Иерархические данные (sql server)hierarchical data (sql server)
Содержание:
- Объектно-ориентированные субд
- Язык описания данных иерархической модели
- §3.3. Иерархическая модель данных§3.4. Сетевая модель данных
- Сетевая модель базы данных
- Недостатки
- Структура реляционной модели данных
- Иерархические
- Сетевая модель данных
- Основные свойства типа hierarchyidKey Properties of hierarchyid
- Операторы поиска данных
- Основные понятия
- Состав частей реляционной модели данных
- Главное о базах данных
- Проектирование реляционной базы данных. Преобразование модели в реляционную
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Язык описания данных иерархической модели
В рамках
иерархической модели выделяют языковые средства описания данных (DDL, Data Definition
Language) и средства манипулирования данными (DML, Data Manipulation Language).
Каждая физическая
база описывается набором операторов, определяющих как ее логическую структуру,
так и структуру хранения БД. Описание начинается с оператора определения базы — DBD (Data Base
Definition):
DBD Name = <
имя БД>, ACCESS = < способ доступа>
Способ доступа
определяет способ организации взаимосвязи физических записей.
Определено 5 способов доступа:
HSAM
—
hierarchical sequential access method (иерархически
последовательный метод),
HISAM
—
hierarchical index sequential access method
(иерархически индексно-последовательный метод),
EDAM
—
hierarchical direct access method (иерархически прямой метод),
HID AM
—
hierarchical index direct access method (иерархически индексно-прямой метод),
INDEX
—
индексный метод.
Далее идет
описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = < имя оператора, определяющего хранимый набор данных>. DEVICE =< устройство хранения БД>,
Так как физические записи имеют разную длину, то при модификации данных запись может увеличиться
и превысит исходную длину записи до модификации. В этом случае при определенных
методах хранения может понадобиться дополнительное пространство хранения, где
и будут размещены дополнительные данные. Это пространство и называется областью
переполнения.
После описания
всей физической БД идет описание типов сегментов, ее составляющих, в соответстшш
с иерархией. Описание сегментов всегда начинается с описания корневого сегмента.
Общая схема описания типа сегмента такова:
SEGM NAME =
< имя сегмента>. BYTES =< размер в байтах>.
FREQ = <средняя
частота реализаций сегмента под одним исходным>
PARENT = <имя
родительского сегмента>
Параметр
FREQ определяет среднее количество экземпляров данного сегмента, связанных с
одним экземпляром родительского сегмента. Для корневого сегмента это число возможных
экземпляров корневого сегмента.
Для корневого
сегмента параметр PARENT равен 0 (нулю). Далее для каждого сегмента дается описание
полей:
FIELD NAME =
{(<имя поля> .{U M}) | <имя поля> }.
START = <
номер байта, с которого начинается значения поля >,
BYTES = <размер
поля в байтах>,
TYPE = {X |
Р | С}
Признак SEQ
— задается для ключевого поля, если экземпляры данного сегмента физически упорядочены
в соответствии со значениями данного поля.
Параметр
U задается, если значения ключевого поля уникальны для всех экземпляров данного
сегмента, М — в противном случае. Если поле является ключевым, то его описание
задается в круглых скобках, в противном случае имя поля задается без скобок.
Параметр TYPE определяет тип данных. Для ранних иерархических моделей были определены
только три типа данных: X — шестпадцатеричиый, Р —упакованный десятичный, С
— символьный.
Заканчивается
описание схемы вызовом процедуры генерации:
- DBDGEN — указывает
на конец последовательности управляющих операторов описания БД; - FINISH — устанавливает
ненулевой код завершения при обнаружении ошибки; - END — конец.
В системе
может быть несколько физических БД (ФБД), но каждая из них описывается отдельно
своим DBD и ей присваивается уникальное имя. Каждая ФБД содержит только один
корневой сегмент. Совокупность ФБД образует концептуальную модель данных.
§3.3. Иерархическая модель данных§3.4. Сетевая модель данных
Иерархическая базы данных «Доменная система имен»
Еще одним примером иерархической базы данных является доменная система имен подключенных к Интернету компьютеров. На верхнем уровне находится табличная база данных, содержащая перечень доменов верхнего уровня (всего 269 домена), из которых 12 — административные, а остальные 257 — географические. Наиболее многочисленным доменом (данные на январь 2008 года) является административный домен net (около 190 миллионов серверов), а некоторых доменах (например, в географическом домене zr) до сих пор не зарегистрировано ни одного сервера.
На втором уровне находятся табличные базы данных, содержащие перечень доменов второго уровня для каждого домена первого уровня.
На третьем уровне могут находиться табличные базы данных, содержащие перечень доменов третьего уровня для каждого домена второго уровня и таблицы, содержащие IP-адреса компьютеров, находящихся в домене второго уровня.
Рис. 3.3. Иерархическая база данных Доменная система имен
База данных «Доменная система имен» должна содержать записи обо всех компьютерах, подключенных к Интернету, т. е. более 500 миллионов записей. Размещение такой огромной базы данных на одном компьютере сделало бы поиск информации очень медленным и неэффективным. Решение этой проблемы было найдено путем размещения отдельных составных частей базы данных на различных DNS- серверах. Таким образом, иерархическая база данных «Доменная система имен» является распределенной базой данных.
Поиск информации в такой иерархической распределенной базе данных ведется следующим образом. Например, мы хотим ознакомиться с содержанием WWW-сервера фирмы Microsoft.
Сначала наш запрос, содержащий доменное имя сервера www.microsoft.com, будет оправлен на DNS-сервер нашего провайдера, который переадресует его на DNS-сервер самого верхнего уровня базы данных. В таблице первого уровня будет найден интересующий нас домен сот и запрос будет адресован на DNS-сервер второго уровня, который содержит перечень доменов второго уровня, зарегистрированных в домене сот.
В таблице второго уровня будет найден домен microsoft и запрос будет переадресован на DNS-сервер третьего уровня. В таблице третьего уровня будет найдена запись, соответствующая доменному имени, содержавшемуся в запросе. Поиск информации в базе данных «Доменная система имен» будет завершен и начнется поиск компьютера в сети по его IР-адресу.
Следующая страница §3.3. Иерархические базы данных. Контрольные вопросы
Cкачать материалы урока
Сетевая модель базы данных
Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
Недостатки
К основным недостаткам иерархических моделей следует отнести: неэффективность, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. Также недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Иерархические СУБД быстро прошли пик популярности, которая обусловливалась их ранним появлением на рынке. Затем их недостатки сделали их неконкурентоспособными, и в настоящее время иерархическая модель представляет исключительно исторический интерес.
Структура реляционной модели данных
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствованна соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формирую дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.
Иерархические
Иерархия — это когда есть вышестоящий, а есть его подчинённые, кто ниже. У них могут быть свои подчинённые и так далее. Мы уже касались такой модели, когда говорили про деревья и бустинг.
В такой базе данных сразу видно, к чему относятся записи, где они лежат и как до них добраться. Самый простой пример такой базы данных — хранение файлов и папок на компьютере:
Видно, что на диске C: есть много папок: Dropbox, eSupport, GDrive и все те, которые не поместились на экране.
Внутри папки GDrive есть ###_Inbox и #_Альбатрос, а внутри #_Альбатроса — десятки других папок. Если мы посмотрим на скриншот, то увидим, то должностная инструкция бухгалтера лежит с остальными файлами внутри папки Должностные и охрана труда, которая лежит внутри папки Инструкции.
Иерархическая база данных знает, кто кому подчиняется, и поэтому может быстро находить нужную информацию. Но такие базы можно организовать только в том случае, когда у вас есть чёткое разделение в данных, что главнее, а что ему подчиняется.
Сетевая модель данных
Стандарт
сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference
of Data System Languages), которая определила базовые понятия модели и формальный
язык описания.
Базовыми
объектами модели являются:
- элемент данных;
- агрегат данных;
- запись;
- набор данных,
Элемент данных
—
то же, что и в иерархической модели, то есть минимальная информационная
единица, доступная пользователю с использованием СУБД.
Агрегат данных
—
соответствует следующему уровню обобщения в модели. В модели определены
агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа.
Агрегат данных
имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа
вектор соответствует линейному набору элементов данных. Например, агрегат Адрес
может быть представлен следующим образом:
|
Адрес |
|||
|
Город |
Улица |
дом |
квартира |
Агрегат типа
повторяющаяся группа соответствует совокупности векторов данных. Например, агрегат
Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
|
Зарплата |
|
|
Месяц |
Сумма |
Записью называется
совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов
реального мира. Понятие записи соответствует понятию «сегмент» в
иерархической модели. Для записи, так же как и для сегмента, вводятся понятия
типа записи и экземпляра записи.
Следующим
базовым понятием в сетевой модели является понятие «Набор».
Набор
—
это двухуровневый граф, связывающий отношением «один-ко-многим» два типа записи.
Набор фактически
отражает иерархическую связь между двумя типами записей. Родительский тип записи
в данном наборе называется владельцем набора, а дочерний тип записи — членом
того же набора.
Для любых
двух типов записей может быть задано любое количество наборов, которые их связывают.
Фактически наличие подобных возможностей позволяет промоделировать отношение
«многие-ко-многим» между двумя объектами реального мира, что выгодно
отличает сетевую модель от иерархической. В рамках набора возможен последовательный
просмотр экземпляров членов набора, связанных с одним экземпляром владельца
набора.
Между двумя
типами записей может быть определено любое количество наборов: например, можно
построить два взаимосвязанных набора. Существенным ограничением набора является
то, что один и тот же тип записи не может быть одновременно владельцем и членом
набора.
В качестве
примера рассмотрим таблицу, на основе которой организуем два набора и определим
связь между ними:
|
Преподаватель |
Группа |
День недели |
№ пары |
Аудитория |
Дисциплина |
||
|
Иванов |
4306 |
Понедельник |
1 |
22-13 |
КИД |
||
|
Иванов |
4307 |
Понедельник |
2 |
22-13 |
КИД |
||
|
Карпова |
4307 |
Вторник |
2 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
4309 |
Вторник |
4 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
84305 |
Вторник |
1 |
22-14 |
БД |
||
|
Смирнов |
4306 |
Вторник |
3 |
23-07 |
ГВП |
||
|
Смирнов |
4309 |
Вторник |
4 |
23-07 |
ГВП |
||
Экземпляров
набора Ведет занятия будет 3 (по числу преподавателей), экземпляром набора Занимается
у будет 4 (по числу групп). На рис. 3.6 представлены взаимосвязи экземпляров
данных наборов.
Рис.
3.6. Пример взаимосвязи экземпляров двух наборов
Среди всех
наборов выделяют специальный тип набора, называемый «Сингулярным набором»,
владельцем которого формально определена вся система. Сингулярный набор изображается
в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора,
но у которой не определен тип записи «Владелец набора». Например,
сингулярный набор М.
Сингулярные
наборы позволяют обеспечить доступ к экземплярам отдельных типов данных, поэтому
если в задаче алгоритм обработки информации предполагает обеспечение произвольного
доступа к некоторому типу записи, то для поддержки этой возможности необходимо
ввести соответствующий сингулярный набор.
В общем случае
сетевая база данных представляет совокупность взаимосвязанных наборов, которые
образуют на концептуальном уровне некоторый граф.
Основные свойства типа hierarchyidKey Properties of hierarchyid
Значение типа данных hierarchyid представляет позицию в древовидной иерархии.A value of the hierarchyid data type represents a position in a tree hierarchy. Значения hierarchyid обладают следующими свойствами.Values for hierarchyid have the following properties:
-
Исключительная компактностьExtremely compact
Среднее число бит, необходимое для представления узла в древовидной структуре с n узлами, зависит от среднего количества потомков у узла.The average number of bits that are required to represent a node in a tree with n nodes depends on the average fanout (the average number of children of a node). Для структур с низкой степенью ветвления (0-7) объем занимаемой памяти равен примерно 6*logA n бит, где A — среднее ветвление.For small fanouts, (0-7) the size is about 6*logA n bits, where A is the average fanout. Для представления узла в иерархии организации, насчитывающей 100 000 человек со средним уровнем ветвления 6, необходимо около 38 бит.A node in an organizational hierarchy of 100,000 people with an average fanout of 6 levels takes about 38 bits. Эта величина округляется до 40 бит (5 байт), которые необходимы для хранения.This is rounded up to 40 bits, or 5 bytes, for storage.
-
Сравнение проводится в порядке приоритета глубиныComparison is in depth-first order
Если заданы два значения hierarchyid — a и b, a<b означает, что значение a появляется раньше значения b, если проходить по дереву с приоритетным направлением в глубину.Given two hierarchyid values a and b, a<b means a comes before b in a depth-first traversal of the tree. Индексы для типов данных hierarchyid располагаются в порядке приоритета глубины, а узлы, встречающиеся рядом при проходе по дереву с приоритетным направлением глубины, хранятся рядом друг с другом.Indexes on hierarchyid data types are in depth-first order, and nodes close to each other in a depth-first traversal are stored near each other. Например, потомки некоторой записи хранятся рядом с этой записью.For example, the children of a record are stored adjacent to that record.
-
Поддержка произвольных вставок и удаленийSupport for arbitrary insertions and deletions
С помощью метода GetDescendant можно в любой момент создать одноуровневый элемент, расположенный справа от заданного узла, слева от заданного узла или между любыми двумя другими одноуровневыми элементами.By using the GetDescendant method, it is always possible to generate a sibling to the right of any given node, to the left of any given node, or between any two siblings. Свойство сравнения сохраняется, если произвольное число узлов вставляется в иерархию или удаляется из нее.The comparison property is maintained when an arbitrary number of nodes is inserted or deleted from the hierarchy. Большинство операций вставки и удаления сохраняют свойство компактности.Most insertions and deletions preserve the compactness property. Однако операции вставки между двумя узлами приводят к созданию значений hierarchyid, обладающих менее компактным представлением.However, insertions between two nodes will produce hierarchyid values with a slightly less compact representation.
Операторы поиска данных
Синтаксис:
GET UNIQUE <имя
сегмента> WHERE <список поиска>;
список поиска
состоит из последовательности условий вида:
<имя сегмента>.<имя
поля>ОС <constant или имя другого поля данного сегмента или имя переменной>:
ОС — операция
сравнения;
условия могут
быть соединены логическими операциями И и ИЛИ {& , V}.
Назначение:
Получить
единственное значение.
Пример:
Найти типовую
модель стоимостью не более $600, которая существует не менее чем в 10 экземплярах.
GET UNIQUE ТИПОВЫЕ
МОДЕЛИ
WHERE Типовые
модели.Стоимость <= $600
AND Типовые модели,Количество
на складе >= 10
Данная команда
всегда ищет с начала БД и останавливается, найдя первый экземпляр сегмента,
удовлетворяющий условиям поиска.
Синтаксис:
GET NEXT <имя
сегмента> WHERE <список аргументов поиска>
Назначение:
Получить
следующий экземпляр сегмента для тех же условии.
Пример:
Напечатать
полный список заказов стоимостью не менее $500.
GET UNIQUE ИНДИВИДУАЛЬНЫЕ
МОДЕЛИ
WHERE Индивидуальные
модели.Стоимость >- $500
WHILE NOT EAIL
(пока не конец поиска) DO
PRINT № заказа.
Стоимость, Количество
GET NEXT ИНДИВИДУАЛЬНЫЕ
МОДЕЛИ
END
Синтаксис:
GET NEXT <имя
сегмента> WITHIN PARENT
Назначение:
Получить
следующий для того же исходного.
Пример:
Получить
перечень винчестеров, имеющихся на складе номер 1, в количестве не менее 10
с объемом 10 Гбайт.
GET UNIQUE СКЛАД
WHERE Склад.Номер = 1
GET NEXT ИЗДЕЛИЕ
WITHIN PARENT
WHERE Изделие.Наименование
= «Винчестер»
GET NEXT ХАРАКТЕРИСТИКИ
WITHIN PARENT
WHERE ХАРАКТЕРИСТИКИ.Параметр
= 10 AND
ХАРАКТЕРИСТИКИ.Единицы
Измерения = Гб AND
ХАРАКТЕРИСТИКИ.Величина
> 10
While Not Fail
(пока поиск не завершен) DO
Get Next Within
Parent
end
Основные понятия
К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь.
Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей.
К каждой записи базы данных существует только один (иерархический) путь от корневой записи.
Каждому узлу структуры соответствует один сегмент, представляющий собой поименованный линейный кортеж полей данных. Каждому сегменту (кроме S1-корневого) соответствует один входной и несколько выходных сегментов. Каждый сегмент структуры лежит на единственном иерархическом пути, начинающемся от корневого сегмента.
Следует отметить, что в настоящее время не разрабатываются СУБД, поддерживающие на концептуальном уровне только иерархические модели. Как правило, использующие иерархический подход системы, допускают связывание древовидных структур между собой и/или установление связей внутри них. Это приводит к сетевым даталогическим моделям СУБД.
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.
- Атрибут (элемент данных) — наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем.
- Запись — именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи — конкретная запись с конкретным значением элементов
- Групповое отношение — иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) — подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
Состав частей реляционной модели данных
Наиболее распространенная трактовка реляционной модели данных, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
Структурная часть
Структурная часть (аспект), отвечает за принцип построения структуры реляционной базы данных на нормализированном наборе n-арных отношений, в форме таблиц
Важно что реляционная база данных, структурно может представляться только в виде отношений
Манипуляционная часть
В манипуляционной части модели утверждаются операторы манипулирования отношениями — реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй — на классическом логическом аппарате исчисления предикатов первого порядка. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Целостная часть
В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Как мы видели в предыдущем разделе, это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений.
Второе требование называется требованием целостности по ссылкам и является несколько более сложным. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений.
Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
Главное о базах данных
- Чаще всего базы данных напоминают таблицы: в них одному параметру соответствует один набор данных. Например, один клиент — одно имя, один телефон, один адрес.
- Такие «табличные» базы данных называются реляционными.
- Чтобы строить сложные связи, разные таблицы в реляционных базах можно связывать между собой: ставить ссылки.
- Реляционная база — не единственный способ хранения данных. Есть ситуации, когда нам нужна большая гибкость в хранении.
- Бывают сетевые базы данных: когда нужно хранить много связей между множеством объектов. Например, каталог фильмов: в одном фильме может участвовать много человек, а каждый из них может участвовать во множестве фильмов.
- Бывают иерархические базы, или «деревья». Пример — наша файловая система.
- Какую выбрать базу — зависит от задачи. Одна база не лучше другой, но они могут быть более или менее подходящими для определённых задач.
Текст и иллюстрации:Миша Полянин
Редактор:Максим Ильяхов
Корректор:Ира Михеева
Иллюстратор:Даня Берковский
Вёрстка:Маша Дронова
Доставка:Олег Вешкурцев
Что-то делает руками:Паша Федоров
Во славу:Практикума
Проектирование реляционной базы данных. Преобразование модели в реляционную
Преобразование концептуальной модели данных в реляционную — важная часть проектирования БД. Процесс включает в себя:
— построение набора предварительных таблиц;
— указание РК;
— выполнение нормализации.
Из набора таблиц состоят наши объекты, а из полей таблиц — атрибуты объектов:
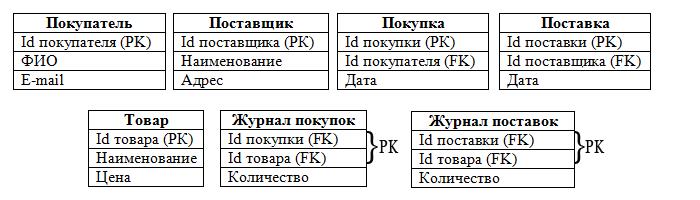
Итак, мы определились с таблицами, полями, РК и FK. Следует отметить, что в таблицах «Журнал покупок» и «Журнал поставок» РК составные, т. к. состоят из 2-х полей.
Что касается нормализации, то под ней понимают обратимый и пошаговый процесс, при котором исходная схема меняется другой схемой, в которой таблицы характеризуются более простой и логичной структурой. Это нужно по следующим причинам:
1. Устранение избыточности данных. Вспомним нашу таблицу:

Очевидно, что в поле «Темы» одни и те же названия встречаются регулярно. Для хранения таких данных нужны дополнительные ресурсы памяти. Кроме того, при дублировании данных можно допустить ошибку во время ввода значений атрибута, вследствие которой БД перейдёт в состояние несогласованности.
2. Устранение различных аномалий, связанных с обновлением, удалением, модификацией и пр. Пример аномалии модификации — чтобы поменять название темы, нам придётся смотреть все строки и менять название в каждой из них.
Нормализация бывает:
— 1-й нормальной формы (1НФ);
— 2НФ;
— 3НФ;
— НФБК (нормальной формы Бойса-Кодда);
— 4НФ;
— 5НФ.
Каждая форма накладывает определённые ограничения на данные разного уровня. В ходе нормализации база данных становится всё строже, подверженность аномалиям снижается.
Если говорить о реляционных базах данных, то минимум — это 1НФ. Однако в процессе проектирования специалисты по СУБД стремятся нормализовать базу хотя бы до уровня 3НФ, исключив тем самым избыточность данных и аномалии
Это важно, если мы стремимся получить качественный результат проектирования. Однако подробное описание нормализации данных выходит за рамки нашей статьи, поэтому давайте просто посмотрим, как будет выглядеть наша база на уровне 3НФ:
Итак, в процессе проектирования мы преобразовали концептуальную модель в реляционную. Следующий этап — реализация её в конкретной СУБД. Для этого потребуется как сама СУБД, так и знание языка SQL. Например, прекрасно подойдёт СУБД MySQL или какая-нибудь другая СУБД.