страниц с нужными им днями. Получается, что имея только один сценарий сделать страницу, способную показывать дневник погоды за любой день невозможно? Вовсе нет!
Из чего состоит URI
URI — это уникальный идентификатор ресурса. Ресурс в нашем случае — это полный путь до страницы сайта. И вот как может выглядеть ресурс для показа погоды за конкретный день:
Разберем, из чего состоит этот URI.
Во-первых, здесь есть имя домена: .
Затем идёт имя сценария:
А всё что идёт после — это параметры запроса.
Параметры запроса — это как бы дополнительные атрибуты адреса страницы. Они отделяются от имени страницы знаком запроса. В примере выше параметр запроса только один: date=2017-10-30.
Имя этого параметра:, значение: .
Параметров запроса может быть несколько, тогда они разделяются знаком амперсанда:
В примере выше указывается два аргумента: дата и единица измерения температуры.
Параметры запроса как внешние переменные
Теперь в адресе страницы используются параметры запроса, но какая нам от этого польза? Она состоит в том, что если имя страницы вызывает к исполнению соответствующий PHP-сценарий, то параметры запроса превращаются в специальные внешние переменные в этом сценарии. То есть, если в адресе присутствуют такие параметры, то их легко получить внутри кода сценария и выполнить с ними какие-нибудь действия. Например, показать погоду за конкретный день в выбранных единицах измерения.
Получение параметров запроса
Если есть внешние переменные, то как их прочитать?
Все параметры запроса находятся в специальном, ассоциативном массиве , а значит сценарий, вызванный с таким адресом: будет иметь в этом массиве два значения с ключами и .
Запрос на получение данных за выбранный день выглядит так:
В первой строчке примера выше мы получаем значение параметра , а если он отсутствует, то используем текущую дату в качестве выбранного дня.Никогда не полагайтесь на существование параметра в массиве и делайте проверку либо функцией , либо как в этом примере.
В этом задании вы сможете потренироваться использовать .
Формирование URI с параметрами запроса
Иногда нужно совершить обратную операцию: сформировать адрес страницы, включив туда нужные параметры запроса из массива.
Скажем, на странице погодного дневника надо поставить ссылку на следующий и предыдущий день. Нужно также сохранить выбранную единицу измерений. То есть необходимо сохранить текущие параметры запроса, поменять значение одного из них (день), и сформировать новую ссылку.
Вот как это можно сделать:
Здесь мы использовали две функции:
- — получает имя текущего сценария;
- — преобразует ассоциативный массив в строку запроса.
Как работает HTTP, и зачем нам это знать
Программировать на PHP можно и без знания протокола HTTP, но есть ряд ситуаций, когда для решения задач нужно знать, как именно работает веб-сервер. Ведь PHP — это, в первую очередь, серверный язык программирования.
Протокол HTTP очень прост и состоит, по сути, из двух частей:
- Заголовков запроса/ответа;
- Тела запроса/ответа.
Сначала идёт список заголовков, затем пустая строка, а затем (если есть) тело запроса/ответа.
И клиент, и сервер могут посылать друг другу заголовки и тело ответа, но в случае с клиентом доступные заголовки будут одни, а с сервером — другие. Рассмотрим пошагово, как будет выглядеть работа по протоколу HTTP в случае, когда пользователь хочет загрузить главную страницу социальной сети «Вконтакте».
1. Браузер пользователя устанавливает соединение с сервером vk.com и отправляет следующий запрос:
GET / HTTP/1.1 Host: vk.com
2. Сервер принимает запрос и отправляет ответ:
3. Браузер принимает ответ и показывает готовую страницу
Больше всего нам интересен самый первый шаг, где браузер инициирует запрос к серверу vk.com
Рассмотрим подробнее, что там происходит. Первая строка запроса определяет несколько важных параметров, а именно:
- Метод, которым будет запрошен контент;
- Адрес страницы;
- Версию протокола.
— это метод (глагол), который мы применяем для доступа к указанной странице. является самым часто используемым методом, потому что он говорит серверу о том, что клиент всего лишь хочет прочитать указанный документ. Но помимо есть и другие методы, один из них мы рассмотрим уже в следующем разделе.
После метода идет указание на адрес страницы — URI (универсальный идентификатор ресурса). В нашем случае мы запрашиваем главную страницу сайта, поэтому используется просто слэш — .
Последним в этой строке идет версия протокола и почти всегда это будет
После строки с указанием основных параметров всегда следует перечисление заголовков, которые передают серверу дополнительную полезную информацию: название и версию браузера, язык, кодировку, параметры кэширования и так далее.
Среди всех этих заголовков, которые передаются при каждом запросе, есть один обязательный и самый важный — это заголовок . Он определяет адрес домена, который запрашивает браузер клиента.
Сервер, получив запрос, ищет у себя сайт с доменом из заголовка , а также указанную страницу.
Если запрошенный сайт и страница найдены, клиенту отправляется ответ:
Такой ответ означает, что всё хорошо, документ найден и будет отправлен клиенту. Если говорить более обобщённо, стартовая строка ответа имеет следующую структуру:
Больше всего здесь интересен именно код состояния, он же код ответа сервера.
В этом примере код ответа — 200, что означает: сервер работает, документ найден и будет передан клиенту. Но не всегда всё идет гладко.
Например, запрошенный документ может отсутствовать или сервер будет перегружен, в таком случае клиент не получит контент, а код ответа будет отличным от 200.
- 404 — если сервер доступен, но запрошённый документ не найден;
- 503 — если сервер не может обрабатывать запросы по техническим причинам.
Спецификация HTTP 1.1 определяет 40 различных кодов HTTP.
После стартовой строки следуют заголовки, а затем тело ответа.
HTTP-запросы
Каждый клиент посылает запрос, и сервер на него отвечает. Все запросы и ответы состоят из трех частей, а именно: строки запроса или ответа, секции заголовков и тела сущности (любого содержания, отправляемого вместе с сообщением, например, страницы HTML для отображения в браузере или данных формы, пересылаемых на сервер).
Клиент связывается с сервером в назначенном номере порта (по умолчанию равном 80) и запрашивает у сервера документ, задавая HTTP-команду, называемую методом, за которой следует адрес документа и номер версии HTTP. Клиент также отправляет серверу необязательную информацию в заголовках, чтобы сообщить серверу о своей конфигурации и приемлемых для него форматах документов. Информация заголовка дается в одной строке вместе с именем и значением заголовка. После заголовков клиент посылает пустую строку. Затем клиент отправляет дополнительные данные. Это могут быть данные формы, отправляемые на сервер методом POST, или файл, копируемый на сервер методом PUT.
Запросы клиентов подразделяются на три секции. Первая строка сообщения всегда должна содержать HTTP-команду, называемую методом, за которой следует URI, идентифицирующий файл или ресурс, запрашиваемый клиентом, и номер версии HTTP:
GET /default.aspx HTTP/1.1
Теперь исследуем каждую из этих секций. Метод — это HTTP-команда, начинающая первую строку запроса клиента. Метод информирует сервер о цели запроса клиента. Для HTTP определены семь методов: GET, HEAD, POST, OPTIONS, PUT, DELETE и TRACE, но HTTP-серверы могут также реализовать методы расширения, не определенные протоколом HTTP. Заметим, что названия методов зависят от регистра клавиатуры, поэтому, например, слово get не будет распознано как допустимый метод.
Метод GET используется для запроса информации, расположение которой на сервере определяется заданным URI. Этот метод широко применяется браузерами, чтобы извлекать документы для просмотра. Результат запроса GET генерируется разными способами. Это может быть файл, доступный с сервера, вывод программы, вывод, полученный на устройстве, и т. д.
Когда клиент в своем запросе использует метод GET, сервер отправляет ответ, содержащий строку состояния, заголовки и метаданные. Если сервер не может обработать запрос из-за ошибки или отсутствия авторизации, он отправляет объяснение в текстовом виде, помещая его в ответе в секцию данных.
Секция тела о сути запроса GET всегда остается пустой. Запрошенный клиентом ресурс (файл или программа) идентифицируется по его полному пути на сервере. Любая дополнительная информация, например, значения из формы, которую клиенту нужно отправить серверу, присоединяется вслед за URI как строка запроса:
GET /default.aspx?name=Alex HTTP/1.1
Метод HEAD функционально аналогичен методу GET, не считая того, что сервер ничего не помещает в секцию данных ответа. Методом HEAD запрашивается только заголовочная информация по файлу или ресурсу. Для запроса HEAD HTTP-сервер должен отправить в заголовках ту же информацию, которую он бы отправил в ответ на запрос GET. Данный метод используется, если клиенту нужна информация о документе, но не нужно получать сам документ.
Метод POST позволяет отправить данные серверу в клиентском запросе. Эти данные посылаются программе обработки данных, к которой у сервера есть доступ. Метод POST может использоваться для многих приложений, например, для обеспечения входных данных сетевых служб, программ интерфейса командной строки и т.д. Данные отправляются на сервер в секции тела сути клиентского запроса. Обработав запрос POST и заголовки, сервер передает это тело программе, указанной в URI.
В методе OPTIONS запрашивается информация о поддержке HTTP на Web-cepвeре. Метод OPTIONS может применяться с URL, чтобы извлечь информацию о конкретном документе или, с групповым символом *, чтобы получить информацию о возможностях сервера в целом. Информация возвращается в заголовках ответа.
Коды состояния
В ответ на запрос от клиента, сервер отправляет ответ, который содержит, в том числе, и код состояния. Данный код несёт в себе особый смысл для того, чтобы клиент мог отчётливей понять, как интерпретировать ответ:
1xx: Информационные сообщения
Набор этих кодов был введён в HTTP/1.1. Сервер может отправить запрос вида: Expect: 100-continue, что означает, что клиент ещё отправляет оставшуюся часть запроса. Клиенты, работающие с HTTP/1.0 игнорируют данные заголовки.
2xx: Сообщения об успехе
Если клиент получил код из серии 2xx, то запрос ушёл успешно. Самый распространённый вариант — это 200 OK. При GET запросе, сервер отправляет ответ в теле сообщения. Также существуют и другие возможные ответы:
- 202 Accepted: запрос принят, но может не содержать ресурс в ответе. Это полезно для асинхронных запросов на стороне сервера. Сервер определяет, отправить ресурс или нет.
- 204 No Content: в теле ответа нет сообщения.
- 205 Reset Content: указание серверу о сбросе представления документа.
- 206 Partial Content: ответ содержит только часть контента. В дополнительных заголовках определяется общая длина контента и другая инфа.
3xx: Перенаправление
Своеобразное сообщение клиенту о необходимости совершить ещё одно действие. Самый распространённый вариант применения: перенаправить клиент на другой адрес.
- 301 Moved Permanently: ресурс теперь можно найти по другому URL адресу.
- 303 See Other: ресурс временно можно найти по другому URL адресу. Заголовок Location содержит временный URL.
- 304 Not Modified: сервер определяет, что ресурс не был изменён и клиенту нужно задействовать закэшированную версию ответа. Для проверки идентичности информации используется ETag (хэш Сущности — Enttity Tag);
4xx: Клиентские ошибки
Данный класс сообщений используется сервером, если он решил, что запрос был отправлен с ошибкой. Наиболее распространённый код: 404 Not Found. Это означает, что ресурс не найден на сервере. Другие возможные коды:
- 400 Bad Request: вопрос был сформирован неверно.
- 401 Unauthorized: для совершения запроса нужна аутентификация. Информация передаётся через заголовок Authorization.
- 403 Forbidden: сервер не открыл доступ к ресурсу.
- 405 Method Not Allowed: неверный HTTP метод был задействован для того, чтобы получить доступ к ресурсу.
- 409 Conflict: сервер не может до конца обработать запрос, т.к. пытается изменить более новую версию ресурса. Это часто происходит при PUT запросах.
5xx: Ошибки сервера
Ряд кодов, которые используются для определения ошибки сервера при обработке запроса. Самый распространённый: 500 Internal Server Error. Другие варианты:
- 501 Not Implemented: сервер не поддерживает запрашиваемую функциональность.
- 503 Service Unavailable: это может случиться, если на сервере произошла ошибка или он перегружен. Обычно в этом случае, сервер не отвечает, а время, данное на ответ, истекает.
3.1 Content-Type: application/x-www-form-urlencoded.
Пишем запрос, аналогичный нашему запросу GET для передачи логина и пароля, который был рассмотрен в предыдущей главе:
POST http://www.site.ru/news.html HTTP/1.0\r\n Host: www.site.ru\r\n Referer: http://www.site.ru/index.html\r\n Cookie: income=1\r\n Content-Type: application/x-www-form-urlencoded\r\n Content-Length: 35\r\n \r\n login=Petya%20Vasechkin&password=qq
Здесь мы видим пример использования Content-Type и Content-Length полей заголовка. Content-Length говорит, сколько байт будет занимать область данных, которая отделяется от заголовка еще одним переводом строки \r\n. А вот параметры, которые раньше для запроса GET помещались в Request-URI, теперь находятся в Entity-Body. Видно, что они формируются точно также, просто надо написать их после заголовка. Хочу отметить еще один важный момент, ничто не мешает, одновременно с набором параметров в Entity-Body, помещать параметры с другими именами в Request-URI, например:
POST http://www.site.ru/news.html?type=user HTTP/1.0\r\n ..... \r\n login=Petya%20Vasechkin&password=qq
Основы
XMLHttpRequest имеет два режима работы: синхронный и асинхронный.
Сначала рассмотрим асинхронный, так как в большинстве случаев используется именно он.
Чтобы сделать запрос, нам нужно выполнить три шага:
-
Создать .
-
Инициализировать его.
Этот метод обычно вызывается сразу после . В него передаются основные параметры запроса:
- – HTTP-метод. Обычно это или .
- – URL, куда отправляется запрос: строка, может быть и объект URL.
- – если указать , тогда запрос будет выполнен синхронно, это мы рассмотрим чуть позже.
- , – логин и пароль для базовой HTTP-авторизации (если требуется).
Заметим, что вызов , вопреки своему названию, не открывает соединение. Он лишь конфигурирует запрос, но непосредственно отсылается запрос только лишь после вызова .
-
Послать запрос.
Этот метод устанавливает соединение и отсылает запрос к серверу. Необязательный параметр содержит тело запроса.
Некоторые типы запросов, такие как , не имеют тела. А некоторые, как, например, , используют , чтобы отправлять данные на сервер. Мы позже увидим примеры.
-
Слушать события на , чтобы получить ответ.
Три наиболее используемых события:
- – происходит, когда получен какой-либо ответ, включая ответы с HTTP-ошибкой, например 404.
- – когда запрос не может быть выполнен, например, нет соединения или невалидный URL.
- – происходит периодически во время загрузки ответа, сообщает о прогрессе.
Вот полный пример. Код ниже загружает с сервера и сообщает о прогрессе:
После ответа сервера мы можем получить результат запроса в следующих свойствах :
- Код состояния HTTP (число): , , и так далее, может быть в случае, если ошибка не связана с HTTP.
- Сообщение о состоянии ответа HTTP (строка): обычно для , для , для , и так далее.
- (в старом коде может встречаться как )
- Тело ответа сервера.
Мы можем также указать таймаут – промежуток времени, который мы готовы ждать ответ:
Если запрос не успевает выполниться в установленное время, то он прерывается, и происходит событие .
URL с параметрами
Чтобы добавить к URL параметры, вида , и корректно закодировать их, можно использовать объект URL: