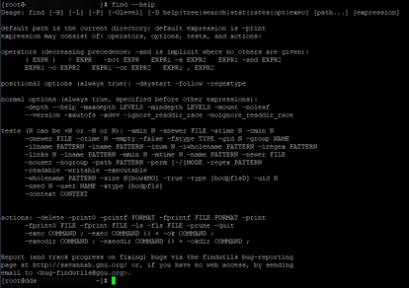
Утилита grep в ос linux
Содержание:
- 4.2.1. What is grep?
- файлами с Работа
- Поиск через графический интерфейс
- Применение grep в Linux
- файлов grep и регулярные выражения
- Grep IP-адреса
- What is grep?
- Выражения в квадратных скобках и Классы символов
- Регулярные выражения Linux
- Команда grep без аргумента и опций.
- Параметры grep
- msggrep, mboxgrep
- Other options
4.2.1. What is grep?
grep searches the input files for lines containing a match to a given pattern list. When it finds a match in a line, it copies the line to standard output (by default), or whatever other sort of output you have requested with options.
Though grep expects to do the matching on text, it has no limits on input line length other than available memory, and it can match arbitrary characters within a line. If the final byte of an input file is not a newline, grep silently supplies one. Since newline is also a separator for the list of patterns, there is no way to match newline characters in a text.
Some examples:
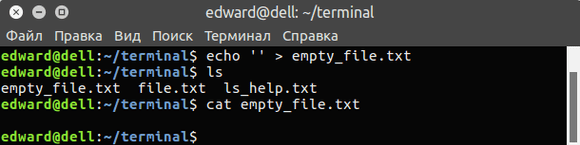
cathy ~> grep root /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin cathy ~> grep -n root /etc/passwd 1:root:x:0:0:root:/root:/bin/bash 12:operator:x:11:0:operator:/root:/sbin/nologin cathy ~> grep -v bash /etc/passwd | grep -v nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt news:x:9:13:news:/var/spool/news: mailnull:x:47:47::/var/spool/mqueue:/dev/null xfs:x:43:43:X Font Server:/etc/X11/fs:/bin/false rpc:x:32:32:Portmapper RPC user:/:/bin/false nscd:x:28:28:NSCD Daemon:/:/bin/false named:x:25:25:Named:/var/named:/bin/false squid:x:23:23::/var/spool/squid:/dev/null ldap:x:55:55:LDAP User:/var/lib/ldap:/bin/false apache:x:48:48:Apache:/var/www:/bin/false cathy ~> grep -c false /etc/passwd 7 cathy ~> grep -i ps ~/.bash* | grep -v history /home/cathy/.bashrc:PS1="\$USER is in \w\ " |
With the first command, user cathy displays the lines from /etc/passwd containing the string root.
Then she displays the line numbers containing this search string.
With the third command she checks which users are not using bash, but accounts with the nologin shell are not displayed.
Then she counts the number of accounts that have /bin/false as the shell.
The last command displays the lines from all the files in her home directory starting with ~/.bash, excluding matches containing the string history, so as to exclude matches from ~/.bash_history which might contain the same string, in upper or lower cases. Note that the search is for the string «ps», and not for the command ps.
файлами с Работа
Команда grep может обрабатывать количество любое файлов
одновременно. Создадим три 123:
файла.txt: alice.txt: ast.1234:
txt Алиса очень Символ астериска
красивая 5678 девочка, обозначается (*)
89*0 у нее такая ****** длинная.
звездочкой коса!
И дадим команду:
grep '*' txt.123 ast.txt alice.txt txt.123:89*0 ast.txt:обозначается (*). alice.нее:у txt такая ******
В выводе перечислены файлы, и каком, в указано из них какая
строка содержит астериска символ. ОБРАЗЕЦ (*) пришлось взять в
кавычки, командный чтобы интерпретатор понял, что имеется в символ
виду, а не условный знак. Попробуйте без увидите, кавычек —
ничего не получится.
Команда grep ограничена не вовсе одним выражением в качестве
ОБРАЗЦА, задавать можно хоть целые фразы. Только их заключать нужно
в кавычки (одинарные или двойные):
ная 'grep ко' 123.txt ast.txt txt.alice alice.txt:длинная коса!
поиска Возможности при помощи команды grep быть могут
значительно расширены применением групповых Например. символов, уже
упоминавшийся астериск (звездочка) для используется представления
любого символа или символов группы, если речь идет о тексте, и
файла любого или группы файлов, если идет речь о директории.
Создадим директорию /example, в поместим которую файлы наших
примеров: 123.ast, txt.txt, alice.txt и дадим grep:
команду '*' example/* example/123.txt:89*0 alice/example.txt:у нее такая ****** example/txt.ast:обозначается (*)
То есть мы приказали просмотреть файлы все директории /example.
Таким способом обследовать можно такие огромные директории как
/dev, /usr, и любые другие.
Поиск через графический интерфейс
Главное меню
С помощью главного меню ОС вы можете не только искать и запускать программы, но также и выполнять поиск файлов. Подобный функционал присутствует во многих окружениях рабочего стола (, , и пр.). Например, в KDE это представлено следующим образом:

При этом стоит отметить, что такой вариант поиска ориентирован больше на поиск программ, нежели на поиск файлов, поэтому выполняется он только в домашнем каталоге и не уходит вглубь файловой системы.
Файловые менеджеры
Многие файловые менеджеры также предоставляют возможности поиска файлов. Например, в Dolphin для запуска поиска достаточно просто нажать кнопку со значком лупы, а затем ввести имя файла (или папки) в строку поиска. При этом вы можете выбрать папку, в которой будет выполняться поиск, а также указать дополнительные параметры (поиск по содержимому и пр.). Помимо этого в качестве поискового запроса допускается применять символы и :

Поиск по содержимому в Dolphin:

KFind
В KDE, помимо вышеупомянутых инструментов поиска, также есть замечательная утилита под названием KFind. С её помощью вы можете точно настроить параметры поиска (указать имя файла, его тип и путь поиска, обычный текстовый поиск или мета-поиск, дату изменения, размер, пользователя, группу и пр.). Она также позволяет сохранять результаты поиска в виде простого текстового списка URL-адресов найденных файлов:

SearchMonkey
SearchMonkey позволяет выполнять поиск файла, как по имени, так и по его содержимому, по диапазону дат и пр. Но главное преимущество SearchMonkey — это возможность везде применять регулярные выражения.

Поиск с применением регулярного выражения в SearchMonkey:

Recoll
Recoll — это приложение (поисковый движок) для полнотекстового поиска, выполняющее поиск ваших данных по содержимому, а не по внешним атрибутам (например, по имени файла). Вам не нужно запоминать, в каком файле или сообщении электронной почты вы хранили ту или иную информацию. Необходимо лишь указать слова (или выражения), которые должны или не должны присутствовать в искомом тексте, и взамен вы получите список соответствующих документов, упорядоченных таким образом, что первыми идут наиболее релевантные из них (подобно поисковым системам Интернета).
Установить программу можно из официальных репозиториев через командную строку:
Или через графический интерфейс:

Сразу же после запуска утилита предложит вам создать индекс документов, которые присутствуют в вашем домашнем каталоге. После создания индекса вы сможете выполнять по нему поиск. Для этого достаточно ввести какой-нибудь запрос, например, , и вы увидите все файлы, которые содержат это слово с примерами вхождений, отсортированные по релевантности:

Это может быть очень удобно при работе с большим объемом текстовых данных. Программа поддерживает такие форматы файлов, как: .pdf, .djvu, .doc, .docx, .odf. А также умеет находить перечисленные файлы в архивах.
Применение grep в Linux
Одна из более полезных и многофункциональных команд в терминале Linux – бригада «grep». Grep – это акроним, какой расшифровывается как «global regular expression print» (то имеется, «искать везде соответствующие постоянному выражению строки и выводить их»).
Это значит, что grep возможно использовать для того, чтобы проглядеть, соответствуют ли вводимые данные заданным шаблонам. В простенькой форме grep используется для розыска совпадений буквенных шаблонов в текстовом файле. Это значивает, что если команда grep приобретает слово для поиска, она будет выводить каждую сохраняющую это слово строку файла.
Назначение grep — поиск строк согласно условию, изображенному регулярным выражением. Существуют изменения классического grep — egrep, fgrep, rgrep. Все они отточены под конкретные цели, при этом способности grep перекрывают весь функционал. Самым несложным примером использования команды представляется вывод строки, удовлетворяющей шаблону, из файла. Пример мы хотим найти строку, сохраняющую ‘user’ в файле /etc/mysql/my.cnf. Для этого воспользуемся последующей командой:
Grep сможет просто искать конкретное словечко:
Или строку, но в таком варианте её нужно заключать в кавычки:
В добавление альтернативами программы являются egrep и fgrep, которые являются тем же самым, что и, соответственно, grep -E и grep -F. Варианты egrep и fgrep являются устаревшими, но работают для обратной совместимости. Вместо устаревших вариантов рекомендуется использовать grep -E и grep –F.
Команда grep сопоставляет строки исходных файлов с шаблоном, этим базовым регулярным выражением. Если файлы не указаны, используется стандартный ввод. Как как обычно каждая успешно сопоставленная строка копируется на стандартный вывод; если исходных файлов чуть-чуть, перед найденной строкой выдается имя файла. В качестве шаблонов воспринимаются базовые непрерывные выражения (выражения, имеющие своими значениями цепочки символов, и использующие ограниченный комплекс алфавитно-цифровых и специальных символов).
файлов grep и регулярные выражения
Регулярные Regular (выражения Expressions) это система
синтаксического текстовых разбора фрагментов по формализованному
шаблону, основанная на записи системе ОБРАЗЦОВ для поиска. Проще
регулярное, говоря выражение — тот же, уже привычный ОБРАЗЕЦ нам
для поиска, только составленный по правилам определенным. Как
математические формулы составляются помощи при набора операторов
(плюс, минус, корень, степень и прочее), так и регулярные выражения
при конструируются помощи различных операторов (?, *, +, {n} и
прочие).
регулярных Тема выражений настолько обширна, что для требует
своего освещения отдельной статьи; в статье данной мы не будем ее
подробно разбирать. Скажу что, лишь существует несколько версий
синтаксиса выражений регулярных: Базовый (basic) BRE, Расширенный
(ERE) extended и регулярные выражения языка Perl.
—Опция-regexp
Рассматривает ОБРАЗЕЦ как регулярное базовое выражение. Эта
опция используется по Опция.
—extended-regexp
Рассматривает ОБРАЗЕЦ расширенное как регулярное выражение.
—perl-Рассматривает
regexp ОБРАЗЕЦ как регулярное выражение Perl языка.
Опция -F
—fixed-strings
Рассматривает как ОБРАЗЕЦ список «фиксированных выражений»
(fixed термин — strings из области регулярных выражений),
разделенных новой символами строки. Будет искать соответствия
них из любому.
Кроме того, существуют две команды альтернативные EGREP и FGREP.
Обе они опциям соответствуют -E и -F соответственно.
Опции —help и —version (-V) буду, и я не общеизвестны на них
останавливаться.
Grep IP-адреса
Greping для IP-адресов может быть немного сложным, потому что мы не можем просто сказать, что grep ищет 4 числа, разделенных точками — ну, мы могли бы, но эта команда также может вернуть недопустимые IP-адреса.
Следующая команда найдет и изолирует только действительные адреса IPv4 :
$ grep -E -o "(25|2|??)\.(25|2|??)\.(25|2|??)\.(25|2|??)" /var/log/auth.log
Мы использовали это на нашем сервере Ubuntu только для того, чтобы увидеть, откуда были сделаны последние попытки SSH.
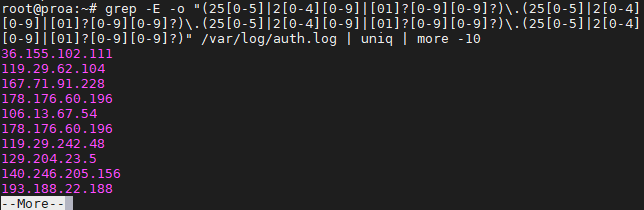
Чтобы избежать повторной информации и захламления вашего экрана, вы можете направить ваши команды grep в «uniq» и «more», как мы делали на скриншоте выше.
What is grep?
The grep utility that we will be getting a hold of today is a Unix tool that belongs to the same family as the egrep and fgrep utilities. These are all Unix tools designed for performing the repetitive searching task on your files and text. You can search for files and their contents for useful information fetching by specifying particular search criteria through the grep command.
So they say GREP stands for Global Regular Expression Print but where does this command ‘grep’ originate from? grep basically derives from a specific command for the very simple and venerable Unix text editor named ed. This is how the ed command goes:
g/re/p
The purpose of the command is pretty similar to what we mean by searching through grep. This command fetches all the lines in a file matching a certain text pattern.
Let us explore the grep command some more. In this article, we will explain the installation of the grep utility and present some examples through which you can learn exactly how and in which scenario you can use it.
We have run the commands and procedures mentioned in this article on an Ubuntu 18.04 LTS system.
Выражения в квадратных скобках и Классы символов
В дополнение к совпадению любого символа в заданной позиции в нашем регулярном выражении, мы также, используя выражения в квадратных скобках, можем задать совпадение единичного символа из указанного набора символов. С выражениями в квадратных скобках мы можем указать набор символов для соответствия (включая символы, которые в противном случае были бы истолкованы как метасимволы). В этом примере, используя набор из двух символов:
grep -h 'zip' dirlist*.txt bzip2 bzip2recover gzip

мы найдём любые строчки, содержащие строки «bzip» или «gzip».
Набор может содержать любое количество символов, а метасимволы теряют своё специальное значение, когда помещаются внутрь квадратных скобок. Тем не менее, есть два случая в которых метасимволы, используемые внутри квадратных скобок, имеют различные значения. Первый – это каретка (^), которая используется для указания отрицания; второй – это тире (-), которое используется для указания диапазона символов.
Отрицание
Если первым символом выражения в квадратных скобках является каретка (^), то остальные символы принимаются как набор символов, которые не должны присутствовать в заданной позиции символа. Сделаем это изменив наш предыдущий пример:
grep -h 'zip' dirlist*.txt bunzip2 gunzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin unzip unzipsfx
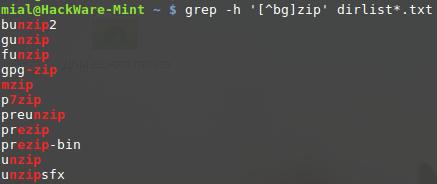
С активированным отрицанием, мы получили список файлов, которые содержат строку «zip», перед которой идёт любой символ, кроме «b» или «g»
Обратите внимание, что zip не был найден. Отрицаемый набор символов всё равно требует символ на заданной позиции, но символ не должен быть членом инвертированного набора.
Символ каретки вызывает отрицание только если он является первым символом внутри выражения в квадратных скобках; в противном случае, он теряет своё специальное назначение и становится обычным символом из набора.
Традиционные диапазоны символов
Если мы хотим сконструировать регулярное выражение, которое должно найти каждый файл из нашего списка, начинающийся на заглавную букву, мы можем сделать следующее:
grep -h '^' dirlist*.txt MAKEDEV GET HEAD POST VBoxClient X X11 Xorg ModemManager NetworkManager VBoxControl VBoxService
Суть в том, что мы разместили все 26 заглавных букв в выражение внутри квадратных скобок. Но мысль печатать их все не вызывает энтузиазма, поэтому есть другой путь:
grep -h '^' dirlist*.txt
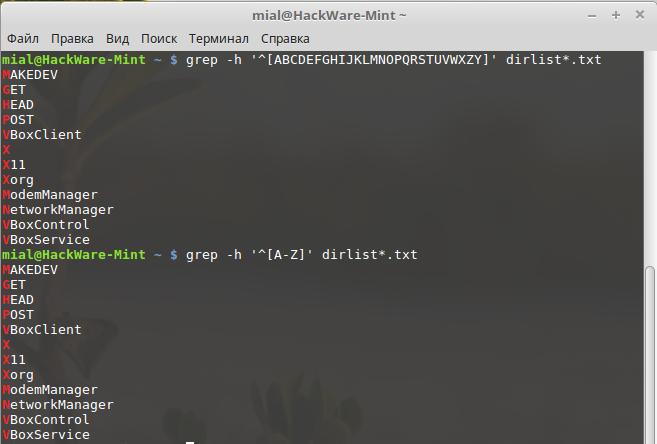
Используя трёхсимвольный диапазон, мы можем сократить запись из 26 букв. Таким способом можно выразить любой диапазон символов, включая сразу несколько диапазонов, такие, как это выражение, которое соответствует всем именам файлов, начинающихся с букв и цифр:
grep -h '^' dirlist*.txt
В диапазонах символов мы видим, что символ чёрточки трактуется особым образом, поэтому как мы можем включить символ тире в выражение внутри квадратных скобок? Сделав его первым символом в выражении. Рассмотрим два примера:
grep -h '' dirlist*.txt
Это будет соответствовать каждому имени файла, содержащему заглавную букву. При этом:
grep -h '' dirlist*.txt
будет соответствовать каждому имени файла, содержащему тире, или заглавную «A», или заглавную «Z».
Классы символов POSIX
Подробнее о POSIX вы можете почитать в Википедии.
В POSIX имеются свои классы символов, которые вы можете использовать в регулярных выражениях:
| Класс символов | Описание |
|---|---|
| Алфавитно-цифровые символы. В ASCII эквивалентно: | |
| То же самое, что и , с дополнительным символом подчёркивания (_). | |
| Алфавитные символы. В ASCII эквивалентно: | |
| Включает символы пробела и табуляции. | |
| Управляющие коды ASCII. Включает ASCII символы с 0 до 31 и 127. | |
| Цифры от нуля до девяти. | |
| Видимые символы. В ASCII сюда включены символы с 33 по 126. | |
| Буквы в нижнем регистре. | |
| Символы пунктуации. В ASCII эквивалентно: [-!»#$%&'()*+,./:;?@_`{|}~] | |
| Печатные символы. Все символы в плюс символ пробела. | |
| Символы белых пробелов, включающих пробел, табуляцию, возврат каретки, новую строку, вертикальную табуляцию и разрыв страницы. В ASCII эквивалентно: | |
| Символы в верхнем регистре. | |
| Символы, используемые для выражения шестнадцатеричных чисел. В ASCII эквивалетно: |
В этих выражениях квадратные скобки и двоеточия являются частью записи класса символов (диапазонов).
Внимание: в зависимости от настроек локали, , , и другие буквенные диапазоны могут включать буквы вашего алфавита, например, русского. Т.е
может соответствовать не , а .
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
- обычные буквы;
- метасимволы.
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- {n} — указывает сколько раз (n) нужно повторить предыдущий символ;
- {N,n} — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- — любой символ, кроме тех, что указаны в скобках;
- — любой символ из указанного диапазона;
- — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Команда grep без аргумента и опций.
Если не указано имени файла, то обрабатывает команда стандартный
ввод, например строки, клавиатуре на набранные:
grep кот у меня есть Enter,(кошка) вернее это кот,(Enter) это вернее кот, который умеет(Enter) умеет который ловить мышей.(Enter) (Ctrl+c)
В показано скобках, когда я нажимал клавишу Enter, перейти чтобы
на новую строку. Одновременно, при Enter нажатии, программа
выводила строки, содержащие кот (ОБРАЗЕЦ), отсюда и удвоение этих
строк. что, Видно команда реагировала просто на сочетание слово, а
не на букв «кот», иначе строка со словом «попала» не который бы в
вывод.
Тут мы подошли к очень определению важному строки. Строкой
команда grep (все и как остальные команды Юникс) считает символы
все, находящиеся между двумя символами строки новой
Эти
невидимые на экране символы тексте в возникают каждый раз, когда
пользователь клавишу нажимает Enter. В Юниксовидных системах символ
строки новой обозначается обратным слэшем с буквой n (\n). образом
Таким, строка может быть любого начиная, размера с одного символа
и до многомегабайтного текста. И grep команда честно выведет эту
строку, условии при, что она содержит ОБРАЗЕЦ.
Параметры grep
Опция -r
—recursive
Еще больше увеличит зону поисков опция -r, которая заставит команду grep рекурсивно обследовать все дерево указанной директории, то есть субдиректории, субдиректории субдиректорий, и так далее вплоть до файлов. Например:
grep -r menu /boot /boot/grub/grub.txt:Highlight the menu entry you want to edit and press 'e', then
/boot/grub/grub.txt:Press the key to return to the GRUB menu.
/boot/grub/menu.lst:# GRUB configuration file ‘/boot/grub/menu.lst’.
/boot/grub/menu.lst:gfxmenu (hd0,3)/boot/message
Опция -i
—ignore-case
Приказывает команде игнорировать регистр символов, таким образом, поиск будет производиться как среди заглавных, так и среди строчных букв.
Опция -c
—count
Эта опция не выводит строки, а подсчитывает количество строк, в которых обнаружен ОБРАЗЕЦ. Например:
grep -c root /etc/group 8
То есть в восьми строках файла /etc/group встречается сочетание символов root.
—line-number
При использовании этой опции вывод команды grep будет указывать номера строк, содержащих ОБРАЗЕЦ:
Опция -v
—invert-match
Выполняет работу, обратную обычной — выводит строки, в которых ОБРАЗЕЦ не встречается:
grep -v print /etc/printcap # # # for you (at least initially), such as apsfilter # (/usr/share/apsfilter/SETUP, used in conjunction with the # LPRng lpd daemon), or with the web interface provided by the # (if you use CUPS).
Опция -w
—word-regexp
Заставит команду grep искать только строки, содержащие все слово или фразу, составляющую ОБРАЗЕЦ. Например:
grep -w "длинная ко" example/*
Не дает вывода, то есть не находит строк, содержащих выражение «длинная ко». А вот команда:
grep -w "длинная коса" example/* example/alice.txt:длинная коса!
находит точное соответствие в файле alice.txt.
Опция -x
—line-regexp
Еще более строгая. Она отберет только те строки исследуемого файла или файлов, которые полностью совпадают с ОБРАЗЦОМ.
grep -x "1234" example/* example/123.txt:1234
Внимание: Мне попадались (на собственном компьютере) версии grep (например, GNU 2.5), в которых опция -x работала неадекватно. В то же время, другие версии (GNU 2.5.1) работали прекрасно
Если что-то не ладится с этой опцией, попробуйте другую версию, или обновите свою.
Опция -l
—files-with-matches
Команда grep с этой опцией не возвращает строки, содержащие ОБРАЗЕЦ, но сообщает лишь имена файлов, в которых данный образец найден:
grep -l 'Алиса' example/* example/alice.txt
Замечу, что сканирование каждого из заданных файлов продолжается только до первого совпадения с ОБРАЗЦОМ.
Опция -L
—files-without-match
Наоборот, сообщает имена тех файлов, где не встретился ОБРАЗЕЦ:
grep -L 'Алиса' example/* example/123.txt example/ast.txt
Как мы имели случай заметить, команда grep, в поисках соответствия ОБРАЗЦУ, просматривает только содержимое файлов, но не их имена. А так часто нужно найти файл по его имени или другим параметрам, например времени модификации! Тут нам придет на помощь простейший программный канал (pipe). При помощи знака программного канала — вертикальной черты (|) мы можем направить вывод команды ls, то есть список файлов в текущей директории, на ввод команды grep, не забыв указать, что мы, собственно, ищем (ОБРАЗЕЦ). Например:
ls | grep grep grep/ grep-ru.txt
Находясь в директории Desktop, мы «попросили» найти на Рабочем столе все файлы, в названии которых есть выражение «grep». И нашли одну директорию grep/ и текстовой файл grep-ru.txt, который я в данный момент и пишу.
Если мы хотим искать по другим параметрам файла, а не по его имени, то следует применить команду ls -l, которая выводит файлы со всеми параметрами:
ls -l | grep 2008-12-30 -rw-r--r-- 1 ya users 27 2008-12-30 08:06 123.txt drwxr-xr-x 2 ya users 4096 2008-12-30 08:49 example/ -rw-r--r-- 1 ya users 11931 2008-12-30 14:59 grep-ru.txt
И вот мы получили список всех файлов, модифицированных 30 декабря 2008 года.
Команда grep незаменима при просмотре логов и конфигурационных файлов. Классически примером использования команды grep стал программный канал с командой dmesg. Команда dmesg выводит те самые сообщения ядра, которые мы не успеваем прочесть во время загрузки компьютера. Допустим, мы подключили через USB порт новый принтер, и теперь хотим узнать, как ядро «окрестило» его. Дадим такую команду:
dmesg | grep -i usb
Опция -i необходима, так как usb часто пишется заглавными буквами. Проделайте этот пример самостоятельно — у него длинный вывод, который не укладывается в рамки данной статьи.
msggrep, mboxgrep
Это совсем уже узко специализированная штуковина, чтобы парсить каталоги локализации. Идет в комплекте с пакетом gettext. Программа не из разряда пользовательских, но если очень нужно, можно запустить с командной строки.
Следующий экспонат — парсер почтовых ящиков mboxgrep. Проект так и не взлетел, его разработка прекращена. По идее он должен был находить паттерны в письмах и обрабатывать вывод так как будто это отдельные файлы. Однако, для начала он эти паттерны должен уметь находить.
А он не находит.
Что странно, системные вызовы все время одни и те же, вне зависимости от поиска.
Любопытно было бы узнать, завелась ли данная программа успешно у кого-нибудь?
Ну ладно, мы увлеклись, а греп семейство еще не инвентаризировано полностью.
Other options
| —line-buffered | Use line buffering on output. This can cause a performance penalty. |
| —mmap | If possible, use the mmap system call to read input, instead of the default read system call. In some situations, —mmap yields better performance. However, —mmap can cause undefined behavior (including core dumps) if an input file shrinks while grep is operating, or if an I/O error occurs. |
| -U, —binary | Treat the file(s) as binary. By default, under MS-DOS and MS-Windows, grep guesses the file type by looking at the contents of the first 32 KB read from the file. If grep decides the file is a text file, it strips the CR characters from the original file contents (to make regular expressions with ^ and $ work correctly). Specifying -U overrules this guesswork, causing all files to be read and passed to the matching mechanism verbatim; if the file is a text file with CR/LF pairs at the end of each line, this causes some regular expressions to fail. This option has no effect on platforms other than MS-DOS and MS-Windows. |
| -z, —null-data | Treat the input as a set of lines, each terminated by a zero byte (the ASCII NUL character) instead of a newline. Like the -Z or —null option, this option can be used with commands like sort -z to process arbitrary file names. |