Матрицы в python и массивы numpy
Содержание:
- Методы списков
- Получение максимального и минимального элемента
- 4. Выражения-генераторы
- Разделение матрицы
- Индексация и срезы многомерных массивов
- Как работает Быстрая сортировка
- 2.4.2. Обход массива¶
- Списочная индексация и многомерные массивы
- Добро пожаловать в NumPy!
- Установка NumPy
- Как импортировать NumPy
- В чем разница между списком Python и массивом NumPy?
- Что такое массив?
- Базовое использование
- Двумерный массив
- Манипуляции с формой
- Методы списков
- Общее представление о массиве
- 8. Использование range()
- 3 Общие методы для части коллекций
- Форма матрицы в Python
- Ввод-вывод двумерного массива
Методы списков
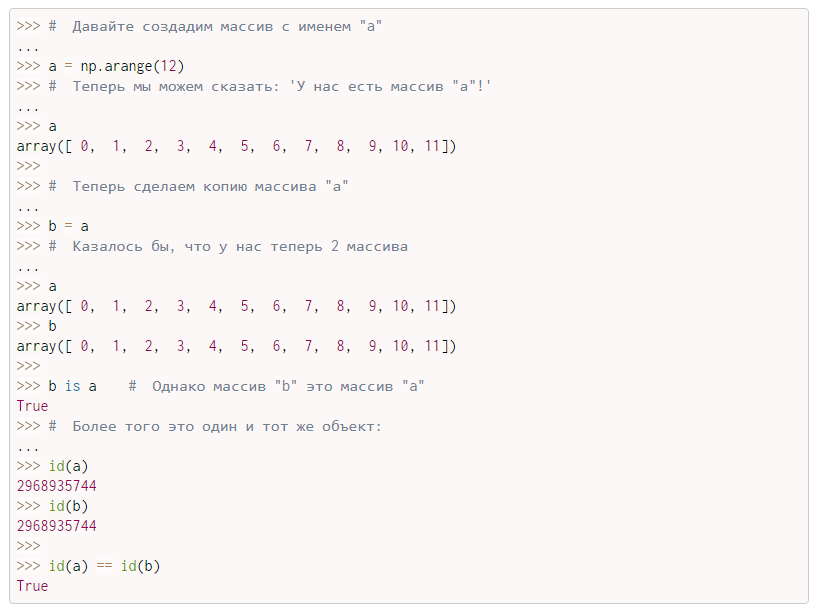
Давайте теперь
предположим, что у нас имеется список из чисел:
a = 1, -54, 3, 23, 43, -45,
и мы хотим в
конец этого списка добавить значение. Это можно сделать с помощью метода:
a.append(100)
И обратите
внимание: метод append ничего не возвращает, то есть, он меняет
сам список благодаря тому, что он относится к изменяемому типу данных. Поэтому
писать здесь конструкцию типа
a = a.append(100)
категорически не
следует, так мы только потеряем весь наш список! И этим методы списков
отличаются от методов строк, когда мы записывали:
string="Hello" string = string.upper()
Здесь метод upper возвращает
измененную строку, поэтому все работает как и ожидается. А метод append ничего не
возвращает, и присваивать значение None переменной a не имеет
смысла, тем более, что все работает и так:
a = 1, -54, 3, 23, 43, -45, a.append(100)
Причем, мы в методе
append можем записать
не только число, но и другой тип данных, например, строку:
a.append("hello")
тогда в конец
списка будет добавлен этот элемент. Или, булевое значение:
a.append(True)
Или еще один
список:
a.append(1,2,3)
И так далее. Главное,
чтобы было указано одно конкретное значение. Вот так работать не будет:
a.append(1,2)
Если нам нужно
вставить элемент в произвольную позицию, то используется метод
a.insert(3, -1000)
Здесь мы
указываем индекс вставляемого элемента и далее значение самого элемента.
Следующий метод remove удаляет элемент
по значению:
a.remove(True)
a.remove('hello')
Он находит
первый подходящий элемент и удаляет его, остальные не трогает. Если же
указывается несуществующий элемент:
a.remove('hello2')
то возникает
ошибка. Еще один метод для удаления
a.pop()
выполняет
удаление последнего элемента и при этом, возвращает его значение. В самом
списке последний элемент пропадает. То есть, с помощью этого метода можно
сохранять удаленный элемент в какой-либо переменной:
end = a.pop()
Также в этом
методе можно указывать индекс удаляемого элемента, например:
a.pop(3)
Если нам нужно
очистить весь список – удалить все элементы, то можно воспользоваться методом:
a.clear()
Получим пустой
список. Следующий метод
a = 1, -54, 3, 23, 43, -45, c = a.copy()
возвращает копию
списка. Это эквивалентно конструкции:
c = list(a)
В этом можно
убедиться так:
c1 = 1
и список c будет отличаться
от списка a.
Следующий метод count позволяет найти
число элементов с указанным значением:
c.count(1) c.count(-45)
Если же нам
нужен индекс определенного значения, то для этого используется метод index:
c.index(-45) c.index(1)
возвратит 0,
т.к. берется индекс только первого найденного элемента. Но, мы здесь можем
указать стартовое значение для поиска:
c.index(1, 1)
Здесь поиск
будет начинаться с индекса 1, то есть, со второго элемента. Или, так:
c.index(23, 1, 5)
Ищем число 23 с
1-го индекса и по 5-й не включая его. Если элемент не находится
c.index(23, 1, 3)
то метод
приводит к ошибке. Чтобы этого избежать в своих программах, можно вначале
проверить: существует ли такой элемент в нашем срезе:
23 in c1:3
и при значении True далее уже
определять индекс этого элемента.
Следующий метод
c.reverse()
меняет порядок
следования элементов на обратный.
Последний метод,
который мы рассмотрим, это
c.sort()
выполняет
сортировку элементов списка по возрастанию. Для сортировки по убыванию, следует
этот метод записать так:
c.sort(reverse=True)
Причем, этот
метод работает и со строками:
lst = "Москва", "Санкт-Петербург", "Тверь", "Казань" lst.sort()
Здесь
используется лексикографическое сравнение, о котором мы говорили, когда
рассматривали строки.
Это все основные
методы списков и чтобы вам было проще ориентироваться, приведу следующую
таблицу:
|
Метод |
Описание |
|
append() |
Добавляет |
|
insert() |
Вставляет |
|
remove() |
Удаляет |
|
pop() |
Удаляет |
|
clear() |
Очищает |
|
copy() |
Возвращает |
|
count() |
Возвращает |
|
index() |
Возвращает |
|
reverse() |
Меняет |
|
sort() |
Сортирует |
Получение максимального и минимального элемента
Чтобы получить максимальный или минимальный элемент, можно пройтись по всем элементам матрицы с помощью двух циклов . Это стандартный алгоритм перебора, который известен почти каждому программисту:
arr = np.array(,])
min = arr
for i in range(arr.shape):
for j in range(arr.shape):
if min > arr:
min = arr
print("Минимальный элемент:", min) # Выведет "Минимальный элемент: 2"
NumPy позволяет найти максимальный и минимальный элемент с помощью функций amax() и amin(). В качестве аргумента в функции нужно передать саму матрицу. Пример:
arr1 = np.array(,])
min = np.amin(arr1)
max = np.amax(arr1)
print("Минимальный элемент:", min) # Выведет "Минимальный элемент: 2"
print("Максимальный элемент:", max) # Выведет "Максимальный элемент: 5"
Как видим, результаты реализации на чистом Python и реализации с использованием библиотеки NumPy совпадают.
4. Выражения-генераторы
выдают элемент по-одному, не загружая в память сразу всю коллекцию расход памяти «упадет» с MemoryError
Особенности выражений-генераторов
Генаратор нельзя писать без скобок — это синтаксическая ошибка.
При передаче в функцию дополнительные скобки необязательны
Нельзя получить длину функцией len()
Нельзя распечатать элементы функцией print()
Обратите внимание, что после прохождения по выражению-генератору оно остается пустым!
Выражение-генератор может быть бесконечным.Будьте осторожны в работе с такими генераторами, так как при не правильном использовании «эффект» будет как от бесконечного цикла.
К выражению-генератору не применимы срезы!
Из генератора легко получать нужную коллекцию. Это подробно рассматривается в следующей главе.
Разделение матрицы
Разделение одномерного массива NumPy аналогично разделению списка. Рассмотрим пример:
import numpy as np letters = np.array() # с 3-го по 5-ый элементы print(letters) # Вывод: # с 1-го по 4-ый элементы print(letters) # Вывод: # с 6-го до последнего элемента print(letters) # Вывод: # с 1-го до последнего элемента print(letters) # Вывод: # список в обратном порядке print(letters) # Вывод:
Теперь посмотрим, как разделить матрицу.
import numpy as np
A = np.array(,
,
])
print(A) # две строки, четыре столбца
''' Вывод:
]
'''
print(A) # первая строка, все столбцы
''' Вывод:
` 1 4 5 12 14`
'''
print(A) # все строки, второй столбец
''' Вывод:
'''
print(A) # все строки, с третьего по пятый столбец
''' Вывод:
]
'''
Использование NumPy вместо вложенных списков значительно упрощает работу с матрицами. Мы рекомендуем детально изучить пакет NumPy, если вы планируете использовать Python для анализа данных.
Данная публикация является переводом статьи «Python Matrices and NumPy Arrays» , подготовленная редакцией проекта.
Индексация и срезы многомерных массивов
В базовом
варианте индексация и срезы многомерных массивов работают также как и в
одномерных, только индексы указываются для каждой оси. Например, объявим
двумерный массив:
x = np.array((1, 2, 3), (10, 20, 30), (100, 200, 300))
Для обращения к
центральному значению 20 нужно выбрать вторую строку и второй столбец, имеем:
x1, 1 # значение 20
Чтобы взять
последнюю строку и последний столбец, можно использовать отрицательные индексы:
x-1, -1 # значение 300
Если же указать
только один индекс, то получим строку:
x # array()
Эта запись
эквивалентна следующей:
x, : # array()
То есть, не
указывая какие-либо индексы, NumPy автоматически подставляет вместо них
полные срезы.
Для извлечения
столбцов мы уже должны явно указать полный срез в качестве первого индекса:
x:,1 # array()
Итерирование
двумерных массивов можно выполнять с помощью вложенных циклов, например:
for row in x: for val in row: print(val, end=' ') print()
Если же
необходимо просто перебрать все элементы многомерного массива, то можно
использовать свойство flat:
for val in x.flat: print(val, end=' ')
У массивов более
высокой размерности картина индексации, в целом выглядит похожим образом.
Например, создадим четырехмерный массив:
a = np.arange(1, 82).reshape(3, 3, 3, 3)
Тогда для
обращения к конкретному элементу следует указывать четыре индекса:
a1, 2, , 1 # число 47
Для выделения
многомерного среза, можно использовать такую запись:
a:, 1, :, : # матрица 3x3x3
или, так:
a, # двумерная матрица 3x3
Это эквивалентно
записи:
a, , :, :
Если же нужно
задать два последних индекса, то полные срезы у первых двух осей указывать
обязательно:
a:, :, 1, 1 # матрица 3x3 a:2, :2, 1, 1 # матрица 2x2
Пакет NumPy позволяет
множество полных подряд идущих срезов заменять троеточиями. Например, вместо a
можно использовать запись:
a..., 1, 1 # эквивалент a
Это бывает
удобно, когда у массива много размерностей и нам нужны последние индексы.
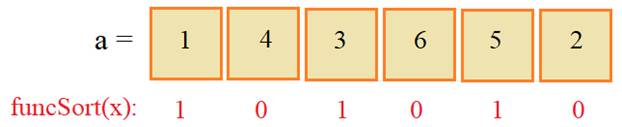
Как работает Быстрая сортировка
Быстрая сортировка чаще всего не сможет разделить массив на равные части. Это потому, что весь процесс зависит от того, как мы выбираем опорный элемент. Нам нужно выбрать опору так, чтобы она была примерно больше половины элементов и, следовательно, примерно меньше, чем другая половина элементов. Каким бы интуитивным ни казался этот процесс, это очень сложно сделать.
Подумайте об этом на мгновение — как бы вы выбрали адекватную опору для вашего массива? В истории быстрой сортировки было представлено много идей о том, как выбрать центральную точку — случайный выбор элемента, который не работает из-за того, что «дорогой» выбор случайного элемента не гарантирует хорошего выбора центральной точки; выбор элемента из середины; выбор медианы первого, среднего и последнего элемента; и еще более сложные рекурсивные формулы.
Самый простой подход — просто выбрать первый (или последний) элемент. По иронии судьбы, это приводит к быстрой сортировке на уже отсортированных (или почти отсортированных) массивах.
Именно так большинство людей выбирают реализацию быстрой сортировки, и, так как это просто и этот способ выбора опоры является очень эффективной операцией, и это именно то, что мы будем делать.
Теперь, когда мы выбрали опорный элемент — что нам с ним делать? Опять же, есть несколько способов сделать само разбиение. У нас будет «указатель» на нашу опору, указатель на «меньшие» элементы и указатель на «более крупные» элементы.
Цель состоит в том, чтобы переместить элементы так, чтобы все элементы, меньшие, чем опора, находились слева от него, а все более крупные элементы были справа от него. Меньшие и большие элементы не обязательно будут отсортированы, мы просто хотим, чтобы они находились на правильной стороне оси. Затем мы рекурсивно проходим левую и правую сторону оси.
Рассмотрим пошагово то, что мы планируем сделать, это поможет проиллюстрировать весь процесс. Пусть у нас будет следующий список.
29 | 99 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,21,44 (high)
Выберем первый элемент как опору 29), а указатель на меньшие элементы (называемый «low») будет следующим элементом, указатель на более крупные элементы (называемый «high») станем последний элемент в списке.
29 | 99 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,21 (high),44
Мы двигаемся в сторону high то есть влево, пока не найдем значение, которое ниже нашего опорного элемента.
29 | 99 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,21 (high),44
- Теперь, когда наш элемент high указывает на элемент 21, то есть на значение меньше чем опорное значение, мы хотим найти значение в начале массива, с которым мы можем поменять его местами. Нет смысла менять местами значение, которое меньше, чем опорное значение, поэтому, если low указывает на меньший элемент, мы пытаемся найти тот, который будет больше.
- Мы перемещаем переменную low вправо, пока не найдем элемент больше, чем опорное значение. К счастью, low уже имеет значение 89.
- Мы меняем местами low и high:
29 | 21 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,99 (high),44
- Сразу после этого мы перемещает high влево и low вправо (поскольку 21 и 89 теперь на своих местах)
- Опять же, мы двигаемся high влево, пока не достигнем значения, меньшего, чем опорное значение, и мы сразу находим — 12
- Теперь мы ищем значение больше, чем опорное значение, двигая low вправо, и находим такое значение 41
Этот процесс продолжается до тех пор, пока указатели low и high наконец не встретятся в одном элементе:
29 | 21,27,12,19,28 (low/high),44,78,87,66,31,76,58,88,83,97,41,99,44
Мы больше не используем это опорное значение, поэтому остается только поменять опорную точку и high, и мы закончили с этим рекурсивным шагом:
28,21,27,12,19,29,44,78,87,66,31,76,58,88,83,97,41,99,44
Как видите, мы достигли того, что все значения, меньшие 29, теперь слева от 29, а все значения больше 29 справа.
Затем алгоритм делает то же самое для коллекции 28,21,27,12,19 (левая сторона) и 44,78,87,66,31,76,58,88,83,97,41,99,44 (правая сторона). И так далее.
2.4.2. Обход массива¶
Но обычно вам надо работать сразу со всеми элементами массива. Точнее,
сразу со всеми как правило не надо, надо по очереди с каждым (говорят:
«пробежаться по массиву»). Для этого вам очень полезная вещь — это цикл
. Если вы знаете, что в массиве элементов (т.е. если у вас
есть переменная и в ней хранится число элементов в массиве), то
это делается так:
for i in range(n):
... что-то сделать с элементом a
например, вывести все элементы массива на экран:
for i in range(n):
print(ai])
или увеличить все элементы массива на единицу:
for i in range(n):
ai += 1
и т.п. Конечно, в цикле можно и несколько действий делать, если надо.
Осознайте, что это не магия, а просто полностью соответствует тому, что
вы знаете про работу цикла .
Если же у вас нет переменной , то вы всегда можете воспользоваться
специальной функцией , которая возвращает количество элементов в
массиве:
for i in range(len(a)):
...
Списочная индексация и многомерные массивы
Фактически,
массив индексов определяет значения и форму создаваемого массива. Например,
если взять тот же одномерный массив:
a = np.arange(1, 9)
но набор
индексов определить как двумерный массив:
i = np.array(, 1, 2, 3)
то на выходе
будет формироваться уже двумерный массив:
ai # array(, ])
Только в этом
случае индексы i должны определяться именно массивом NumPy, а не списком Python.
Так можно
создавать массивы любых размерностей. Давайте теперь посмотрим, как будет себя вести
списочное индексирование с многомерными массивами. Возьмем двумерный массив:
a = np.arange(1, 13).reshape(3, 4)
и одномерный
список индексов:
indx = 2, 1, aindx
На выходе
получим массив:
array(,
,
])
Смотрите, здесь
индексы обозначают номера строк двумерного массива. В результате, строки нового
массива идут в обратном порядке. Далее, пропишем индексы в виде двумерного
массива:
indx = np.array(1, , 2, 1) aindx
Результатом будет
трехмерный массив:
array(,
],
,
]])
Что здесь
произошло? В действительности, каждый индекс двумерного массива соответствует
определенной строке этого массива. А двумерная форма индексов лишь указывает
как упаковать строки в новом массиве. То есть, вместо каждого индекса
подставляется своя строка и получается трехмерный массив.
Если же мы хотим
выбирать из двумерного массива не строки, а отдельные элементы и на их основе
формировать новые массивы, то следует использовать два списка. Первый список по
прежнему будет указывать строки массива, а второй – индексы столбцов у каждой
строки. Например, так:
i0 = , 1 i1 = 1, 2 ai0, i1 # array()
Работу такого списочного
индексирования можно представить в виде:
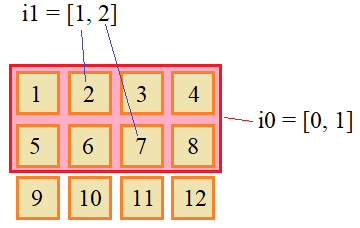
При
множественной списочной индексации допускается указывать конкретные индексы и
срезы. Например:
a:, i1
В этом случае
получим уже матрицу 3×2, то есть, второй список i1 здесь
используется для выделения столбцов целиком, а не одного только элемента. Соответственно,
строчка:
ai0, 1 # array()
выделим массив
из двух значений 2 и 6.
Добро пожаловать в NumPy!
NumPy (NumericalPython) — это библиотека Python с открытым исходным кодом, которая используется практически во всех областях науки и техники. Это универсальный стандарт для работы с числовыми данными в Python, и он лежит в основе научных экосистем Python и PyData. В число пользователей NumPy входят все — от начинающих программистов до опытных исследователей, занимающихся самыми современными научными и промышленными исследованиями и разработками. API-интерфейс NumPy широко используется в пакетах Pandas, SciPy, Matplotlib, scikit-learn, scikit-image и в большинстве других научных и научных пакетов Python.
Библиотека NumPy содержит многомерный массив и матричные структуры данных (дополнительную информацию об этом вы найдете в следующих разделах). Он предоставляет ndarray, однородный объект n-мерного массива, с методами для эффективной работы с ним. NumPy может использоваться для выполнения самых разнообразных математических операций над массивами. Он добавляет мощные структуры данных в Python, которые гарантируют эффективные вычисления с массивами и матрицами, и предоставляет огромную библиотеку математических функций высокого уровня, которые работают с этими массивами и матрицами.
Узнайте больше о NumPy здесь!
GIF черезgiphy
Установка NumPy
Чтобы установить NumPy, я настоятельно рекомендую использовать научный дистрибутив Python. Если вам нужны полные инструкции по установке NumPy в вашей операционной системе, вы можетенайти все детали здесь,
Если у вас уже есть Python, вы можете установить NumPy с помощью
conda install numpy
или
pip install numpy
Если у вас еще нет Python, вы можете рассмотреть возможность использованияанаконда, Это самый простой способ начать. Преимущество этого дистрибутива в том, что вам не нужно слишком беспокоиться об отдельной установке NumPy или каких-либо основных пакетов, которые вы будете использовать для анализа данных, таких как pandas, Scikit-Learn и т. Д.
Если вам нужна более подробная информация об установке, вы можете найти всю информацию об установке наscipy.org,
фотоАдриеннотPexels
Если у вас возникли проблемы с установкой Anaconda, вы можете ознакомиться с этой статьей:
Как импортировать NumPy
Каждый раз, когда вы хотите использовать пакет или библиотеку в своем коде, вам сначала нужно сделать его доступным.
Чтобы начать использовать NumPy и все функции, доступные в NumPy, вам необходимо импортировать его. Это можно легко сделать с помощью этого оператора импорта:
import numpy as np
(Мы сокращаем «numpy» до «np», чтобы сэкономить время и сохранить стандартизированный код, чтобы любой, кто работает с вашим кодом, мог легко его понять и запустить.)
В чем разница между списком Python и массивом NumPy?
NumPy предоставляет вам огромный выбор быстрых и эффективных числовых опций. Хотя список Python может содержать разные типы данных в одном списке, все элементы в массиве NumPy должны быть однородными. Математические операции, которые должны выполняться над массивами, были бы невозможны, если бы они не были однородными.
Зачем использовать NumPy?
фотоPixabayотPexels
Массивы NumPy быстрее и компактнее, чем списки Python. Массив потребляет меньше памяти и намного удобнее в использовании. NumPy использует гораздо меньше памяти для хранения данных и предоставляет механизм задания типов данных, который позволяет оптимизировать код еще дальше.
Что такое массив?
Массив является центральной структурой данных библиотеки NumPy. Это таблица значений, которая содержит информацию о необработанных данных, о том, как найти элемент и как интерпретировать элемент. Он имеет сетку элементов, которые можно проиндексировать в Все элементы имеют одинаковый тип, называемыймассив dtype(тип данных).
Массив может быть проиндексирован набором неотрицательных целых чисел, логическими значениями, другим массивом или целыми числами.рангмассива это количество измерений.формамассива — это кортеж целых чисел, дающий размер массива по каждому измерению.
Одним из способов инициализации массивов NumPy является использование вложенных списков Python.
a = np.array(, , ])
Мы можем получить доступ к элементам в массиве, используя квадратные скобки. Когда вы получаете доступ к элементам, помните, чтоиндексирование в NumPy начинается с 0, Это означает, что если вы хотите получить доступ к первому элементу в вашем массиве, вы получите доступ к элементу «0».
print(a)
Выход:
Базовое использование
Как создать список
Пустой список создается при помощи пары квадратных скобок:
empty_list = [] print(type(empty_list)) # <class 'list'> print(len(empty_list)) # 0
Можно создать список, сразу содержащий
какие-то элементы. В этом случае они
перечисляются через запятую и помещаются
в квадратные скобки. Элементы в списках
могут быть гетерогенными (т. е., разных
типов), хотя обычно бывают гомогенными
(одного типа):
homogeneous_list = print(homogeneous_list) # print(len(homogeneous_list)) # 6 heterogeneous_list = print(heterogeneous_list) # print(len(heterogeneous_list)) # 2
Для создания списков также может
использоваться конструктор list:
empty_list = list() # Создаем пустой список
print(empty_list) # []
new_list = list("Hello, Pythonist!") # Новый список создается путем перебора заданного итерируемого объекта.
print(new_list) #
Также при создании списков используется List Comprehension, к которому мы еще вернемся.
Обращение к элементам списка
Вывод всего списка:
my_list = print(my_list) #
Вывести отдельные элементы списка можно, обратившись к ним по индексу (не забываем, что отсчет начинается с нуля).
print(my_list) # 1 print(my_list) # 2 print(my_list) # 9
В Python для обращения к элементам можно
использовать и отрицательные индексы.
При этом последний элемент в списке
будет иметь индекс -1, предпоследний —
-2 и так далее.
print(my_list) # 25 print(my_list) # 16 print(my_list) # 9
Распаковка списков (для python-3). Если
поставить перед именем списка звездочку,
все элементы этого списка будут переданы
функции в качестве отдельных аргументов.
my_list = print(my_list) # print(*my_list) # 1 2 9 16 25 words = print(words) # print(*words) # I love Python I love
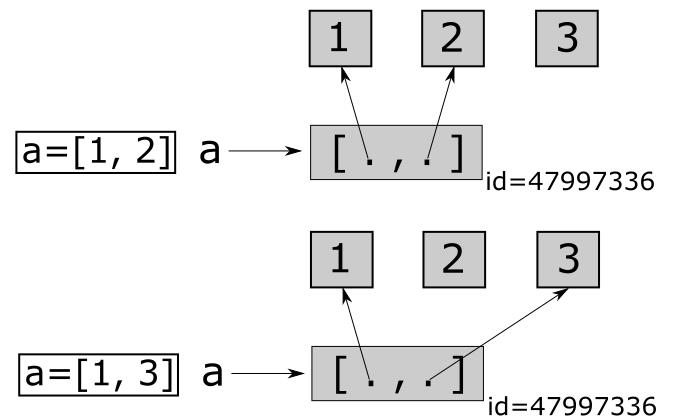
Списки мутабельны
Списки — это изменяемые контейнеры.
То есть, вы можете изменять содержимое
списка, добавляя и удаляя элементы.
Элементы списка можно перегруппировать,
используя для индексирования другой
список.
Создадим новый список из элементов списка , а индексы нужных элементов возьмем из списка :
my_list = my_index = my_new_list = for i in my_index] print(my_new_list) #
Двумерный массив
В некоторых случаях для правильного представления определенного набора информации обычного одномерного массива оказывается недостаточно. В языке программирования Python 3 двумерных и многомерных массивов не существует, однако базовые возможности этой платформы легко позволяют построить двумерный список. Элементы подобной конструкции располагаются в столбцах и строках, заполняемых как это показано на следующем примере.
d1 = []
for j in range(5):
d2 = []
for i in range(5):
d2.append(0)
d1.append(d2)
Здесь можно увидеть, что основная идея реализации двумерного набора данных заключается в создании нескольких списков d2 внутри одного большого списка d1. При помощи двух циклов for происходит автоматическое заполнение нулями матрицы с размерностью 5×5. С этой задачей помогают справляться методы append и range, первый из которых добавляет новый элемент в список (0), а второй позволяет устанавливать его величину (5). Нельзя не отметить, что для каждого нового цикла for используется собственная временная переменная, выполняющая представление текущего элемента внешнего (j) или внутренних (i) списков. Обратиться к нужной ячейке многомерного списка можно при помощи указания ее координат в квадратных скобках, ориентируясь на строки и столбцы: d1.
Манипуляции с формой
Как уже говорилось, у массива есть форма (shape), определяемая числом элементов вдоль каждой оси:
>>> a
array(,
],
,
]])
>>> a.shape
(2, 2, 3)
Форма массива может быть изменена с помощью различных команд:
>>> a.ravel() # Делает массив плоским
array()
>>> a.shape = (6, 2) # Изменение формы
>>> a
array(,
,
,
,
,
])
>>> a.transpose() # Транспонирование
array(,
])
>>> a.reshape((3, 4)) # Изменение формы
array(,
,
])
Порядок элементов в массиве в результате функции ravel() соответствует обычному «C-стилю», то есть, чем правее индекс, тем он «быстрее изменяется»: за элементом a следует a. Если одна форма массива была изменена на другую, массив переформировывается также в «C-стиле». Функции ravel() и reshape() также могут работать (при использовании дополнительного аргумента) в FORTRAN-стиле, в котором быстрее изменяется более левый индекс.
>>> a
array(,
,
,
,
,
])
>>> a.reshape((3, 4), order='F')
array(,
,
])
Метод reshape() возвращает ее аргумент с измененной формой, в то время как метод resize() изменяет сам массив:
>>> a.resize((2, 6))
>>> a
array(,
])
Если при операции такой перестройки один из аргументов задается как -1, то он автоматически рассчитывается в соответствии с остальными заданными:
Методы списков
len()
Метод возвращает длину объекта (списка, строки, кортежа или словаря).
принимает один аргумент, который может быть или последовательностью (например, строка, байты, кортеж, список, диапазон), или коллекцией (например, словарь, множество, frozenset).
list1 = # список
print(len(list1)) # в списке 3 элемента, в выводе команды будет "3"
str1 = 'basketball' # строка
print(len(str1)) # в строке 9 букв, в выводе команды будет "9"
tuple1 = (2, 3, 4, 5) # кортеж
print(len(tuple1)) # в кортеже 4 элемента, в выводе команды будет "4"
dict1 = {'name': 'John', 'age': 4, 'score': 45} # словарь
print(len(dict1)) # в словаре 3 пары ключ-значение, в выводе команды будет "3"
index()
возвращает индекс элемента. Сам элемент передается методу в качестве аргумента. Возвращается индекс первого вхождения этого элемента (т. е., если в списке два одинаковых элемента, вернется индекс первого).
numbers =
words =
print(numbers.index(9)) # 4
print(numbers.index(2)) # 1
print(words.index("I")) # 0
print(words.index("JavaScript")) # возвращает ValueError, поскольку 'JavaScript' в списке 'words' нет
Первый результат очевиден. Второй и
третий output демонстрируют возврат индекса
именно первого вхождения.
Цифра «2» встречается в списке дважды,
первое ее вхождение имеет индекс 1,
второе — 2. Метод index() возвращает индекс
1.
Аналогично возвращается индекс 0 для элемента «I».
Если элемент, переданный в качестве аргумента, вообще не встречается в списке, вернется ValueError. Так получилось с попыткой выяснить индекс «JavaScript» в списке .
Опциональные аргументы
Чтобы ограничить поиск элемента
конкретной подпоследовательностью,
можно использовать опциональные
аргументы.
words =
print(words.index("am", 2, 5)) # 4
Метод index() будет искать элемент «am» в диапазоне от элемента с индексом 2 (включительно) до элемента с индексом 5 (этот последний элемент не входит в диапазон).
При этом возвращаемый индекс — индекс
элемента в целом списке, а не в указанном
диапазоне.
pop()
Метод удаляет и возвращает последний элемент списка.
Этому методу можно передавать в качестве параметра индекс элемента, который вы хотите удалить (это опционально). Если конкретный индекс не указан, метод удаляет и возвращает последний элемент списка.
Если в списке нет указанного вами индекса, метод выбросит exception .
cities = print "City popped is: ", cities.pop() # City popped is: San Francisco print "City at index 2 is : ", cities.pop(2) # City at index 2 is: San Antonio
Базовый функционал стека
Для реализации базового функционала
стека в программах на Python часто
используется связка метода pop() и метода
append():
stack = []
for i in range(5):
stack.append(i)
while len(stack):
print(stack.pop())
Общее представление о массиве
Массив (в питоне еще принято название «список», это то же самое) — это переменная, в которой хранится много значений. Массив можно представлять себе в виде такой последовательности ячеек, в каждой из которых записано какое-то число:
Значения, хранящиеся в массиве (говорят: элементы массива) нумеруются последовательно, начиная с нуля. На картинке выше числа внутри квадратиков — это значения, хранящиеся в массиве, а числа под квадратиками — номера этих элементов (еще говорят «индексы» элементов)
Обратите внимание, что в массиве 6 элементов, но последний имеет номер 5, т.к. нумерация начинается с нуля
Это важно!
Соответственно, переменная теперь может хранить целиком такой массив. Создается такой массив, например, путем перечисления значений в квадратных скобках:
Теперь переменная a хранит этот массив. К элементам массива можно обращаться тоже через квадратные скобки: — это элемент номер 2, т.е. в нашем случае это . Аналогично, — это 0. В квадратных скобках можно использовать любые арифметические выражения и даже другие переменные: — это 12, обозначает «возьми элемент с номером, равным значению переменной «, аналогично обозначает «возьми элемент с номером, равным 2*i+1», или даже обозначает «возьми элемент с номером, равным четвертому элементу нашего массива» (в нашем примере — это , поэтому — это , т.е. ).
Если указанный номер слишком большой (больше длины массива), то питон выдаст ошибку (т.е. в примере выше будет ошибкой, да и даже тоже). Если указан отрицательный номер, то тут действует хитрое правило. Отрицательные номера обозначают нумерацию массива с конца: — это всегда последний элемент, — предпоследний и т.д. В нашем примере равно 7. Слишком большой отрицательный номер тоже дает ошибку (в нашем примере уже ошибка).
С элементами массива можно работать как с привычными вам переменными. Можно им присваивать значения: , считывать с клавиатуры: , выводить на экран: , использовать в выражениях: (здесь — какая-то еще целочисленная переменная для примера), использовать в if’ах: , или и т.д. Везде, где вы раньше использовали переменные, можно теперь использовать элемент массива.
8. Использование range()
Особенности функции range():
- Наиболее часто функция range() применяется для запуска цикла for нужное количество раз. Например, смотрите генерацию матрицы в примерах выше.
- В Python 3 range() возвращает генератор, который при каждом к нему обращении выдает очередной элемент.
- Исполльзуемые параметры аналогичны таковым в срезах (кроме первого примера с одним параметром):
- range(stop) — в данном случае с 0 до stop-1;
- range(start, stop) — Аналогично примеру выше, но можно задать начало отличное от нуля, можно и отрицательное;
- range(start, stop, step) — Добавляем параметр шага, который может быть отрицательным, тогда перебор в обратном порядке.
- В Python 2 были 2 функции:
- range(…) которая аналогична выражению list(range(…)) в Python 3 — то есть она выдавала не итератор, а сразу готовый список. То есть все проблемы возможной нехватки памяти, описанные в разделе 4 актуальны, и использовать ее в Python 2 надо очень аккуратно!
- xrange(…) — которая работала аналогично range(…) в Python 3 и из 3 версии была исключена.
3 Общие методы для части коллекций
Объяснение работы методов и примеры:
- .count() — метод подсчета определенных элементов для неуникальных коллекций (строка, список, кортеж), возвращает сколько раз элемент встречается в коллекции.
- .index() — возвращает минимальный индекс переданного элемента для индексированных коллекций (строка, список, кортеж)
- .copy() — метод возвращает неглубокую (не рекурсивную) копию коллекции (список, словарь, оба типа множества).
- .clear() — метод изменяемых коллекций (список, словарь, множество), удаляющий из коллекции все элементы и превращающий её в пустую коллекцию.
Особые методы сравнения множеств (set, frozenset)
- set_a.isdisjoint(set_b) — истина, если set_a и set_b не имеют общих элементов.
- set_b.issubset(set_a) — если все элементы множества set_b принадлежат множеству set_a, то множество set_b целиком входит в множество set_a и является его подмножеством (set_b — подмножество)
- set_a.issuperset(set_b) — соответственно, если условие выше справедливо, то set_a — надмножество
Форма матрицы в Python
Lenght matrix (длина матрицы) в Python определяет форму. Длину матрицы проверяют методом shape().
Массив с 2-мя либо 3-мя элементами будет иметь форму (2, 2, 3). И это состояние изменится, когда в shape() будут указаны аргументы: первый — число подмассивов, второй — размерность каждого подмассива.
Те же задачи и ту же операцию выполнит reshape(). Здесь lenght и другие параметры matrix определяются числом столбцов и строк.
Есть методы и для манипуляции формой. Допустим, при манипуляциях с двумерными или многомерными массивами можно сделать одномерный путём выстраивания внутренних значений последовательно по возрастанию. А чтобы поменять в матрице строки и столбцы местами, применяют transpose().
Ввод-вывод двумерного массива
Обычно двумерный массив вам задается как строк по чисел в каждой, причем числа и вам задаются заранее. Такой двумерный массив вводится эдакой комбинацией двух способов ввода одномерного массива, про которые я писал выше:
n, m = map(int, input().split()) # считали n и m из одной строки
# m дальше не будет нужно
a = []
for i in range(n):
a.append(list(map(int, input().split())))
Мы считываем очередную строку и получаем очередной «внутренний» массив: , и приписываем его () ко внешнему массиву.
Обратите внимание, что здесь мы уже четко решили, что первый индекс нашего массива соответствует строкам входного файла, а второй индекс — столбцам, т.е. фактически мы уже выбрали левую из двух картинок выше
Но это связано не с тем, как питон работает с двумерными массивами, а с тем, как заданы входные данные во входном файле.
Вывод двумерного массива, если вам его надо вывести такой же табличкой, тоже делается комбинацией способов вывода одномерного массива, например, так:
for i in range(len(a)):
print(*a)
или так:
for i in range(len(a)):
for j in range(len(a)):
print(a, end=" ")
print() # сделать перевод строки