Онлайн сервис восстановления сайтов из веб архива
Содержание:
- Качаем сайт с web.archive.org
- Как использовать веб-архив?
- Что делать, если удалённая страница не сохранена ни в одном из архивов?
- Поиск сайтов в Wayback Machine
- Как открыть веб-архив?
- Хроника событий
- Как пользоваться веб-архивом?
- web.archive.org
- Инструкция по получению уникальных статей с вебархива
- Смотрим, как выглядела страница раньше
- Сеть тематических сайтов
- Методы сбора
- Другие полезные инструменты
- Восстановление сайта из веб архива
- Что такое веб-архив?
- Компании, архивирующие интернет
- Кэш браузера
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Как использовать веб-архив?
Форма для поиска информации на Peeep.us Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
cache:URL
Например:
cache:https://hackware.ru/?p=6045
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Например, текстовый вид:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=1&vwsrc=0
Исходный код:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=0&vwsrc=1
Поиск сайтов в Wayback Machine
Wayback Machine
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
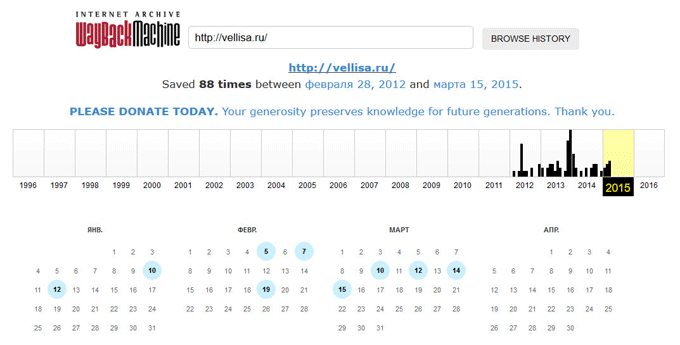
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.

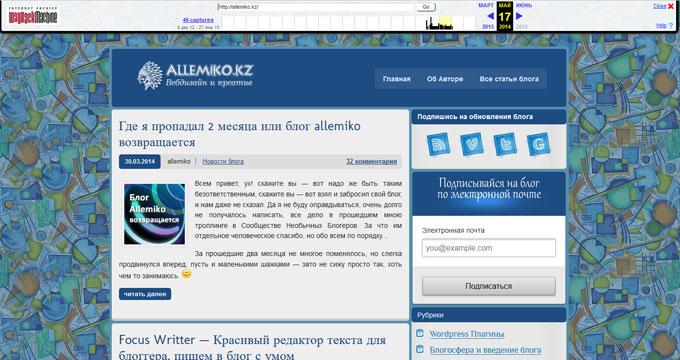
На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
Как открыть веб-архив?
Заключительный вопрос – как открыть веб-архив и начать им пользоваться уже сейчас. Для этого достаточно перейти на официальную страницу с адресом archive.org и войти на страницу поиска сохранений ресурсов. При выдаче результатов поиска, Вы найдёте даты, когда программа работала с сохранением того или иного сайта.

Информация, сохранённая веб-архивом, может быть полезна любому пользователю. С помощью него можно исследовать эволюцию сайтов после того, как им начали делать продвижение дёшево и качественно. Если Вы не смогли найти сохранения нужного ресурса, скорее всего, правообладатель внёс директорию запрет на копирование. Так же причиной может стать закрытие сайта в согласии с законом о защите интеллектуальной собственности.
Знание о том, что такое веб-архив и как им правильно пользоваться, помогает пользователям получать доступ к версиям сайтов разных лет. Это помогает проследить историю создания и изменения ресурсов с течением времени. При необходимости найти информацию с ныне несуществующего ресурса или с его старых версий, используйте веб-архив. Это бесплатная и удобная программа, сохраняющая информацию для Вас с 1996 года.
Хроника событий
АЗАПИ, по данным Роскомсвободы, действует в интересах издателя ООО «Аудиокнига», и началось все с аудиокниг по серии романов Глуховского «Метро 2033», к которым позже добавилось произведение Дарьи Донцовой «Третий глаз алмаз». Иск по этому делу (номер дела 3-0335/2019) был подан 13 марта 2019 г, а Мосгорсуд рассмотрел его 13 мая 2019 г., притом в экстренном порядке, и вынес вердикт в пользу истца. Решение вступило в силу 15 июня 2019 г.
По решению суда, «Интернет архиву» и другим ответчикам («ДейтаВебГлобал Групп» и ООО «ТК Мароснет») было запрещено «создавать технические условия, обеспечивающие размещение» аудиокниг на веб-ресурсах, перечисленных в иске
Важно отметить, что представители «Интернет архива» участия в заседании не принимали, а о решении суда американская организация извещена не была

Россию могут навсегда оставить без Архива интернета
Второй иск был подан 21 июня 2019 г. (номер дела – 3-0634/2019, ответчик – «Интернет архив»). В нем истец (ООО «Аудиокнига», как и в первом случае) требовал заблокировать сайт archive.org в России на постоянной основе. Заседание по иску состоялось 16 августа 2019 г., однако рассмотрение дела было отложено по причине отсутствия у АЗАПИ доказательств того, что «Третий глаз алмаз» действительно был записан в форме аудиокниги обществом «Аудиокнига», и что у него (общества) есть права на эту книгу.
Рассмотрение было назначено на 12 сентября 2019 г, и существует еще одна причина переноса – по информации Роскомсвободы, на решение Мосгорсуда по первому иску была подана жалоба, дата рассмотрения которой на 23 августа 2019 г. оставалась неизвестной. По обоим делам американскую организацию в российском суде представляют юристы Роскомсвободы и Центра цифровых прав адвокат Саркис Дарбинян и Екатерина Абашина.
Как пользоваться веб-архивом?
В том, как пользоваться веб-архивом, нет ничего сложного. Для того, чтобы использовать его, достаточно перейти на соответствующий сайт archive.org и в поиске вести адрес нужного сайта. После непродолжительного времени, архив выдаст информацию об имеющихся сохранениях этого ресурса.

Например, с помощью этого можно найти информацию с сайта, который по каким-либо причинам перестал существовать. Так же веб архив поможет найти информацию со страниц, даже если она была удалена
Это особенно важно для поиска удачных примеров сторителлинга лет. Рассмотрим подробнее, как посмотреть архив.
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».
Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:
В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.
При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:
Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:
Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
Инструкция по получению уникальных статей с вебархива
1. Запускаем ваш любимый браузер и вводим адрес web.archive.org.
Главная страница вебархива, где будем искать статьи
2. В поисковой строке набираем интересующую вас тематику, например «траляля»
3. Смотрим выдачу сайтов из вебархива
4. Анализируем домены по следующим признакам
4.1. Количество страниц в вебархиве должно быть больше 50

Выдача вебархива, где можно увидеть сколько страниц в архиве
4.2. Проверяем сайт на работоспособность, для этого копируем домен и вставляем в адресную строку браузера. В нашем случае это домен www.generix.com.ua, он оказался свободен.
4.3. Если же домен будет занят и на нем будет находится сайт по схожей тематике то повторите пункты 4.1 и 4.2
4.4. Проверяем таким образом все домены в выдаче вебархива и сохраняем в блокнот те домены которые нам подходят.
5. Скачиваем программу Web Archive Downloader и с помощью нее сохраняем на компьютер архивные копии сайтов, более подробно по работе с программой вы можете ознакомиться в разделе FAQ.
6. Проверяем полученные статьи на уникальность (как читайте ниже)
7. Используем полученные уникальные статьи по назначению
В принципе все, как вы видите ничего сложного нет, осталось разобраться как проверять статьи на уникальность массово. Ведь вы скачаете их
большое количество.
Смотрим, как выглядела страница раньше
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Подробнее: Как открыть стену ВК
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
Подробнее: Поиск без регистрации ВК
Среди представленных результатов отыщите нужный и кликните по иконке с изображением стрелочки, расположенной под основной ссылкой.
Из раскрывшегося списка выберите пункт «Сохраненная копия».
После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Способ 3: Web Archive
Данный сайт является менее популярным аналогом предыдущего ресурса, но со своей задачей справляется более чем хорошо. Кроме того, вы всегда можете воспользоваться этим веб-архивом, если ранее рассмотренный сайт по каким-либо причинам оказался временно недоступен.
- Открыв главную страницу сайта, заполните основную поисковую строку ссылкой на профиль и нажмите кнопку «Найти».
После этого под формой поиска появится поле «Результаты», где будут представлены все найденные копии страницы.
В списке «Другие даты» выберите колонку с нужным годом и кликните по наименованию месяца.
С помощью календаря кликните по одному из найденных чисел.
По завершении загрузки вам будет представлена анкета пользователя, соответствующая выбранной дате.
Как и в прошлом методе, все возможности сайта, кроме непосредственного просмотра информации, будут блокированы. Однако на сей раз содержимое полностью переведено на русский язык.
Вы также можете прибегнуть к еще одной статье на нашем сайте, рассказывающей о возможности просмотра удаленных страниц. Мы же завершаем данный способ и статью, так как изложенного материала более чем достаточно для просмотра ранней версии страницы ВКонтакте.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Сеть тематических сайтов
Люди работающие в конкретной сфере, например «бухгалтерские услуги», ищут в веб-архиве сайты по данной тематике. После их восстановления могут использовать как для социальных сетей (разных групп), в качестве сайтов визиток, так и для того что бы «забить» поисковую выдачу. Таким образом получается создать большую сетку сайтов для продвижения своего бизнеса за маленькие деньги, т.к. стоимость восстановленного сайта очень низкая в сравнении даже с разработкой бюджетного проекта.
Еще данная сетка может служить в качестве источника ссылочной массы на основной продвигаемый ресурс. Ссылки постепенно «отмирают», но по-прежнему еще имеют вес в фактораъ ранжирования.
Методы сбора
Существует несколько способов архивирования интернета, ниже описана часть из них.
Удалённый сбор
Метод веб-архивирования отдельных сайтов, автоматизирующий сбор веб-страниц.
Примеры веб-сканеров для персональных компьютеров:
- Heretrix
- HTTrack
- Wget
Онлайн-сервисы веб-сканеров:
- Wayback Machine
- WebCite
Архивирование баз данных
Метод веб-архивирования, который основан на архивированию основного содержания сайта из базы данных.
Таким образом работают системы DeepArc и Xinq, разработанные Национальной библиотекой Франции и Национальной библиотекой Австралии, соответственно. Первая программа позволяет, используя реляционную базу данных, отображать информацию в виде XML-схемы; вторая программа позволяет запомнить оригинальное оформление сайта, соответственно создавая точную копию.
Архивирование транзакциями
Метод архивирования, который сохраняет данные, пересылаемые между веб-сервером и клиентом. Используется, как правило, для доказательств содержания, которое было предоставлено на самом деле в определённую дату. Такое программное обеспечение может потребоваться организациям, которые нуждаются в документировании информации такого типа.
Такое ПО, как правило, просто перехватывает все HTTP-запросы и ответы, фильтруя дубликаты ответов.
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.
Web Archives
Разработчик:
Сайт
Цена:
0
Web Archives от Armin Sebastian
Разработчик:
Разработчик
Цена:
Бесплатно
Восстановление сайта из веб архива
Восстановить удаленный либо взломанный хакерами сайт поможет веб-архив. Восстановление каждой отдельной HTML-страницы проекта слишком трудоемкий процесс, поэтому предпочтительнее использовать специальные программы для парсинга WEB-архива.
Как парсить веб-архив с помощью Robotools
Для скачивания сайта с помощью данного сервиса необходимо выбрать подходящий тариф в зависимости от количества веб-страниц на проекте:
Протестировать работу сервиса можно в , после регистрации будет доступно 25 страниц бесплатно:
Перейдем в раздел «Мои задачи», укажем домен, на котором ранее функционировал нужный сайт и нажмем «Запуск»:
Затем выбираем «Восстановить домен или снимок из веб-архива»:
После этого выбираем нужную дату, количество страниц, действия с внешними ссылками в статьях и нажимаем «Начать процесс восстановления»:
После завершения задачи нажимаем на кнопку для скачивания архива с веб-страницами:
Затем нажимаем «Все ОК, собрать ZIP-архив»:
После этого нажимаем «Скачать архив»:
В данном примере рассматривалось восстановление сайта на WordPress, получен архив с такими файлами:
Как скачать сайт из веб-архива с помощью Archivarix
Этот сервис также помогает восстановить старые версии сайтов из веб-архива. Цены зависят от количества файлов на проекте. Начнем работу с выбора раздела «Восстановить из веб-архива». Укажем домен и при желании установим временной диапазон, в правой колонке отметим дополнительные параметры восстанавливаемого проекта:
Затем укажем электронный адрес и нажмем «Восстановить»:
Если сайт содержит более 200 файлов, придет уведомление на почту с предложением оплатить восстановление проекта:
Что такое веб-архив?
Для того, чтобы узнать, что такое веб-архив, стоит вспомнить события, произошедшие более 20 лет назад. В 1996 году по инициативе американского программиста, Брюстера Кайла, был создан сайт archiveorg. Благодаря этому ресурсу, любой пользователь может найти сохранённые копии сайтов разных лет.

Со временем библиотека Web archive расширилась и к 2016 году включала в себя 502 миллиарда копий веб-страниц. Это является одним из лучших примеров коллаборации с целью принести обществу пользу. Для того, чтобы посмотреть в реальном времени сайты, которые функционировали некоторое время назад, достаточно зайти в архив и найти его в системе.
Основной целью, которую преследовал Кайл, было сохранение исторические ценности интернет-пространства. Web archive может использовать каждый пользователь, при этом бесплатно. Для работы веб-архива по сохранению интернет-ресурсов может быть только одно препятствие. Если в настройках сайта нет запрета на сохранение информации с ресурса, такой сайт сможет войти в базу веб-архива.
Как происходит пополнение веб-архива? Для этого было создано программное обеспечение, посещающее и сохраняющее сайта с определённой частотой. Так же есть возможность делать сохранения ресурсов вручную. Например, при посещении сайта можно сохранить страницу о курсах СЕО для начинающих или любую другую часть ресурса. Это поможет сохранить информацию с течением времени.
Компании, архивирующие интернет
Архив Интернета
Основная статья: Архив Интернета
В 1996 году была основана некоммерческая организация «Internet Archive». Архив собирает копии веб-страниц, графические материалы, видео-, аудиозаписи и программное обеспечение. Архив обеспечивает долгосрочное архивирование собранного материала и бесплатный доступ к своим базам данных для широкой публики. Размер архива на 2019 год — более 45 петабайт; еженедельно добавляется около 20 терабайт. На начало 2009 года он содержал 85 миллиардов веб-страниц., в мае 2014 года — 400 миллиардов. Сервер Архива расположен в Сан-Франциско, зеркала — в Новой Александрийской библиотеке и Амстердаме. С 2007 года Архив имеет юридический статус библиотеки. Основной веб-сервис архива — The Wayback Machine. Содержание веб-страниц фиксируется с временны́м промежутком c помощью бота. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует по старому адресу.
В июне 2015 года сайт был заблокирован на территории России по решению Генпрокуратуры РФ за архивы страниц, признанных содержащими экстремистскую информацию, позднее был исключён из реестра.
WebCite
Основная статья: WebCite
«WebCite» — интернет-сервис, который выполняет архивирование веб-страниц по запросу. Впоследствии на заархивированную страницу можно сослаться через url. Пользователи имеют возможность получить архивную страницу в любой момент и без ограничений, и при этом неважен статус и состояние оригинальной веб-страницы, с которой была сделана архивная копия. В отличие от Архива Интернета, WebCite не использует веб-краулеров для автоматической архивации всех подряд веб-страниц. WebCite архивирует страницы только по прямому запросу пользователя. WebCite архивирует весь контент на странице — HTML, PDF, таблицы стилей, JavaScript и изображения. WebCite также архивирует метаданные о архивируемых ресурсах, такие как время доступа, MIME-тип и длину контента. Эти метаданные полезны для установления аутентичности и происхождения архивированных данных. Пилотный выпуск сервиса был выпущен в 1998 году, возрождён в 2003.
По состоянию на 2013 год проект испытывает финансовые трудности и проводит сбор средств, чтобы избежать вынужденного закрытия.
Peeep.us
Сервис peeep.us позволяет сохранить копию страницы по запросу пользования, в том числе и из авторизованной зоны, которая потом доступна по сокращённому URL. Реализован на Google App Engine.
Сервис peeep.us, в отличие от ряда других аналогичных сервисов, получает данные на клиентской стороне — то есть, не обращается напрямую к сайту, а сохраняет то содержимое сайта, которое видно пользователю. Это может использоваться для того, чтобы можно было поделиться с другими людьми содержимым закрытого для посторонних ресурса.
Таким образом, peeep.us не подтверждает, что по указанному адресу в указанный момент времени действительно было доступно заархивированное содержимое. Он подтверждает лишь то, что у инициировавшего архивацию по указанному адресу в указанный момент времени подгружалось заархивированное содержимое. Таким образом, Peeep.us нельзя использовать для доказательства того, что когда-то на сайте была какая-то информация, которую потом намеренно удалили (и вообще для каких-либо доказательств). Сервис может хранить данные «практически вечно», однако оставляет за собой право удалять контент, к которому никто не обращался в течение месяца.
Возможность загрузки произвольных файлов делает сервис привлекальным для хостинга вирусов, из-за чего peeep.us регулярно попадаёт в чёрные списки браузеров.
Archive.today
Основная статья: archive.today
Сервис archive.today (ранее archive.is) позволяет сохранять основной HTML-текст веб-страницы, все изображения, стили, фреймы и используемые шрифты, в том числе страницы с Веб 2.0-сайтов, например с Твиттер.
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;
в этом подменю нажмите «Работать автономно».
Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
IT-специалист и продвинутый пользователь ВК. Зарегистрировался в соцсети в 2007 году.