3 лучших расширения яндекс wordstat
Содержание:
- Yandex Wordstat Helper
- Дополнительные операторы
- Ключевые идеи статьи
- Особенности учета словоформ Вордстата
- Как проверить частотность запроса
- Сервисы для группировки ключевых слов
- Как пользоваться Wordstat Yandex
- Находим упущенные ключевые слова
- Составление масок для парсинга
- Очистка СЯ от «мусора»
- Расширения для браузера Яндекс Wordstat
- Парсим запросы из поисковой выдачи или сайтов конкурентов
- Как правильно пользоваться Вордстатом
Yandex Wordstat Helper
Установите этот плагин – принцип тот же, что и с Wordstat Assistant:
2) Нажмите кнопку для установки:
3) Подтвердите, что собираетесь установить расширение:
Когда установка завершена, вы увидите:
Значок с таким уведомлением – теперь он всегда будет отображаться в вашем браузере.
Если такого значка нет, попробуйте перезапустить браузер.
Панель управления Wordstat Helper в левой области страницы Яндекс Wordstat – в неё будут попадать все ключевые фразы, которые вы добавите.
На случай, если панель не появится, обновите страницу или также перезапустите браузер.
Знак «+» напротив каждого результата и в левой, и в правой колонке – он нужен, чтобы добавлять фразы в список.
Чтобы его увидеть, введите нужную фразу, как обычно в Вордстате, например:
По функционалу Wordstat Helper практически не отличается от Wordstat Assistant
Поэтому рассмотрим чисто визуально, куда нажимать, чтобы выполнить определенную функцию:
1) Добавление собственных ключей:
Один нюанс, отличающий от Wordstat Assistant: вы можете добавлять собственные ключевые фразы только по одной в этом всплывающем окне:
2) Сортировка списка ключевых фраз: также по алфавиту, порядку добавления и частотности запросов:
3) Копирование данных из Вордстата: списка фраз или списка фраз с частотностью (значок с «глазом»):
4) Очистка списка:
5) Добавление / удаление всех слов из списка:
Обратите внимание, здесь более гибкая возможность, чем в Wordstat Assistant. Вы можете не только добавить все слова с текущей вкладки, но и удалить те, что добавили с текущей вкладки
При этом удалятся все, кроме тех, которые вы добавили вручную.
Однако есть некоторые мелкие детали, которые отсутствуют в этом расширении:
- Выбранные фразы из результатов поиска не высвечиваются серым цветом;
- Нет функции удаления знака «+» из фраз при копировании;
- Нельзя добавлять собственные ключи списком;
- Есть версия только для Google Chrome.
Дополнительные операторы
Есть еще 5 основных вспомогательных операторов, открывающих еще больше возможностей в Яндекс Вордстат:
- Оператор «Плюс». Для его использования указывается символ +. Он помогает отыскать поисковые запросы, где есть стоп-слова, такие как союзы, предлоги и т.п.
- Оператор «Квадратные скобки». Применяются символы с написанием между ними ключевой фразы. С его помощью фиксируется расстановка слов во фразе, то есть, они остаются в таком порядке, как вы их прописали. Оператор актуален тогда, когда нужно проанализировать популярность схожих фраз по различным запросам.
- Оператор «Или». Используется с помощью символа | и важен для оперативного подбора семантики на веб-страницу, а также в процессе сравнения или «смещения» в статистике некоторых фраз.
- Оператор «Минус». Для его применения прописывается символ -. Он убирает при необходимости запросы, содержащие ненужные для изучения статистики слова.
- Оператор «Группировка». Указываются символы ( ), внутри которых прописываются вышеперечисленные операторы, чтобы использовать их вместе.
Ключевые идеи статьи
1. Не ограничивайтесь самыми очевидные ключевыми словами! Подберите релевантные, но нестандартные формулировки, которые принесут вам недорогие клики и конверсии.
2
Уделяйте большое внимание минус-словам. Чем полнее и ваш список минус-слов, тем меньше нецелевых показов и кликов получите
3. Информационные запросы используйте только если есть подходящие посадочные страницы для них. Генерировать прямые продажи по инфо-запросам будет сложно.
4. Пользы от больших семантических ядер нет. Для большинства кампаний несколько десятков или сотен запросов вполне достаточно, чтобы получить релевантный трафик по максимально низкой цене.
Если же у вас возникли трудности с подбором ключевых запросов для Яндекс Директ или Google Рекламы, или другие проблемы при запуске или ведении кампаний, обращайтесь к нашим специалистам.
Особенности учета словоформ Вордстата
Объединение словоформ. Фразы считаются словоформами, если это:
- Склонения числительных падежам (три, трех, трем, тремя);
- Склонения существительных по падежам и числам (слон, слоны, слонами, слонов);
- Изменения суффиксов у глаголов (бежать, бежит);
- Причастия, деепричастия, глаголы и их спряжения (просмотреть, просмотрел, просмотревший, просмотренный);
- При изменении «ё» на «е» и наоборот (елка,ёлка);
- Числа, падежи, форма и степень прилагательных (высокий, выше, высочайший).
В некоторых случаях количество запросов может отличаться из-за учета фраз, характерных только для одной из них:

Например, слово «тертый» появляется при поиске по запросу «три», но не показывается по запросу «трех». Не стоит забывать, что эта особенность характерна только для общей (базовой) частотности. Чтобы получить точное значение необходимо использовать оператор «точное вхождение» (восклицательный знак).
Разделение словоформ. Фразы не считаются словоформами, если это:
- Ошибки в словах (витамины, ветамины);
- Синонимы (чашка, кружка, стакан);
- Сленг или жаргон (препод, преподаватель);
- Транслитерация (яндекс, yandex);
- Сложносоставные слова (электроинструмент, электро инструмент);
- Глаголы, образованные за счет приставок (ехать, приехать, заехать);
- Уменьшительно-ласкательные формы (машина, машинка);
- Существительные, имеющие разный род (собака, пес);
- Числительные с одним значение, но разным написанием (10, десять, десятый);
Как проверить частотность запроса
Частотность ключевых слов можно узнать с помощью соответствующих сервисов поисковых систем, а также специальных программ по составлению семантического ядра. Поисковики предоставляют свои сервисы с расчетом подбора запросов для контекстной рекламы.
Wordstat (Яндекс)
Wordstat — cервис Яндекса по определению статистики ключевых запросов. Вордстат использует большинство оптимизаторов не только в целях составления коммерческих запросов под рекламу, но и для добычи ключевых слов в рамках обычной текстовой оптимизации. У Вордстата выделяют три вида частотностей:
- Частотность WS — базовая частотность запроса в Вордстате.
- Частотность «» WS — частотность по точному вводу запроса. Например, статистика по запросу будет соответствовать запросу без добавлений других слов.
- Частотность «!» WS — частотность по точному вводу каждого слова в запросе, исключая склонения и т.п. Запрос означает, что будет выдана статистика по слову без возможных склонений (китайская, китайское).
По запросу текущая частотность превышает десять миллионов показов. Однако базовый показатель предполагает добавление всевозможных слов к ключевому слову, по которым будет ранжироваться статья.
Сервис Google AdWords сам по себе более заточен под контекстную рекламу, нежели Вордстат. В разделе «Инструменты» можно подобрать необходимые ключи под нужный запрос. В колонке «Таргетинг» задается нужный регион показов и язык. Также можно указывать минус-слова.
- Ключевые слова — аналог частотности «» Вордстата;
- Ключевые слова (по релевантности) — аналог базовой частотности и похожих запросов WS.
Плюсами являются присутствие уровня конкурентности, а также возможность скачать подобранные слова в CSV-файл или на Гугл Диск.
Помимо AdWords, Гугл имеет еще один инструмент по анализу запросов под названием Google Trends. Данный сервис оценивает популярность введенного запроса на определенный период времени и представляет статистику в виде графика. Можно сравнивать несколько ключевых запросов между собой. Также отображается статистика по регионам.
Mail.ru
Mail.ru также имеет в сервисе для вебмастеров инструмент по статистике поисковых запросов. Помимо общих показов, в таблице представлены распределение запросов по полу и возрасту пользователей.
Rambler
Rambler с каждым годом теряет свою популярность, однако их Wordstat может оказаться весьма полезным. Дело в том, что статистика запросов в Яндексе и Гугле не всегда может отображать реальное положение вещей. Многие компании могут вводить «в холостую» коммерческие запросы в целях слежки за конкурентами, т.е. для анализа ТОПа, тайтлов и т.д.
По причине низкой популярности Рамблера, статистика их Вордстата обладает меньшей заспамленностью и может внести некоторую ясность для оптимизаторов. В общем, в качестве дополнительного инструмента вполне сгодится.
Сервисы для группировки ключевых слов
- rush-analytics.ru — сбор Яндекс.Вордстат, подсказок и автоматическая кластеризация запросов;
- seo-case.com — автоматическая группировка ключевых слов;
- just-magic.org — автоматический подбор и группировка ключевых слов;
- engine.seointellect.ru — автоматическая группировка ключевых слов;
- coolakov.ru — автоматическая группировка ключевых слов;
- semparser.ru — структуризация семантики для SEO и контекста, обсуждение;
- stoolz.ru — сервис кластеризации запросов, обсуждение;
- mc-castle.ru — кластеризация запросов, обсуждение;
- kg.ppc-panel.ru — ручная группировка ключевых запросов;
- zapros.binet.pro — группировка ключевых слов для информационных сайтов от puzat.ru;
- mykeywords.ru — сервис по кластеризации ключевых слов на основе частотного анализа, обсуждение.
- art.monica.pro — сервис Артикластер для группировки ключевых фраз и подготовки ТЗ для авторов, обсуждение.
Как пользоваться Wordstat Yandex
Чтобы начать работать с сервисом, нужно авторизоваться в системе или создать новый аккаунт Яндекса.
Затем в строку поиска введите слово или фразу, по которой пользователи могут найти предложение и нажмите «Подобрать». Это нужно сделать во вкладке «По словам».
Слева в результатах подбора вы увидите рейтинг запросов, которые пользователи вводили в поиске Яндекса. По умолчанию показываются данные для всех регионов и любого типа устройств. Цифры рядом с каждым запросом — это прогноз количества показов в месяц, которое будет получать сайт, если вы выберете эту фразу или слово в качестве ключевого. При подборе слов Яндекс учитывает все формы слова.
Справа отображается статистика по запросам, похожим по смыслу на заданную фразу. Оцените данные по похожим запросам, и, если они подходят, включите их в список ключевых слов.
Находим упущенные ключевые слова
Собрать все ключи и объявления конкурентов полезно для общего анализа и понимания ситуации
Но если у вас уже запущены рекламные кампании, важно понимать другое: какие слова используют ваши конкуренты, а вы — нет
Как это сделать
1. Подготовьте список ключевых слов, по которым у вас запущена реклама.
2. Перейдите в инструмент «Слова и объявления конкурентов». Укажите домены конкурентов (которые хотите спарсить). В блоке профессиональных настроек вставьте ключи в поле «Минус-слова».
Все слова, добавленные в поле «Минус-слова», система исключит при парсинге. В результатах будут только те ключи, которые вы еще не использовали.
3. Запустите парсинг и скачайте результаты. На выходе вы получите готовый набор ключей, с помощью которого можете расширить семантику.
Составление масок для парсинга
Начинаем подбор ключевых запросов с составления запросов для парсинга. Чаще всего это 2-словные, но иногда и 3-словные запросы, которые также называют «масками».
Эти запросы должны максимально коротко, но релевантно описывать ваши услуги или товары.
Предположим, вы предлагаете доставку еды. Подходящими для вас масками будут:
– доставка еды – еда на дом – еда в офис – заказать еду – доставка обедов и т. д.
В зависимости от ассортимента, вам также нужно охватить более точные запросы, например: доставка плова, заказать суши и т. д.
Вам интересны интернет-маркетинг и продвижение бизнеса в интернете? Подписывайтесь на наш Telegram-канал!
Как правильно составить маски запросов?
Не стоит пренебрегать данным этапом сбора семантического ядра (СЯ), так как от него зависит полнота СЯ, охват кампании, средняя цена за клик, количество и стоимость конверсий.
Неопытные специалисты часто используют только самые очевидные запросы. И хотя они охватывают большую часть целевой аудитории, по этим запросам самая высокая конкуренция и, как следствие, цена клика.
Чтобы собрать максимальное количество непересекающихся запросов, используйте:
- Брейншторминг. Просто подумайте, с помощью каких запросов ваша целевая аудитория может искать ваши товары или услуги.
- Правая колонка Yandex Wordstat. У Яндекса большой объем статистики, что и как ищут пользователи, и часто предлагает хорошие варианты ключевых фраз, до которых мы сами не додумались бы. Этот способ подходит и для сбора семантического ядра под Google;
- Блок «Вместе с этим ищут» на поиске Google и Яндекс. Работает по той же логике, что и правая колонка Wordstat — показывает, какие еще запросы вводят пользователи, которые ищут по определенному запросу.
- Сайты конкурентов. Просмотрите сайты ваших топ 5-10 конкурентов в Google и Яндекс. Подходящие нам ключевые запросы часто можно обнаружить в заголовках или в тексте на продвигаемых страницах.
- Названия конкурентов. В некоторых нишах, при правильном подходе, хорошие результаты показывает реклама на бренд конкурентов. Например, если вы занимаетесь доставкой пиццы, то в качестве ключевых фраз можете попробовать использовать « додо пицца» или «доминос».
- Ключевые слова конкурентов. Есть специальные сервисы конкурентного анализа, которые предлагают показать, какие запросы используют ваши конкуренты. Точность этих сервисов оставляет желать лучшего, но иногда помогают найти новые, релевантные запросы. Мы пользуемся keys.so, как недорогим и достаточно функциональным сервисом.
- Нестандартные формулировки, транслитерация, сленг. Иногда один и тот же бренд люди пишут по разному и, чтобы охватить их, нам нужно использовать все эти варианты в качестве ключевых слов. Например, вы продаете запчасти для автомобилей Hyundai. Чтобы охватить целевую аудиторию полностью, в вашем семантическом ядре должны использоваться слова: Хундай, Хендай, Хёндай, Хюндай, Хьюндай.
Блок «Вместе с этим ищут» в Яндексе
Правая колонка Яндекс Вордстат с рекомендациями ключевых слов
Очистка СЯ от «мусора»
Покажем, как это делать в Key Collector.
Ключевики, которые содержат ненужные слова
Нажимаем вкладку выбора условий фильтрации:
Задаем условие, как указано на скриншоте, и пишем слова:
Отмечаем фразы и добавляем в корзину:
Повторы слов
Аналогично вызываем настройки фильтрации фраз и выбираем такой вариант:
Стоп-слова (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.)
Нажимаем этот значок в верхнем меню:
В окне настроек добавляем фразы (1) и разбиваем по группам (2):
Далее — выделяем слова в таблице галочкой и добавляем в список стоп-слов.
Группы слов
Чтобы разбить запросы на группы, на вкладке «Данные» открываем «Анализ групп». В окне выбираем тип «По отдельным словам»:
Выбранные группы появятся в основном списке запросов, где можно отсеять все ненужные.
Запросы с нулевой частотностью
Выбираем следующее условие фильтрации:
Далее — требования по частоте:
Можно удалить нецелевые запросы и вручную: копируем ключевики в Word. Заменяем пробел на знак абзаца, чтобы представить все слова из словосочетаний в виде колонки. Переносим обратно в Excel на отдельный лист, сортируем и определяем минус-слова. Затем находим с помощью фильтра фразы с ними и удаляем.
На какие вопросы машинный интеллект не дает ответы
Сбор семантики быстрее и проще с помощью различных сервисов, баз, приложений — благо, выбор есть. Однако нельзя слепо полагаться на автоматизацию. Есть два случая, когда без ручного труда не обойтись.
Уже при подборе масок нужно «вытаскивать» синонимы и переформулировки из сайтов заказчика и конкурентов, правой колонки Wordstat, собственных идей и т.д. Мы увидели, что это всё предстоит делать специалисту по контекстной рекламе.
Самый трудозатратный и не автоматизируемый процесс — очистка СЯ от «мусора». Готовых минус-списков и данных об отказах из Яндекс.Метрики недостаточно для 100% точности. Приходится смотреть предварительные списки и выявлять смысловое соответствие результатов бизнесу.
Особенно это касается сложных продуктов. Например, подготовка сжатого воздуха, или осушка воздуха. Больше расширений можно насобирать по слову «осушка».
Но среди результатов в Wordstat в мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Не всегда семантическое соответствие гарантирует смысловое соответствие. Это разные продукты, а значит, разный спрос. Чаще всего выявить и исключить его можно только вручную.
Если вы не проверяете результаты парсинга, вы жертвуете полнотой СЯ и точностью будущих рекламных кампаний. Совет: выбирайте оптимальный баланс «трудозатраты — полнота» и делайте полный список минус-слов.
Расширения для браузера Яндекс Wordstat
Использовать Яндекс Wordstat по старинке, то есть копипастить подходящие запросы – вчерашний день. Использование бесплатных расширений для браузера дает гораздо больше возможностей.
Рассмотрим основные из них на примере плагина Wordstat Assistant. После установки его панель управления находится в левой области страницы Яндекс Wordstat.

Итак, плагины Вордстата позволяют:
1) Формировать собственный список ключей, отбирая из выдачи Вордстата нужные в пару кликов.
Знаком «+» около каждого результата вы добавляете фразу в свой список. Кликом по кнопке «Добавить все» – все фразы со страницы выдачи, на которой сейчас вы находитесь:

Удалить фразы можно из результатов поиска Яндекс Wordstat (1) или прямо из панели управления (2). Либо крестиком вверху панели управления (3), если нужно очистить весь список:
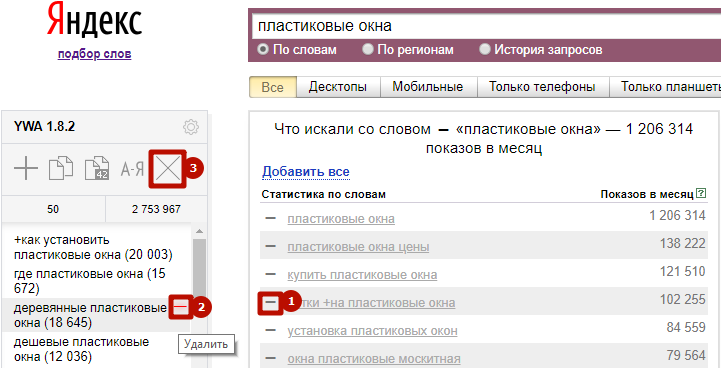
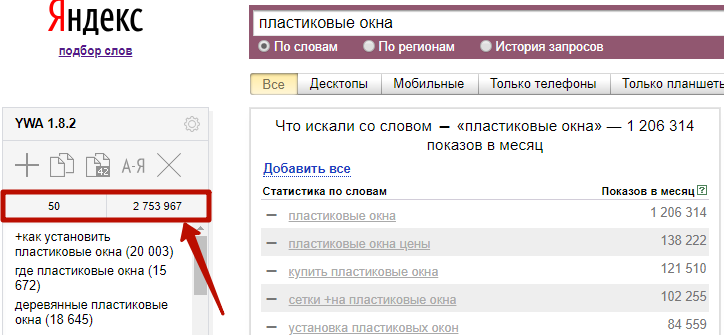
2) Видеть автоматически рассчитанное количество фраз и частотность по списку благодаря встроенным счетчикам;
3) Добавлять собственные ключи:
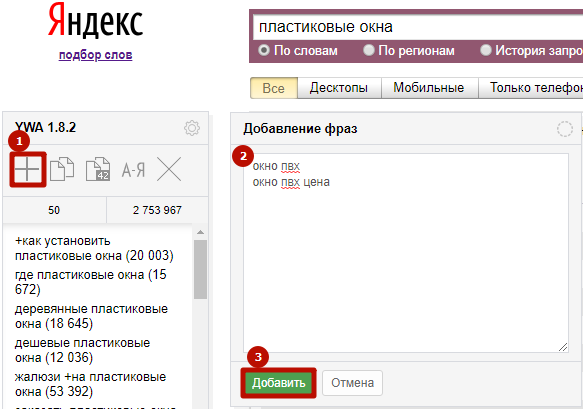
Правда, частотность для них не подтягивается из данных Вордстата, а обозначается знаком вопроса.
4) Сортировать список ключей по частотности, алфавиту и порядку добавления.
5) Сохранять список в аккаунте Яндекса и редактировать при повторном открытии.
Более сложный плагин – WordStater. Он поддерживает все базовые функции, плюс свои уникальные вещи.
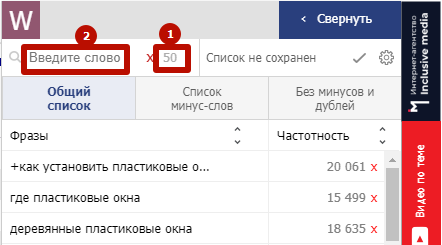
WordStater включает три вкладки:
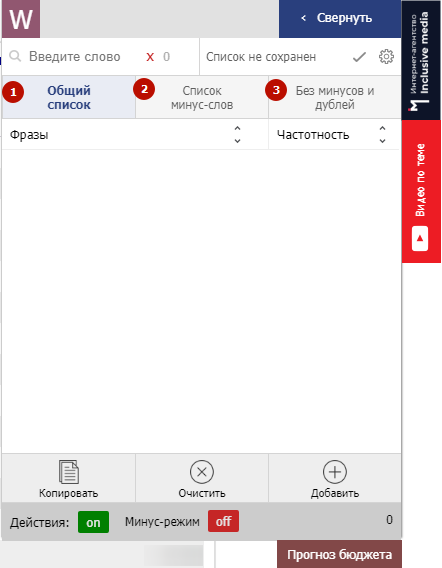
1) Общий список из результатов Wordstat;
2) Список минус-слов;
3) Без минусов и дублей – список фраз, отфильтрованный от минус-слов.
В верхней строке плагина вы видите общее количество собранных фраз (1) и можете найти конкретную фразу в списке (2):
Теперь – об уникальных возможностях WordStater, связанных со сбором семантики.
1) Полуавтоматический сбор – с помощью специальных горячих клавиш:
- Ctrl+Shift+A – для добавления ключей с текущей страницы;
- Ctrl+Shift+(стрелка вправо) – со следующей, и т.д.
Так вы быстрее соберете много фраз, однако есть риск «схватить» за это капчу.
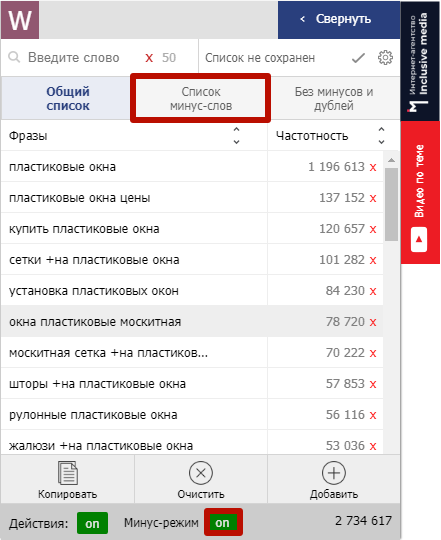
2) Исключение из выдачи Вордстата ранее минус-слов, заданных вручную или собранных из выдачи.
Активируйте минусацию, откройте вкладку «Сбор минус-слов»:
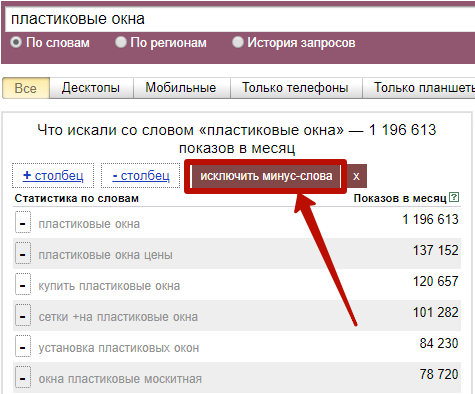
Или исключите слова прямо в выдаче Вордстата:
3) Генерация ключевых фраз в «Комбинаторе слов»:
Работает она по принципу перемножения:

Подробнее об этих и других возможностях расширений Яндекс Вордстат смотрите здесь.
Парсим запросы из поисковой выдачи или сайтов конкурентов
Теперь самое интересное, надо составить семантическое ядро, то есть подготовить список запросов (поисковых фраз), которые вводят люди в поиске, где в будущем должны будут находить вашу площадку.
Собирать запросы сейчас можно огромным количеством способов, но все они сводятся к трем критериям:
- Парсинг бесплатной статистики Wordstat.
- Парсинг собственных баз специальных сервисов.
- Анализ конкурентов.
Wordstat
Больше всего ключевые слова подбирают по данным предоставляемым самим Яндексом, с помощью бесплатного сервиса wordstat.yandex.ru.
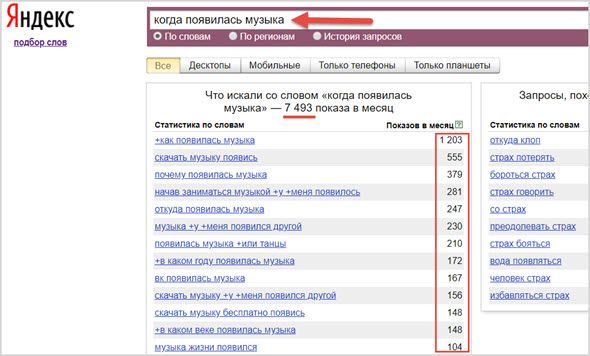
Однако, фильтровать там запросы очень сложно, результаты отображаются только по 50 штук на странице и нет возможности что-либо сортировать или скачивать.
Подробнее о том, какие есть операторы в Вордстате и как их применять на практике смотрите по указанной ссылке.
Базы ключевых слов
Со временем появились сайты, где предлагается купить готовые запросы по различным тематикам и странам.
Думаю все слышали про Мутаген, Букварикс и другие сервисы, где в одном месте собраны миллиарды ключей.
Глупо будет скрывать тот факт, что там присутствуют те же запросы, что вы можете сами спарсить через Вордстат.
Запросы конкурентов
И еще одни популярный метод, которым даже я пользуюсь называется «украсть запросы конкурента». Суть его очень проста, находите трафиковый сайт с такой же тематикой что и ваш и с помощью специальных сервисов скачиваете все ключевые слова по которым он ранжируется в Яндекс и Google.
Лидерами в этом направлении стали:
- SEMrush
- SpyWords
- Mutagen
- Serpstat
- MOAB
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис, вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:

После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:

Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
Давайте теперь смотреть остальные функции интерфейса:

В блоке 1 — переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.В блоке 2 — очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.В блоке 3 — дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.В блоке 4 — выбираем регион/регионы.
По регионам
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:

А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:

История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:

Но самое профессиональное начинается, когда вы работаете с операторами.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».

С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.

С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.

А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».

Вспомогательные операторы
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:

Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:

Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.

Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».

Круглые скобки «()» — группирует использование нескольких операторов.

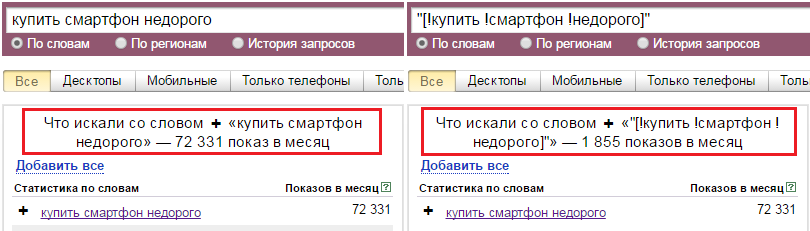
Квадратные скобки «[]» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:

Как видим, с неправильным порядком фразу почти никто не вводит: