Сортировка списка python
Содержание:
- Своя сортирующая функция
- Доступ к элементам
- Выполняет сортировку последовательности по возростанию/убыванию.
- The Old Way Using Decorate-Sort-Undecorate
- Быстрая сортировка
- Как работает Быстрая сортировка
- Старый способ использования параметра cmp
- Сортировка фрейма данных по нескольким столбцам ↑
- Работа с отсутствующими данными при сортировке в Pandas ↑
- When to Use sorted() and When to Use .sort()
- Python sort list of dictionaries
- Operator Module Functions
- The Old Way Using the cmp Parameter
Своя сортирующая функция
Язык Python позволяет
создавать свои сортирующие функции для более точной настройки алгоритма
сортировки. Давайте для начала рассмотрим такой пример. Пусть у нас имеется вот
такой список:
a=1,4,3,6,5,2
и мы хотим,
чтобы вначале стояли четные элементы, а в конце – нечетные. Для этого создадим
такую вспомогательную функцию:
def funcSort(x): return x%2
И укажем ее при
сортировке:
print( sorted(a, key=funcSort) )
Мы здесь
используем именованный параметр key, который принимает ссылку на
сортирующую функцию. Запускаем программу и видим следующий результат:
Разберемся,
почему так произошло. Смотрите, функция funcSort возвращает вот
такие значения для каждого элемента списка a:
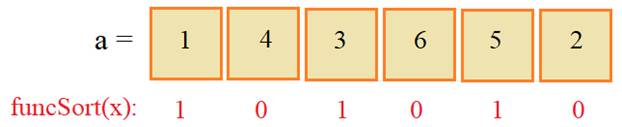
И, далее, в sorted уже
используются именно эти значения для сортировки элементов по возрастанию. То
есть, сначала, по порядку берется элемент со значением 4, затем, 6 и потом 2.
После этого следуют нечетные значения в порядке их следования: 1, 3, 5. В
результате мы получаем список:
А теперь,
давайте модифицируем нашу функцию, чтобы выполнялась сортировка и самих
значений:
def funcSort(x): if x%2 == : return x else: return x+100
Здесь четные
значения возвращаются такими как они есть, а к нечетным прибавляем 100. В
результате получим:

Здесь элементам
нашего списка ставятся в соответствие указанные числа, и по этим числам
выполняется их сортировка. То есть, эти числа можно воспринимать как некие
ключи, по которым и происходит сортировка элементов списка. Поэтому в Python
такую
сортировку называют сортировкой по ключам.
Конечно, здесь
вместо определения своей функции можно также записывать анонимные функции,
например:
print( sorted(a, key=lambda x: x%2) )
Получим ранее
рассмотренный результат:
Или, то же самое
можно делать и со строками:
lst = "Москва", "Тверь", "Смоленск", "Псков", "Рязань"
Отсортируем их
по длине строки:
print( sorted(lst, key=len) )
получим
результат:
Или по
последнему символу, используя лексикографический порядок:
print( sorted(lst, key=lambda x: x-1) )
Или, по первому
символу:
print( sorted(lst, key=lambda x: x) )
И так далее. Этот
подход часто используют при сортировке сложных структур данных. Допустим, у нас
имеется вот такой список из книг:
books = {
("Евгений Онегин", "Пушкин А.С.", 200),
("Муму", "Тургенев И.С.", 250),
("Мастер и Маргарита", "Булгаков М.А.", 500),
("Мертвые души", "Гоголь Н.В.", 190)
}
И нам нужно его
отсортировать по возрастанию цены (последнее значение). Это можно сделать так:
print( sorted(books, key=lambda x: x2) )
На выходе
получим список:
Вот так можно
выполнять сортировку данных в Python.
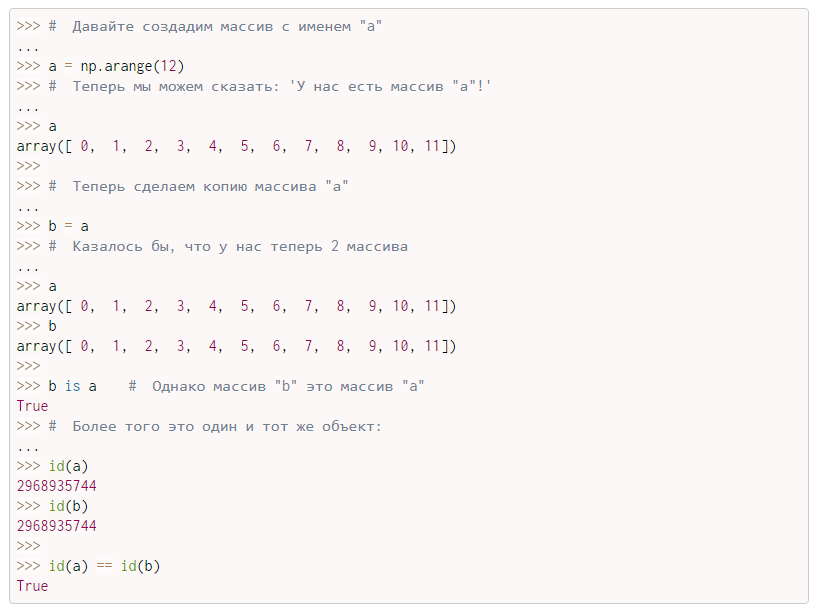
Доступ к элементам
Мы можем получить доступ к элементам списка с помощью index. Значение индекса начинается с 0.
>>> vowels_list = >>> vowels_list 'a' >>> vowels_list 'u'
Если индекс не входит в диапазон, возникает IndexError.
>>> vowels_list Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range >>>
Мы также можем передать отрицательное значение индекса. В этом случае элемент возвращается от конца к началу. Допустимый диапазон значений индекса — от -1 до — (длина).
Это полезно, когда нам нужен определенный элемент быстро, например, последний элемент, второй последний элемент и т. д.
>>> vowels_list = >>> vowels_list # last element 'u' >>> vowels_list # second last element 'e' >>> vowels_list 'a'
Выполняет сортировку последовательности по возростанию/убыванию.
Параметры:
- — объект, поддерживающий итерирование
- — пользовательская функция, которая применяется к каждому элементу последовательности
- — порядок сортировки
Описание:
Функция вернет новый отсортированный t-list] из итерируемых элементов. Функция имеет два необязательных аргумента, которые должны быть указаны в качестве аргументов ключевых слов.
Аргумент принимает функцию, например . Переданная функция вычисляет результат для каждого элемента последовательности, который используется для сравнения элементов при сортировке. Значением по умолчанию является , т.е. сравнивать элементы напрямую (как есть).
Аргумент имеет логическое значение. Если установлено значение , то элементы списка сортируются в обратной последовательности (по убыванию).
Используйте для преобразования функции, использующей cmp (старый стиль) в использующую key (новый стиль).
Встроенная функция sorted() является гарантированно стабильной. Это означает, что когда несколько элементов последовательности имеют равные значения, их первоначальный порядок сохраняется. Такое поведение полезно при сортировке в несколько проходов.
Примеры различных способов сортировки последовательностей.
Сортировка слов в предложении без учета регистра:
line = 'This is a test string from Andrew' x = sorted(line.split(), key=str.lower) print(x) #
Сортировка сложных объектов с использованием индексов в качестве ключей :
student =
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
# Сортируем по возрасту student
x = sorted(student, key=lambda student student2])
print(x)
#
Тот же метод работает для объектов с именованными атрибутами.
class Student
def __init__(self, name, grade, age):
self.name = name
self.grade = grade
self.age = age
def __repr__(self):
return repr((self.name, self.grade, self.age))
student =
Student('john', 'A', 15),
Student('jane', 'B', 12),
Student('dave', 'B', 10),
x = sorted(student, key=lambda student student.age)
print(x)
#
Сортировка по убыванию:
student =
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
# Сортируем по убыванию возраста student
x = sorted(student, key=lambda i i2], reverse=True)
print(x)
#
Стабильность сортировки и сложные сортировки:
data = x = sorted(data, key=lambda data data]) print(x) #
Обратите внимание, как две записи (‘blue’, 1), (‘blue’, 2) для синего цвета сохраняют свой первоначальный порядок. Это замечательное свойство позволяет создавать сложные сортировки за несколько проходов по нескольким ключам
Например, чтобы отсортировать данные учащиеся по возрастанию успеваемости, а затем по убыванию возраста. Успеваемость будет первым ключом, возраст вторым
Это замечательное свойство позволяет создавать сложные сортировки за несколько проходов по нескольким ключам. Например, чтобы отсортировать данные учащиеся по возрастанию успеваемости, а затем по убыванию возраста. Успеваемость будет первым ключом, возраст вторым.
student =
('john', 15, 4.1),
('jane', 12, 4.9),
('dave', 10, 3.9),
('kate', 11, 4.1),
# По средней оценке
x = sorted(student, key=lambda num num2])
# По убыванию возраста
y = sorted(x, key=lambda age age1], reverse=True)
print(y)
#
А еще, для сортировок по нескольким ключам, удобнее использовать модуль . Функции модуля допускают несколько уровней сортировки. Например, как в предыдущем примере успеваемость будет первым ключом, возраст вторым.Только сортировать будем все по возрастанию:
from operator import itemgetter x = sorted(student, key=itemgetter(2,1)) print(x) #
The Old Way Using Decorate-Sort-Undecorate
This idiom is called Decorate-Sort-Undecorate after its three steps:
- First, the initial list is decorated with new values that control the sort order.
- Second, the decorated list is sorted.
- Finally, the decorations are removed, creating a list that contains only the initial values in the new order.
For example, to sort the student data by grade using the DSU approach:
>>> decorated = >>> decorated.sort() >>> # undecorate
This idiom works because tuples are compared lexicographically; the first items are compared; if they are the same then the second items are compared, and so on.
It is not strictly necessary in all cases to include the index i in the decorated list. Including it gives two benefits:
- The sort is stable — if two items have the same key, their order will be preserved in the sorted list.
-
The original items do not have to be comparable because the ordering of the decorated tuples will be determined by at most the first two items. So for example the original list could contain complex numbers which cannot be sorted directly.
Another name for this idiom is Schwartzian transform, after Randal L. Schwartz, who popularized it among Perl programmers.
For large lists and lists where the comparison information is expensive to calculate, and Python versions before 2.4, DSU is likely to be the fastest way to sort the list. For 2.4 and later, key functions provide the same functionality.
Быстрая сортировка
Этот алгоритм также относится к алгоритмам «разделяй и властвуй». Его используют чаще других алгоритмов, описанных в этой статье. При правильной конфигурации он чрезвычайно эффективен и не требует дополнительной памяти, в отличие от сортировки слиянием. Массив разделяется на две части по разные стороны от опорного элемента. В процессе сортировки элементы меньше опорного помещаются перед ним, а равные или большие —позади.
Алгоритм
Быстрая сортировка начинается с разбиения списка и выбора одного из элементов в качестве опорного. А всё остальное передвигаем так, чтобы этот элемент встал на своё место. Все элементы меньше него перемещаются влево, а равные и большие элементы перемещаются вправо.
Реализация
Существует много вариаций данного метода. Способ разбиения массива, рассмотренный здесь, соответствует схеме Хоара (создателя данного алгоритма).
Время выполнения
В среднем время выполнения быстрой сортировки составляет O(n log n).
Обратите внимание, что алгоритм быстрой сортировки будет работать медленно, если опорный элемент равен наименьшему или наибольшему элементам списка. При таких условиях, в отличие от сортировок кучей и слиянием, обе из которых имеют в худшем случае время сортировки O(n log n), быстрая сортировка в худшем случае будет выполняться O(n²)
Как работает Быстрая сортировка
Быстрая сортировка чаще всего не сможет разделить массив на равные части. Это потому, что весь процесс зависит от того, как мы выбираем опорный элемент. Нам нужно выбрать опору так, чтобы она была примерно больше половины элементов и, следовательно, примерно меньше, чем другая половина элементов. Каким бы интуитивным ни казался этот процесс, это очень сложно сделать.
Подумайте об этом на мгновение — как бы вы выбрали адекватную опору для вашего массива? В истории быстрой сортировки было представлено много идей о том, как выбрать центральную точку — случайный выбор элемента, который не работает из-за того, что «дорогой» выбор случайного элемента не гарантирует хорошего выбора центральной точки; выбор элемента из середины; выбор медианы первого, среднего и последнего элемента; и еще более сложные рекурсивные формулы.
Самый простой подход — просто выбрать первый (или последний) элемент. По иронии судьбы, это приводит к быстрой сортировке на уже отсортированных (или почти отсортированных) массивах.
Именно так большинство людей выбирают реализацию быстрой сортировки, и, так как это просто и этот способ выбора опоры является очень эффективной операцией, и это именно то, что мы будем делать.
Теперь, когда мы выбрали опорный элемент — что нам с ним делать? Опять же, есть несколько способов сделать само разбиение. У нас будет «указатель» на нашу опору, указатель на «меньшие» элементы и указатель на «более крупные» элементы.
Цель состоит в том, чтобы переместить элементы так, чтобы все элементы, меньшие, чем опора, находились слева от него, а все более крупные элементы были справа от него. Меньшие и большие элементы не обязательно будут отсортированы, мы просто хотим, чтобы они находились на правильной стороне оси. Затем мы рекурсивно проходим левую и правую сторону оси.
Рассмотрим пошагово то, что мы планируем сделать, это поможет проиллюстрировать весь процесс. Пусть у нас будет следующий список.
29 | 99 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,21,44 (high)
Выберем первый элемент как опору 29), а указатель на меньшие элементы (называемый «low») будет следующим элементом, указатель на более крупные элементы (называемый «high») станем последний элемент в списке.
29 | 99 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,21 (high),44
Мы двигаемся в сторону high то есть влево, пока не найдем значение, которое ниже нашего опорного элемента.
29 | 99 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,21 (high),44
- Теперь, когда наш элемент high указывает на элемент 21, то есть на значение меньше чем опорное значение, мы хотим найти значение в начале массива, с которым мы можем поменять его местами. Нет смысла менять местами значение, которое меньше, чем опорное значение, поэтому, если low указывает на меньший элемент, мы пытаемся найти тот, который будет больше.
- Мы перемещаем переменную low вправо, пока не найдем элемент больше, чем опорное значение. К счастью, low уже имеет значение 89.
- Мы меняем местами low и high:
29 | 21 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,99 (high),44
- Сразу после этого мы перемещает high влево и low вправо (поскольку 21 и 89 теперь на своих местах)
- Опять же, мы двигаемся high влево, пока не достигнем значения, меньшего, чем опорное значение, и мы сразу находим — 12
- Теперь мы ищем значение больше, чем опорное значение, двигая low вправо, и находим такое значение 41
Этот процесс продолжается до тех пор, пока указатели low и high наконец не встретятся в одном элементе:
29 | 21,27,12,19,28 (low/high),44,78,87,66,31,76,58,88,83,97,41,99,44
Мы больше не используем это опорное значение, поэтому остается только поменять опорную точку и high, и мы закончили с этим рекурсивным шагом:
28,21,27,12,19,29,44,78,87,66,31,76,58,88,83,97,41,99,44
Как видите, мы достигли того, что все значения, меньшие 29, теперь слева от 29, а все значения больше 29 справа.
Затем алгоритм делает то же самое для коллекции 28,21,27,12,19 (левая сторона) и 44,78,87,66,31,76,58,88,83,97,41,99,44 (правая сторона). И так далее.
Старый способ использования параметра cmp
Многие конструкции, приведенные в этом HOWTO, предполагают Python 2.4 или новее. До этого не было встроенных функций и c аргументами ключевых слов. Вместо этого все версии Py2.x поддерживали параметр для обработки заданных пользователем функций сравнения.
В Py3.0 параметр был полностью удален (как часть более масштабных усилий по упрощению и унификации языка, устраняя конфликт между богатыми сравнениями и магическим методом .
В Py2.x сортировка допускает необязательную функцию, которая может быть вызвана для сравнения. Эта функция должна принимать два аргумента для сравнения, а затем возвращать отрицательное значение для «меньше», возвращать ноль, если они равны, или возвращать положительное значение для «больше». Например, мы можем:
>>> def numeric_compare(x, y): ... return x - y >>> sorted(, cmp=numeric_compare)
Или вы можете изменить порядок сравнения:
>>> def reverse_numeric(x, y): ... return y - x >>> sorted(, cmp=reverse_numeric)
При переносе кода с Python 2.x на 3.x может возникнуть ситуация, когда у вас есть пользователь, предоставляющий функцию сравнения, и вам нужно преобразовать ее в ключевую функцию. Следующая оболочка упрощает это:
def cmp_to_key(mycmp):
'Convert a cmp= function into a key= function'
class K:
def __init__(self, obj, *args):
self.obj = obj
def __lt__(self, other):
return mycmp(self.obj, other.obj) 0
def __eq__(self, other):
return mycmp(self.obj, other.obj) == 0
def __le__(self, other):
return mycmp(self.obj, other.obj) = 0
def __ne__(self, other):
return mycmp(self.obj, other.obj) != 0
return K
Чтобы преобразовать в ключевую функцию, просто оберните старую функцию сравнения:
>>> sorted(, key=cmp_to_key(reverse_numeric))
В Python 3.2 функция была добавлена в модуль в стандартной библиотеке.
Сортировка фрейма данных по нескольким столбцам ↑
При анализе данных часто бывает необходимо отсортировать данные на основе значений нескольких столбцов. Представьте, что есть набор данных с именами и фамилиями людей. Было бы разумно отсортировать по фамилии, а затем по имени, чтобы люди с одинаковой фамилией располагались в алфавитном порядке в соответствии с их именами.
В первом примере сортировка DataFrame сделана по значениям одного столбца с именем . С точки зрения анализа, MPG в городских условиях является важным фактором, который может определить желательность автомобиля. В дополнение к MPG в городских условиях вы также можете посмотреть MPG на трассе. Для сортировки по двум ключам можно передать список имен столбцов, по которым надо сортировать:
Указав список имен столбцов и , сортируем DataFrame по двум столбцам с помощью
Далее объясняется, как указать порядок сортировки и почему важно обращать внимание на список используемых имен столбцов
Сортировка по нескольким столбцам в порядке возрастания
Для сортировки DataFrame по нескольким столбцам, необходимо указать список имен столбцов. Например, для сортировки по марке и модели надо создать следующий список, а затем передать его в :
>>> df.sort_values(
... by=
... ) ]
make model
0 Alfa Romeo Spider Veloce 2000
18 Audi 100
19 Audi 100
20 BMW 740i
21 BMW 740il
.. ... ...
12 Volkswagen Golf III / GTI
13 Volkswagen Jetta III
15 Volkswagen Jetta III
16 Volvo 240
17 Volvo 240
Теперь DataFrame отсортирован в порядке возрастания по марке. Если есть две или более одинаковых марок, то они сортируются по моделям. Порядок, в котором имена столбцов указаны в списке, соответствует тому, как будет сортироваться DataFrame.
Изменение порядка сортировки столбцов
Поскольку при сортировке используется несколько столбцов, можно указать порядок сортировки столбцов. Если необходимо изменить логический порядок сортировки из предыдущего примера, то можно изменить порядок имен столбцов в списке, который передаётся параметру :
>>> df.sort_values(
... by=
... ) ]
make model
18 Audi 100
19 Audi 100
16 Volvo 240
17 Volvo 240
75 Mazda 626
.. ... ...
62 Ford Thunderbird
63 Ford Thunderbird
88 Oldsmobile Toronado
42 CX Automotive XM v6
43 CX Automotive XM v6a
DataFrame теперь отсортирован по столбцу модели в возрастающем порядке, а затем сортируется по , если есть две или более одной и той же модели. Заметьте, что изменение порядка столбцов меняет порядок сортировки значений.
Сортировка по нескольким столбцам в порядке убывания
До этого момента мы сортировали несколько столбцов только в порядке возрастания. В следующем примере выполним сортировку в порядке убывания по столбцам марки и модели. Для сортировки в порядке убывания установите значение в :
>>> df.sort_values(
... by=,
... ascending=False
... ) ]
make model
16 Volvo 240
17 Volvo 240
13 Volkswagen Jetta III
15 Volkswagen Jetta III
11 Volkswagen Golf III / GTI
.. ... ...
21 BMW 740il
20 BMW 740i
18 Audi 100
19 Audi 100
0 Alfa Romeo Spider Veloce 2000
Значения в столбце указаны в обратном алфавитном порядке, а значения в столбце — в порядке убывания для всех автомобилей той же марки. Для текстовых данных сортировка чувствительна к регистру, то есть текст с заглавной буквы будет отображаться первым в порядке возрастания и последним в порядке убывания.
Сортировка по нескольким столбцам с разными порядками сортировки
Можно ли сортировать с использованием нескольких столбцов и использовать в этих столбцах разные аргументы по возрастанию? С pandas это можно сделать используя один вызов метода. Если вы хотите отсортировать некоторые столбцы в порядке возрастания и другие в порядке убывания, то можно передать список логических значений для .
В этом примере вы сортируете DataFrame по столбцам , и , причем первые два столбца отсортированы в порядке возрастания, а — в порядке убывания. Для этого вы передаете список имен столбцов в и список логических значений :
Работа с отсутствующими данными при сортировке в Pandas ↑
Часто данные реального мира имеют много недостатков. Хотя у pandas есть несколько методов, которые можно использовать для очистки данных перед сортировкой, иногда приятно увидеть, какие данные отсутствуют во время сортировки. Это можно сделать с помощью параметра .
Подмножество данных об экономии топлива, используемое в этом руководстве, не имеет пропущенных значений. Чтобы проиллюстрировать использование , сначала нужно создать некоторые недостающие данные. Следующий фрагмент кода создает новый столбец на основе существующего столбца , сопоставляя , где равно и , где это не так:
>>> df = df.map({"Y": True})
>>> df
city08 cylinders fuelType ... trany year mpgData_
0 19 4 Regular ... Manual 5-spd 1985 True
1 9 12 Regular ... Manual 5-spd 1985 NaN
2 23 4 Regular ... Manual 5-spd 1985 True
3 10 8 Regular ... Automatic 3-spd 1985 NaN
4 17 4 Premium ... Manual 5-spd 1993 NaN
.. ... ... ... ... ... ... ...
95 17 6 Regular ... Automatic 3-spd 1993 True
96 17 6 Regular ... Automatic 4-spd 1993 NaN
97 15 6 Regular ... Automatic 4-spd 1993 NaN
98 15 6 Regular ... Manual 5-spd 1993 NaN
99 9 8 Premium ... Automatic 4-spd 1993 NaN
Теперь у вас есть новый столбец с именем , который содержит значения и . В этом столбце вы увидите, какой эффект дает при использовании двух методов сортировки. Чтобы узнать больше об использовании , вы можете прочитать Pandas Project: Make Gradebook With Python & Pandas.
Значение параметра na_position в .sort_values()
принимает параметр с именем , который помогает упорядочить недостающие данные в столбце, по которому выполняется сортировка. Если сортируется столбец с отсутствующими данными, то строки с отсутствующими значениями появятся в конце . Это происходит независимо от того, выполнятся ли сортировка по возрастанию или по убыванию.
Вот как выглядит DataFrame при сортировке по столбцу с отсутствующими данными:
>>> df.sort_values(by="mpgData_")
city08 cylinders fuelType ... trany year mpgData_
0 19 4 Regular ... Manual 5-spd 1985 True
55 18 6 Regular ... Automatic 4-spd 1993 True
56 18 6 Regular ... Automatic 4-spd 1993 True
57 16 6 Premium ... Manual 5-spd 1993 True
59 17 6 Regular ... Automatic 4-spd 1993 True
.. ... ... ... ... ... ... ...
94 18 6 Regular ... Automatic 4-spd 1993 NaN
96 17 6 Regular ... Automatic 4-spd 1993 NaN
97 15 6 Regular ... Automatic 4-spd 1993 NaN
98 15 6 Regular ... Manual 5-spd 1993 NaN
99 9 8 Premium ... Automatic 4-spd 1993 NaN
Чтобы изменить это поведение и чтобы недостающие данные сначала отображались в DataFrame, надо установить в значение . Параметр принимает только значения , которые являются значениями по умолчанию, или . Вот как использовать в :
>>> df.sort_values(
... by="mpgData_",
... na_position="first"
... )
city08 cylinders fuelType ... trany year mpgData_
1 9 12 Regular ... Manual 5-spd 1985 NaN
3 10 8 Regular ... Automatic 3-spd 1985 NaN
4 17 4 Premium ... Manual 5-spd 1993 NaN
5 21 4 Regular ... Automatic 3-spd 1993 NaN
11 18 4 Regular ... Automatic 4-spd 1993 NaN
.. ... ... ... ... ... ... ...
32 15 8 Premium ... Automatic 4-spd 1993 True
33 15 8 Premium ... Automatic 4-spd 1993 True
37 17 6 Regular ... Automatic 3-spd 1993 True
85 17 6 Regular ... Automatic 4-spd 1993 True
95 17 6 Regular ... Automatic 3-spd 1993 True
Теперь любые недостающие данные из столбцов, которые использовались для сортировки, будут отображаться в верхней части DataFrame. Это особенно полезно при начале анализа своих данные, когда нет уверенности в том, есть ли пропущенные значения.
Описание параметра na_position в .sort_index()
также принимает . Обычно, DataFrame не имеет значений как часть индекса, поэтому этот параметр менее полезен в . Однако полезно знать, что если DataFrame действительно имеет в индексе строки или имени столбца, то можно быстро определить это с помощью и .
По умолчанию для этого параметра установлено значение , что помещает значения в конец отсортированного результата. Чтобы изменить это поведение и сначала сохранить недостающие данные в фрейме данных, установите для параметра значение .
When to Use sorted() and When to Use .sort()
You’ve seen the differences between and , but when do you use which?
Let’s say there is a 5k race coming up: The First Annual Python 5k. The data from the race needs to be captured and sorted. The data that needs to be captured is the runner’s bib number and the number of seconds it took to finish the race:
>>>
As the runners cross the finish line, each will be added to a list called . In 5k races, not all runners cross the starting line at the same time, so the first person to cross the finish line might not actually be the fastest person:
>>>
Each time a runner crosses the finish line, their bib number and their total duration in seconds is added to .
Now, the dutiful programmer in charge of handling the outcome data sees this list, knows that the top 5 fastest participants are the winners that get prizes, and the remaining runners are going to be sorted by fastest time.
There are no requirements for multiple types of sorting by various attributes. The list is a reasonable size. There is no mention of storing the list somewhere. Just sort by duration and grab the five participants with the lowest duration:
>>>
The programmer chooses to use a in the argument to get the attribute from each runner and sort in place using . After is sorted, the first 5 elements are stored in .
Mission accomplished! The race director comes over and informs the programmer that since the current release of Python is 3.7, they have decided that every thirty-seventh person that crossed the finish line is going to get a free gym bag.
At this point, the programmer starts to sweat because the list of runners has been irreversibly changed. There is no way to recover the original list of runners in the order they finished and find every thirty-seventh person.
If you’re working with important data, and there is even a remote possibility that the original data will need to be recovered, then is not the best option. If the data is a copy, of if it is unimportant working data, of if no one will mind losing it because it can be retrieved, then can be a fine option.
Alternatively, the runners could have been sorted using and using the same :
>>>
In this scenario with , the original list of runners is still intact and has not been overwritten. The impromptu requirement of finding every thirty-seventh person to cross the finish line can be accomplished by interacting with the original values:
>>>
is created by using a stride in the list slice syntax on , which still contains the original order in which the runners crossed the finish line.
Python sort list of dictionaries
When sorting dictionaries, we can choose the property by which the sorting
is performed.
sort_dict.py
#!/usr/bin/env python3
users =
users.sort(reverse=True, key=lambda e: e)
for user in users:
print(user)
We have a list of users. Each user is represented by a dictionary.
users.sort(reverse=True, key=lambda e: e)
In the anonymous function, we choose the property.
$ ./sort_dict.py
{'name': 'Lucia Smith', 'date_of_birth': 2002}
{'name': 'Jane Doe', 'date_of_birth': 1996}
{'name': 'Patrick Dempsey', 'date_of_birth': 1994}
{'name': 'John Doe', 'date_of_birth': 1987}
{'name': 'Robert Brown', 'date_of_birth': 1977}
The users are sorted by their date of birth in descending order.
Operator Module Functions
The key-function patterns shown above are very common, so Python provides convenience functions to make accessor functions easier and faster. The has itemgetter, attrgetter, and starting in Python 2.6 a methodcaller function.
Using those functions, the above examples become simpler and faster.
>>> from operator import itemgetter, attrgetter, methodcaller
>>> sorted(student_tuples, key=itemgetter(2))
>>> sorted(student_objects, key=attrgetter('age'))
The operator module functions allow multiple levels of sorting. For example, to sort by grade then by age:
>>> sorted(student_tuples, key=itemgetter(1,2))
>>> sorted(student_objects, key=attrgetter('grade', 'age'))
The third function from the operator module, methodcaller is used in the following example in which the weighted grade of each student is shown before sorting on it:
>>>
>>> sorted(student_objects, key=methodcaller('weighted_grade'))
The Old Way Using the cmp Parameter
Many constructs given in this HOWTO assume Python 2.4 or later. Before that, there was no sorted() builtin and list.sort() took no keyword arguments. Instead, all of the Py2.x versions supported a cmp parameter to handle user specified comparison functions.
In Py3.0, the cmp parameter was removed entirely (as part of a larger effort to simplify and unify the language, eliminating the conflict between rich comparisons and the __cmp__ methods).
In Py2.x, sort allowed an optional function which can be called for doing the comparisons. That function should take two arguments to be compared and then return a negative value for less-than, return zero if they are equal, or return a positive value for greater-than. For example, we can do:
>>> def numeric_compare(x, y):
return x - y
>>> sorted(, cmp=numeric_compare)
Or you can reverse the order of comparison with:
>>> def reverse_numeric(x, y):
return y - x
>>> sorted(, cmp=reverse_numeric)
When porting code from Python 2.x to 3.x, the situation can arise when you have the user supplying a comparison function and you need to convert that to a key function. The following wrapper makes that easy to do:
def cmp_to_key(mycmp):
'Convert a cmp= function into a key= function'
class K(object):
def __init__(self, obj, *args):
self.obj = obj
def __lt__(self, other):
return mycmp(self.obj, other.obj) < 0
def __gt__(self, other):
return mycmp(self.obj, other.obj) > 0
def __eq__(self, other):
return mycmp(self.obj, other.obj) == 0
def __le__(self, other):
return mycmp(self.obj, other.obj) <= 0
def __ge__(self, other):
return mycmp(self.obj, other.obj) >= 0
def __ne__(self, other):
return mycmp(self.obj, other.obj) != 0
return K
To convert to a key function, just wrap the old comparison function:
>>> sorted(, key=cmp_to_key(reverse_numeric))
In Python 2.7, the cmp_to_key() tool was added to the functools module.