Data scientist (специалист по обработке, анализу и хранению больших массивов данных)
Содержание:
- Необходимые базовые навыки
- Образование. Шесть шагов на пути к Data Scientist
- Программирование: что и как учить?
- Большие данные
- Нейросетевая игра в имитацию
- Визуализация данных
- Как работают эксперты по аналитическим данным в лаборатории Philips Research
- Data Scientist: кто это и что он делает
- Работа data сайентистом
- *2020: Академия больших данных MADE и HeadHunter выяснили, как меняется спрос на Data Scientist в России
- Этап 6
- Соберем данные
Необходимые базовые навыки
Знание основ программирования: Python и SQL
Невозможно заниматься машинным обучением или data science не владея программированием в Python или R (Начинать лучше с Python). Также, подавляющее большинство вакансий в «классическом» машинном обучении (решение бизнес-задач, и работа с изначально числовыми/статистическими данными) потребует знание SQL. Базовые рекомендации по их изучению есть в статье Самообучение в Data science, с нуля до Senior за два года.
Математика
Также невозможно стать хорошим специалистом без достаточного уровня математики. Но, мне кажется, эффективнее изучать математику постепенно, предварительно знакомясь с теми целями в которых она применяется.
Тем не менее, есть определенный минимально-необходимый базовый уровень: понимание производных (школьная программа алгебры), понимание градиентного спуска (градиент, обычно, объясняют в начальных курсах математического анализа в университете, и объяснение есть также в курсах о машинном обучении), знания основ дискретной математики, теории вероятностей и статистики.
Основы теории вероятностей неплохо объяснены в специализации: . Необходимый минимум теории вероятностей дан в последнем курсе специализации, который не требует знаний из 2 и 3 курсов. Курсы 2 и 3 дают знания, полезные для понимания градиентного спуска и для изучения нейронных сетей и некоторых других методов машинного обучения. По указанным темам мне очень нравится англоязычная специализация .
Если у вас проблемы с пониманием производных и пределов (школьная программа, самые продвинутые её темы), то, если понимаете английский: крайне рекомендую все курсы от Robert Ghrist. Более интуитивное и наглядное объяснение математики я вообще не встречал. На русском поищите курсы на coursera.org, также неплохие бесплатные курсы по математике есть на stepik.org
Образование. Шесть шагов на пути к Data Scientist
Путь к этой профессии труден: невозможно овладеть всеми инструментами за месяц или даже год. Придётся постоянно учиться, делать маленькие шаги каждый день, ошибаться и пытаться вновь.
Шаг 1. Статистика, математика, линейная алгебра
Для серьезного понимания Data Science понадобится фундаментальный курс по теории вероятностей (математический анализ как необходимый инструмент в теории вероятностей), линейной алгебре и математической статистике.
Фундаментальные математические знания важны, чтобы анализировать результаты применения алгоритмов обработки данных. Сильные инженеры в машинном обучении без такого образования есть, но это скорее исключение.
Что почитать
«Элементы статистического обучения», Тревор Хасти, Роберт Тибширани и Джером Фридман — если после учебы в университете осталось много пробелов. Классические разделы машинного обучения представлены в терминах математической статистики со строгими математическими вычислениями.
«Глубокое обучение», Ян Гудфеллоу. Лучшая книга о математических принципах, лежащих в основе нейронных сетей.
«Нейронные сети и глубокое обучение», Майкл Нильсен. Для знакомства с основными принципами.
Полное руководство по математике и статистике для Data Science. Крутое и нескучное пошаговое руководство, которое поможет сориентироваться в математике и статистике.
Введение в статистику для Data Science поможет понять центральную предельную теорему. Оно охватывает генеральные совокупности, выборки и их распределение, содержит полезные видеоматериалы.
Полное руководство для начинающих по линейной алгебре для специалистов по анализу данных. Всё, что необходимо знать о линейной алгебре.
Линейная алгебра для Data Scientists. Интересная статья, знакомящая с основами линейной алгебры.
Шаг 2. Программирование
Большим преимуществом будет знакомство с основами программирования. Вы можете немного упростить себе задачу: начните изучать один язык и сосредоточьтесь на всех нюансах его синтаксиса.
При выборе языка обратите внимание на Python. Во-первых, он идеален для новичков, его синтаксис относительно прост. Во-вторых, Python многофункционален и востребован на рынке труда.
Что почитать
«Автоматизация рутинных задач с помощью Python: практическое руководство для начинающих». Практическое руководство для тех, кто учится с нуля. Достаточно прочесть главу «Манипулирование строками» и выполнить практические задания из нее.
Codecademy — здесь вы научитесь хорошему общему синтаксису.
Легкий способ выучить Python 3 — блестящий мануал, в котором объясняются основы.
Dataquest поможет освоить синтаксис.
The Python Tutorial — официальная документация.
После того, как изучите основы Python, познакомьтесь с основными библиотеками:
- Numpy : документация — руководство
- Scipy : документация — руководство
- Pandas : документация — руководство
Визуализация:
- Matplotlib : документация — руководство
- Seaborn : документация — руководство
Машинное обучение и глубокое обучение:
- SciKit-Learn: документация — руководство
- TensorFlow : документация — руководство
- Theano : документация — руководство
- Keras: документация — руководство
Обработка естественного языка:
NLTK — документация — руководство
Web scraping (Работа с web):
BeautifulSoup 4 — документация — руководство
Программирование: что и как учить?
Что такое SQL и зачем его учить?
SQL является стандартом для получения данных в нужном виде из разных баз данных. Это тоже своеобразный язык программирования, который дополнительно к своему основному языку используют многие программисты. Большинство самых разных баз данных использует один и тот же язык с относительно небольшими вариациями.
SQL простой, потому что он «декларативный»: нужно точно описать «запрос» как должен выглядеть финальный результат, и всё! — база данных сама покажет вам данные в нужной форме. В обычных «императивных» языках программирования нужно описывать шаги, как вы хотите чтобы компьютер выполнил вашу инструкцию. C SQL намного легче, потому что достаточно только точно понять что вы хотите получить на выходе.
Сам язык программирования — это ограниченный набор команд.
Когда вы будете работать с данными — даже аналитиком, даже необязательно со знанием data science, — самой первой задачей всегда будет получить данные из базы данных. Поэтому SQL надо знать всем. Даже веб-аналитики и маркетологи зачастую его используют.
Как учить SQL:
Наберите в Гугле «sql tutorial» и начните учиться по первой же ссылке. Если она вдруг окажется платной, выберете другую. По SQL полно качественных бесплатных курсов.
На русском языке тоже полно курсов. Выбирайте бесплатные.
Главное — выбирайте курсы, в которых вы можете сразу начать прямо в браузере пробовать писать простейшие запросы к данным. Только так, тренируясь на разных примерах, действительно можно выучить SQL.
На изучение достаточно всего лишь от 10 часов (общее понимание), до 20 часов (уверенное владение большей частью всего необходимого).
Почему именно Python?
В первую очередь, зачем учить Python. Возможно, вы слышали что R (другой популярный язык программирования) тоже умеет очень многое, и это действительно так. Но Python намного универсальнее. Мало сфер и мест работы, где Python вам не сможет заменить R, но в большинстве компаний, где Data Science можно делать с помощью Python, у вас возникнут проблемы при попытке использования R. Поэтому — точно учите Python. Если вы где-то услышите другое мнение, скорее всего, оно устарело на несколько лет (в 2015г было совершенно неясно какой язык перспективнее, но сейчас это уже очевидно).
У всех других языков программирования какие-либо специализированные библиотеки для машинного обучения есть только в зачаточном состоянии.
Как учить Python
Основы:
Прочитать основы и пройти все упражнения с этого сайта можно за 5-40 часов, в зависимости от вашего предыдущего опыта.
После этого варианты (все эти книги есть и на русском):
-
Learning Python, by Mark Lutz (5 издание). Существует и на русском.
Есть много книг, которые сразу обучают использованию языка в практических задачах, но не дают полного представления о детальных возможностях языка.
Эта книга, наоборот, разбирает Python досконально. Поэтому по началу её чтение будет идти медленнее, чем аналоги. Но зато, прочтя её, вы будете способны разобраться во всём.
Я прочёл её почти целиком в поездах в метро за месяц. А потом сразу был готов писать целые программы, потому что самые основы были заложены в pythontutor.ru, а эта книга детально разжевывает всё.
В качестве практики берите, что угодно, когда дочитаете эту книгу до 32 главы, и решайте реальные примеры (кстати, главы 21-31 не надо стараться с первого раза запоминать детально. Просто пробежите глазами, чтобы вы понимали что вообще Python умеет).
Не надо эту книгу (и никакую другую) стараться вызубрить и запомнить все детали сразу. Просто позже держите её под рукой и обращайтесь к ней при необходимости.
Прочитав эту книгу, и придя на первую работу с кучей опытных коллег, я обнаружил, что некоторые вещи знаю лучше них.
-
Python Crash Course, by Eric Matthes
Эта книга проще написана и отсеивает те вещи, которые всё-таки реже используются. Если вы не претендуете быстрее стать высоко-классным знатоком Python — её будет достаточно.
-
Automate the Boring Stuff with Python
Книга хороша примерами того, что можно делать с помощью Python. Рекомендую просмотреть их все, т.к. они уже похожи на реальные задачи, с которыми приходится сталкиваться на практике, в том числе специалисту по анализу данных.
Какие трудозатраты?
Путь с нуля до уровня владения Python, на котором я что-то уже мог, занял порядка 100ч. Через 200ч я уже чувствовал себя уверенно и мог работать над проектом вместе с коллегами.
(есть бесплатные программы — трекеры времени, некоторым это помогает для самоконтроля)
Большие данные
Начнём с простого — big data, или «большие данные». Это модный термин, обозначающий огромные массивы данных, которые накапливаются в каких-то больших системах.
Например, человек в Москве совершает 5-6 покупок по карте в день, это около 2 тысяч покупок в год. В стране таких людей, допустим, 80 миллионов. За год это 160 миллиардов покупок. Данные об этих покупках — биг дата.
В банках какой-то страны каждый день совершаются сотни тысяч операций: платежи, переводы, возвраты и так далее. Данные о них хранятся в центральном банке страны — это биг дата.
Ещё биг дата: данные о звонках и смс у мобильного оператора; данные о пассажиропотоке на общественном транспорте; связи между людьми в соцсетях, их лайки и предпочтения; посещённые сайты; данные о покупках в конкретном магазине (которые хранятся в их кассе); данные с шагомеров и тайм-трекеров; скачанные приложения; открытые вами файлы и программы… Короче, любой большой массив данных.
Почему появился такой термин: в конце девяностых компании в США стали понимать, что сидят на довольно больших массивах данных, с которыми непонятно что делать. И чем дальше — тем этих данных больше.
Раньше данные были, условно говоря, по кредитным картам, телефонным счетам и из профильных государственных ведомств; а теперь чем дальше — тем больше всего считается. Супермаркеты научились вести сверхточный учёт склада и продаж. Полиция научилась с высокой точностью следить за машинами на дороге. Появились смартфоны, и вообще вся человеческая жизнь стала оцифровываться.
И вот — данные вроде есть, а что с ними делать? Тут на сцену выходит дата-сайенс — дисциплина о больших данных.
Нейросетевая игра в имитацию
Здравствуйте, коллеги. В конце 1960-ых годов прошлого века Ричард Фейнман прочитал в Калтехе курс лекций по общей физике. Фейнман согласился прочитать свой курс ровно один раз. Университет понимал, что лекции станут историческим событием, взялся записывать все лекции и фотографировать все рисунки, которые Фейнман делал на доске. Может быть, именно после этого у университета осталась привычка фотографировать все доски, к которым прикасалась его рука. Фотография справа сделана в год смерти Фейнмана. В верхнем левом углу написано: «What I cannot create, I do not understand«. Это говорили себе не только физики, но и биологи. В 2011 году, Крейгом Вентером был создан первый в мире синтетический живой организм, т.е. ДНК этого организма создана человеком. Организм не очень большой, всего из одной клетки. Помимо всего того, что необходимо для воспроизводства программы жизнедеятельности, в ДНК были закодированы имена создателей, их электропочты, и цитата Ричарда Фейнмана (пусть и с ошибкой, ее кстати позже исправили). Хотите узнать, к чему эта прохладная тут? Приглашаю под кат, коллеги.
Визуализация данных
Визуализация данных может показаться чуть более понятной, чем другие темы. Тем не менее, в ней скрыто больше, чем кажется на первый взгляд. Давайте начнем с определения.
Распространено заблуждение, что привлекательный вид — наиболее важная часть визуализации
Это очень важно, но это не главная цель. Цель же в том, чтобы представить информацию, извлеченную из данных, наиболее доступным для восприятия способом
Согласно NeoMam Studios, цветные изображения на 80% увеличивают готовность читателя воспринимать информацию.
Распространенные типы визуализации
Посмотрим на некоторые часто используемые типы визуализации. Помните, что это далеко не полный список. Скорее это просто некоторые из наиболее распространенных двумерных визуализаций, которые мне встречались. Итак, пожалуйста:
Многомерные: это графики и диаграммы, оперирующие несколькими переменными; самая распространенная форма визуализации.Примеры: круговые диаграммы, гистограммы и диаграммы рассеяния.
Временные: используют время в качестве базовой линии для эффективного сообщения данных. Любая из них может быть мощным инструментом для представления изменений в течение определенного периода времени.Примеры: временные ряды, диаграммы Ганта и дуговые диаграммы.
Геопространственный: как можно предположить, геопространственные визуализации касаются местоположения. Они обычно используются для передачи информации о конкретной области или регионе.Примеры: карты распределения точек, карты пропорций символов и контурные карты.
Читать ещё: «Как визуализировать данные: типы графиков»
Ключевые моменты
Есть несколько ключевых моментов, которые относятся ко всем наиболее часто используемым типам визуализации данных. Ниже вы найдете список тех, что я считаю наиболее значимыми.
Информация: она должна быть точной и последовательной. Конечный результат не имеет значения, если данные неверны.
История: визуализация должна иметь смысл, отношение к проекту или обществу. Зачем делать визуализацию, если никто не захочет её видеть?
Польза: независимо от того, насколько сложна информация, с которой вы работаете, ваша задача — сделать ее краткой и понятной
Важно, чтобы данными могли пользоваться даже люди без технического бекграунда. На работе это особенно актуально
Привлекательность: наконец, визуализация должна быть в целом привлекательной
Она должна нравится и привлекать внимание. Для этого нужно принимать во внимание такие вещи, как баланс, цвет, согласованность, размер и многое другое
Значимость в Data Science
Навыки визуализации чрезвычайно полезны для специалистов в области данных, независимо от сферы. Возможность эффективно представлять данные в виде изображений, а не слов делает ваше сообщение более понятным и дает больше шансов произвести впечатление своей работой.
Что почитать
Из чего складывается хорошая визуализация данных (англ.) — отличная диаграмма Венна, объясняющая компоненты превосходной визуализации данных. Мы затрагивали некоторые из них выше, но я все же очень рекомендую посмотреть статью.Duke, введение в визуализацию (англ.): пройдитесь по всем типам визуализации данных на примере библиотек Университета Дьюка.Обсуждение визуализация данных на Quora (англ.): несколько хороших вопросов о визуализации данных для дополнительного чтения.
Как работают эксперты по аналитическим данным в лаборатории Philips Research
В лаборатории Philips Research каждый Data Scientist занимается разработками в рамках текущих проектов компании в сфере здравоохранения. Тематика разработок достаточно широкая, и заниматься в лаборатории можно чем угодно: распознаванием образов и обработкой изображений и текстов, предсказанием болезней, поиском аномалий, генеративными моделями и другими технологиями.
Один из приоритетов специалистов лабораторий Philips Research по всему миру — разработка инновационных подходов к медицинской визуализации. Учёные стремятся автоматизировать некоторые из задач врачей, деятельность которых связана с оценкой изображений, и внедряют ИИ (искуственный интеллект) в рентгенологию, МРТ, компьютерную томографию, патоморфологию.
Примером может послужить возможность создавать один вид изображения на основании другого — этому могут обучаться генеративные алгоритмы. Нейросети моделируют изображения на основании известной информации: мы знакомы с этой возможностью, по развлекательным мобильным приложениям, в которых можно создать «гибрид» двух людей по фотографиям.
В медицине это применимо, когда пациенту во время обследования требуется сразу две процедуры: компьютерная томография (КТ) и МРТ. При проведении КТ доза облучения пациента несколько выше, особенно когда необходимо хорошее разрешение. Чтобы снизить уровень лучевой нагрузки, особенно, если пациент — ребенок, ученые создали метод, который называется квази-КТ. Согласно ему обученная программа генерирует КТ на основе существующих МРТ. Пациент проходит одну процедуру вместо нескольких. Таким образом уменьшается время и стоимость обследования, а главное — доза облучения.
Среди направлений разработок Philips Research, не связанных с визуализацией, особенно перспективна прогнозная аналитика — предсказание заболеваний в зависимости от местности и группы населения. Если будут учитываться медицинские показатели миллионов человек, можно будет находить взаимосвязи и закономерности, выяснять, почему где-то одни заболевания распространены больше, чем другие, и затем на основании полученной информации определять группы риска и проводить профилактику до возникновения вспышек болезней.
Специалисты Philips Research принимают участие в разработке интеллектуальных систем, занимаются изобретательской деятельностью с последующим патентованием. К тому же специалисты проводят исследования, экспериментируют с данными и оформляют свои результаты в виде научных статей и выступают с докладами на ведущих мировых конференциях в сфере искусственного интеллекта, таких как MICCAI, MIDL, ACPR.
Data Scientist на сегодня — одна из самых быстроразвивающихся профессий, которая позволяет претворять в жизнь то, что раньше казалось нереальным. Спрос на специалистов в области данных велик и продолжает расти, а возможности для развития практически безграничны.
Data Scientist: кто это и что он делает
В переводе с английского Data Scientist – это специалист по данным. Он работает с Big Data или большими массивами данных.
Источники этих сведений зависят от сферы деятельности. Например, в промышленности ими могут быть датчики или измерительные приборы, которые показывают температуру, давление и т. д. В интернет-среде – запросы пользователей, время, проведенное на определенном сайте, количество кликов на иконку с товаром и т. п.
Данные могут быть любыми: как текстовыми документами и таблицами, так и аудио и видеороликами.
От области деятельности зависят и результаты работы Data Scientist. После извлечения нужной информации специалист устанавливает закономерности, подвергает их анализу, делает прогнозы и принимает бизнес-решения.
Человек этой профессии выполняет следующие задачи: оценивает эффективность и работоспособность предприятия, предлагает стратегию и инструменты для улучшения, показывает пути для развития, автоматизирует нудные задачи, помогает сэкономить на расходах и увеличить доход.
Его труд заканчивается созданием модели кода программы, сформировавшейся на основе работы с данными, которая предсказывает самый вероятный результат.
Профессия появилась относительно недавно. Лишь десятилетие назад она была официально зафиксирована. Но уже за такой короткий промежуток времени стала актуальной и очень перспективной.
Каждый год количество информации и данных увеличивается с геометрической прогрессией. В связи с этим информационные массивы уже не получается обрабатывать старыми стандартными средствами статистики. К тому же сведения быстро обновляются и собираются в неоднородном виде, что затрудняет их обработку и анализ.
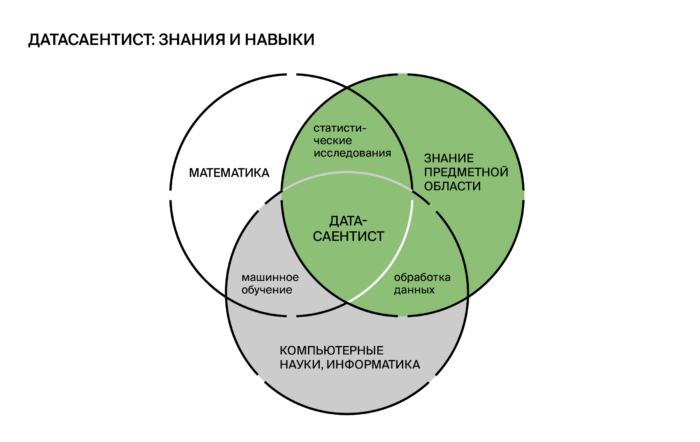
Вот тут на сцене и появляется Data Scientist. Он является междисциплинарным специалистом, у которого есть знания статистики, системного и бизнес-анализа, математики, экономики и компьютерных систем.
Знать все на уровне профессора не обязательно, а достаточно лишь немного понимать суть этих дисциплин. К тому же в крупных компаниях работают группы таких специалистов, каждый из которых лучше других разбирается в своей области.
Эти знания помогают ему выполнять свои должностные обязанности:
- взаимодействовать с заказчиком: выяснять, что ему нужно, подбирать для него подходящий вариант решения проблемы;
- собирать, обрабатывать, анализировать, изучать, видоизменять Big Data;
- анализировать поведение потребителей;
- составлять отчеты и делать презентации по выполненной работе;
- решать бизнес-задачи и увеличивать прибыль за счет использования данных;
- работать с популярными языками программирования;
- моделировать клиентскую базу;
- заниматься персонализацией продуктов;
- анализировать эффективность деятельности внутренних процессов компании;
- выявлять и предотвращать риски;
- работать со статистическими данными;
- заниматься аналитикой и методами интеллектуального анализа;
- выявлять закономерности, которые помогают организации достигнуть конечной цели;
- программировать и тренировать модели машинного обучения;
внедрять разработанную модель в производство.
Четких границ требований к Data Scientist нет, поэтому работодатели часто ищут сказочное создание, которое может все и на превосходном уровне. Да, есть люди, которые отлично понимают статистику, математику, аналитику, машинное обучение, экономику, программирование. Но таких специалистов крайне мало.
Еще часто Data Scientist путают с аналитиком. Но их задачи несколько разные. Поясню, что такое аналитика и как она отличается от деятельности Data Scientist, на примере и простыми словами.
В банк пришел клиент, чтобы оформить кредит. Программа начинает обрабатывать данные этого человека, выясняет его кредитную историю и анализирует платежеспособность заемщика. А алгоритм, который решает выдавать кредит или нет, – продукт работы Data Scientist.
Аналитик же, который работает в этом банке, не интересуется отдельными клиентами и не создает технические коды и программы. Вместо этого он собирает и изучает сведения обо всех кредитах, что выдал банк за определенный период, например, квартал. И на основе этой статистики решает, увеличить ли объемы выдачи кредитов или, наоборот, сократить.
Аналитик предлагает действия для решения задачи, а Data Scientist создает инструменты.
Работа data сайентистом
 Профессия data scientist интересна и востребована. Многие прямо сейчас изучают эту сферу, в то время как другие ищут хороших специалистов по данной специальности.
Профессия data scientist интересна и востребована. Многие прямо сейчас изучают эту сферу, в то время как другие ищут хороших специалистов по данной специальности.
Что касается востребованности, по множествам рейтингов в США эта профессия считается самой востребованной в стране. В России тоже много вакансий для дата-сайентиста, особенно в Москве. Так как сфера сейчас стремительно развивается и явно обладает огромным потенциалом, количество вакансий точно будет увеличиваться с каждым годом. Как у нас, так и за рубежом.
Основным плюсом работы специалистом по данным является заработная плата и быстро развивающееся направление, которое скорее всего будет актуально многие годы. Но сразу стоит отметить, что профессия объемная и трудная в изучении. Чтобы стать тем, кого возьмут на работу, надо потратить 1-2 года на обучение, усердно занимаясь на курсах или самостоятельно.
Так же дата-сайентистом крайне сложно стать людям, мало смыслящим в математике. Есть примеры, когда гуманитарий становился data-сайентистом, но для таких случаев путь изучения специальности еще более тернист и сложен. Помимо математики, облегчить становление специалистом по данным можно, зная статистику, программирование и основные принципы машинного обучения.
Заработок в профессии
То, сколько получают дата саентисты, зависит от нескольких факторов:
- опыт работы ученого по данным;
- навыки, которые можно подтвердить путем прохождения тестовых заданий или показа предыдущие проекты;
- сферы деятельности компании-работодателя;
- сложности конкретного проекта или группы проектов.
На 2020 год показатели зарплаты выше среднестатистических. Это от 70 тысяч рублей по России и от 100 тысяч рублей в Москве. Столько получают новички в профессии.
Средняя заработная плата специалиста составляет примерно 105-150 тысяч рублей в России и 140-190 тысяч рублей в Москве. Специалисты с высокой квалификацией и большим опытом зарабатывают от 230 тысяч рублей.
Заработок за границей зависит от страны. В Европе платят так же, как в Москве, а вот в Америке заработная плата больше. В час там платят в среднем 40-60 долларов, то есть работая условные 4 часа в день можно зарабатывать по 200 долларов. Высокая заработная плата связана не только с разницей в экономике России и США, но и с тем, что в Америке намного больше компаний и стартапов, которым нужен ученый по данным.
Требования и обязанности
Эффективный способ понять, что должен уметь дата саентист — ознакомиться с требованиями работодателя. Причем как в вакансиях на постоянную работу, так и в проектных работах на фрилансе. Конечно, у каждого работодателя будут свои требования к аналитику, но основные обязанности специалиста встречаются во всех вакансиях.
Список главных требований и обязанностей:
- проведение исследований в области деятельности компании;
- создание систем для прогнозирования и оценки рисков;
- сегментация клиентов;
- отличное владение SQL;
- оптимизация процессов на основе большого объема данных;
- создание автоматизированных систем для анализа данных на основе современного инструментария Data Science (Python, Apache Spark, Jupyter, Zeppelin);
- работа в Apache Kafka, HDFS, Apache Spark, Apache Cassandra;
- создание, развитие и поддержка внутренней инфраструктуры данных для их анализа, обработки и составления прогнозов;
- знание языка программирования Python и/или R;
- построение моделей данных и работа с сырыми данными;
- формулировка гипотез и их валидация;
- визуализация результатов;
- понимание принципов математической статистики и методов машинного обучения;
- использование прикладной статистики;
- работа с современными системами контроля версий (Git, HG);
- взаимодействие с подразделением IT.
Пример вакансии:

Где найти работу
В том, чтобы найти работу data сайентисту, нет ничего сложного. После обучения стоит поискать вакансии на одном из популярных сайтов (например, на HeadHunter или Trud). Там можно отфильтровать работу по опыту, заработной плате, виду деятельности и расположению офиса.
Если хочется начать с проектной работы, лучше поискать заказы на биржах фриланса. Отмечу, что проектные заказы, связанные с работой с данными, встречаются редко и довольно сложны в выполнении, так как требуют ознакомления с деятельностью компании-заказчика. Придется каждый раз делать это заново, ведь на фрилансе заказчики будут меняться часто. Поэтому данный вид деятельности рекомендован опытным специалистам, а не новичкам.
*2020: Академия больших данных MADE и HeadHunter выяснили, как меняется спрос на Data Scientist в России
16 июля 2020 года Академия больших данных MADE от Mail.ru Group и российская платформа онлайн-рекрутинга HeadHunter (hh.ru) составили портреты российских специалистов по анализу данных (Data Science) и машинному обучению (Machine Learning). Аналитики выяснили, где они живут и что умеют, а также чего ждут от них работодатели и как меняется спрос на таких профессионалов.
Академия MADE и HeadHunter (hh.ru) проводят исследование уже второй год подряд. На этот раз эксперты проанализировали 10 500 резюме и 8100 вакансий. По оценкам аналитиков, специалисты по анализу данных — одни из самых востребованных на рынке. В 2019 году вакансий в области анализа данных стало больше в 9,6 раза, а в области машинного обучения – в 7,2 раза, чем в 2015 году. Если сравнивать с 2018 годом, количество вакансий специалистов по анализу данных увеличилось в 1,4 раза, по машинному обучению – в 1,3 раза.

Активнее других специалистов по большим данным ищут ИТ-компании (на их долю приходится больше трети – 38% – открытых вакансий), компании из финансового сектора (29% вакансий), а также из сферы услуг для бизнеса (9% вакансий).
Такая же ситуация и в сфере машинного обучения. Но здесь перевес в пользу ИТ-компаний еще очевиднее – они публикуют 55% вакансий на рынке. Каждую десятую вакансию размещают компании из финансового сектора (10% вакансий) и сферы услуг для бизнеса (9%).
С июля 2019 года по апрель 2020 года резюме специалистов по анализу данных и машинному обучению стало больше на 33%. Первые в среднем размещают 246 резюме в месяц, вторые – 47.

Самый популярный навык — владение Python. Это требование встречается в 45% вакансий специалистов по анализу данных и в половине (51%) вакансий в области машинного обучения.
Также работодатели хотят, чтобы специалисты по анализу данных знали SQL (23%), владели интеллектуальным анализом данных (Data Mining) (19%), математической статистикой (11%) и умели работать с большими данными (10%).
Работодатели, которые ищут специалистов по машинному обучению, наряду со знанием Python ожидают, что кандидат будет владеть C++ (18%), SQL (15%), алгоритмами машинного обучения (13%) и Linux (11%).
В целом предложение на рынке Data Science соответствует спросу. Среди самых распространенных навыков специалистов по анализу данных – владение Python (77%), SQL (48%), анализом данных (45%), Git (28%) и Linux (21%). При этом владение Python, SQL и Git – навыки, которые практически одинаково часто встречаются в резюме специалистов любого уровня. Опытных специалистов отличают развитые навыки анализа данных, в том числе интеллектуального (Data Analysis и Data Mining).

У специалистов по машинному обучению в топе такие навыки, как владение Python (72%), SQL (34%), Git (34%), Linux (27%) и С++ (22%).
На долю Москвы приходится больше половины (65%) вакансий специалистов по в сфере анализа данных и ровно половина вакансий специалистов в области машинного обучения. На втором месте Санкт-Петербург: 15% вакансий специалистов в сфере анализа данных и 18% вакансий в области машинного обучения — в этом городе.
По сравнению с первым полугодием 2019 года в июле 2019 года – апреле 2020 года доля вакансий специалистов по анализу данных в Москве несколько возросла — с 60% до 65%.
Что касается соискателей, больше половины из них также находятся в Москве: 63% специалистов по анализу данных и 53% специалистов по машинному обучению. Вторая строчка – тоже за Санкт-Петербургом (16% и 19% резюме соответственно).
Этап 6
Углубление и развитие технических навыков
Если предыдущие этапы давали вам навыки, без которых работать ну вообще нельзя, то навыки этого этапа призваны повысить вашу продуктивность или повысить качество решаемых задач, повысить самостоятельность при запуске разработанных моделей машинного обучения в продакшн.
-
Python на хорошем уровне: декораторы, уверенное знание классов и наследования, изучение базовых классов, dunderscore __методы__ .
-
Уверенное пользование bash, понимание основ linux
-
Полезно изучить основы docker
Все эти вещи можно было бы учить и раньше. Но, как правило, раньше их знать просто не нужно. Т.к. вы больше будете страдать от нехватки других навыков, приведенных в предыдущих этапах.
Другие области машинного обучения
В какой-то момент вам может потребоваться выйти из сферы подготовки прогнозных моделей или изучения и объяснения данных (кластеризация, EDA и визуализация). Это может быть связано как с вашими интересами, так и с проектами на работе. Например, это могут быть рекомендательные системы. Наверное, базовые рекомендательные алгоритмы можно изучать и одновременно с основами машинного обучения, т.к. знание одного не является обязательным для знания другого. Но логичнее переходить к ним, когда вы уже разобрались с основными алгоритмами обучения прогнозирования и кластеризации: скорее всего, этого от вас будут ожидать любые коллеги до тех пор, как вы включитесь в работу над рекомендательными системами.
Нейронные сети
Начиная с этого этапа имеет смысл изучать нейронные сети как следует с тем, чтобы применять их на пратике. Неэффективно изучать их раньше, т.к. многие задачи эффективно можно решить другими методами. И пока ваши данные и прогнозы изначально числовые, обычно «классическими» методами их решать эффективнее.
Подробнее в этапы изучениях нейронных сетей вдаваться не стану: эта тема требует отдельной статьи. И потратить на них можно от 50, чтобы решать самые простейшие задачи, до сотен часов, чтобы решать задачи связанные с обработкой неструктурированных данных или с обучением сложных моделей.
Соберем данные
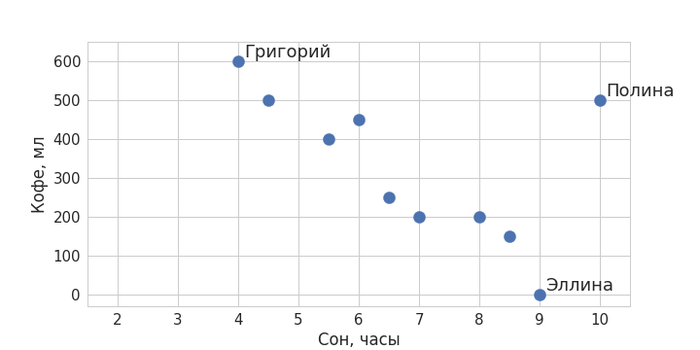
Чтобы не быть голословным, я приведу простой пример. Соберем какие-нибудь данные.
Представьте, что нас интересует, есть ли какая-то взаимосвязь между тем, сколько ваши коллеги по работе выпивают кофе за день, и тем, сколько они спали накануне. Запишем доступную нам информацию: допустим, ваш коллега Григорий сегодня спал 4 часа, так что ему пришлось выпить 3 чашки кофе; Эллина спала 9 часов и не пила кофе вообще; а Полина спала все 10 часов, но выпила 2,5 чашки кофе – и так далее.
Изобразим полученные данные на графике (визуализация – тоже немаловажный элемент любого data science-проекта). Отложим по оси X время в часах, а по оси Y – кофе в миллилитрах. Получим что-то вроде такого: