Как использовать инструмент «детальный анализ запроса» для поисковых фраз и seo?
Содержание:
- Описание
- Основные возможности Яндекс Вордстат
- Парсеры Вордстата
- World Population Milestones
- Society & Media
- Environment
- Как работать с сервисом?
- Why Worldometer clocks are the most accurate
- Другие особенности работы операторов
- Кейс №2
- Отчет «Поисковые запросы»
- World Population clock: sources and methodology
- Yandex Wordstat Assistant
- Что такое Яндекс Wordstat
- Проверка частотности: 80 lvl
- Особенности использования Яндекс.Wordstat
- Яндекс Вордстат — ключевые моменты
Описание
Wordstat Yandex или Подбор слов — это бесплатный сервис Яндекса, предназначенный для оценки пользовательского интереса к различным тематикам и подбора ключевых слов для SEO-оптимизации и контекстной рекламы. Кроме того, с помощью Яндекс Вордстат можно оценить сезонность и географическую зависимость поисковых запросов.
Особенности работы сервиса
- Wordstat не работает без регистрации. Ранее такая возможность была, однако с недавних пор инструмент запускается только после авторизации в Яндекс. Почте.
- Вордстат фильтрует пользователей. Под фильтры системы можно попасть из-за нарушения лицензии на использование Яндекса, а также из-за DDOS-атак на сервис с вашего компьютера в результате деятельности вируса. Стоит отметить, что в качестве атаки на сервер может быть воспринята работа специальных парсеров – программ, собирающих ключевые словосочетания в автоматическом режиме (например, Key Collector).
- Периодически при работе может выскакивать Captcha, приостанавливающая работу с Вордстатом. Возникает это из-за некорректного IP-адреса (для пользователей из не постсоветских стран), закрытых файлов cookie или отсутствии поддержки JS-скриптов на компьютере.
В Яндекс Wordstat доступны срезы по типам устройств пользователей:
- Срез «Десктопы» для запросов, введенных с компьютеров и ноутбуков,
- Срез «Мобильные» для запросов, введенных с планшетов и смартфонов,
- Срез «Только телефоны» – запросы исключительно со смартфонов,
- Срез «Только планшеты» – запросы, введенные только с планшетов.
Операторы Вордстат
- Оператор «-» (минус-слово). Позволяет исключить слово из статистики запросов. Применяется отдельно для каждого слова. Чтобы исключить словосочетание, необходимо добавлять оператор минус перед каждым словом в поисковой строке сервиса.
- Оператор «+» (учет стоп-слов). Позволяет учитывать в статистике союзы и предлоги во всех словоформах, которые игнорируются поисковой системой. При детализации запроса (левая колонка) оператор «+» по умолчанию используется во всех фразах, содержащих стоп-слова.
- Оператор «|» (логическое «или»). Позволяет получить статистику одновременно по нескольким условиям. Работает по правилу логического «или».
- Оператор «()» (логическое «и»). Необходим для группировки запросов, а в паре с оператором «|» позволяет создать регулярное выражение и получить список поисковых фраз по комбинации условий.
- Оператор «» (словоформа). В данном случае фиксируется запрос, поэтому из статистики удаляются дополнительные слова. Учитываются различные окончания, стоп-слова, но не учитывается порядок слов.
- Оператор «!» (точное вхождение). Его использование запускает фиксацию словоформы, т.е. будет учтена фраза только с текущим окончанием слов, но не учитывается порядок слов в запросе.
- Оператор «[]» (учет порядка слов). Необходим чтобы зафиксировать порядок слов в запросе. При этом будут учитываться словоформы и стоп-слова.
Основные возможности Яндекс Вордстат
Для начала давайте познакомимся с общими возможностями сервиса. Он имеет поле ввода (похожее на поисковое) и несколько чекбоксов, переключение которых показывает:
- Общее количество запросов с возможностью раскладки на десктопные (стационарные компьютеры), мобильные и планшетные ПК.
- Распределение запросов по регионам – что полезно для региональных сайтов.
- Историю запросов – показывает изменение спроса со временем, что позволяет выявить тенденции и цикличность спроса. Весьма полезная опция для сайтов сезонной тематики.
Главное окно выглядит вот так:
Здесь мы видим число фраз, содержащих данный запрос. Ниже в таблице приведены цифры по разным фразам с указанным ключом, а справа запросы, которые близки по смыслу к указанному (хорошая подсказка для расширения семантического ядра сайта).
Общие цифры это хорошо, но, если у вас, к примеру, магазин, работающий только в Питере, то итоговые данные поисковика несут мало пользы – надо знать спрос в северной столице. Для этого ставится точка «По регионам»:
Теперь мы видим, что потенциал Санкт-Петербурга 6 тысяч запросов из общих 80-и.
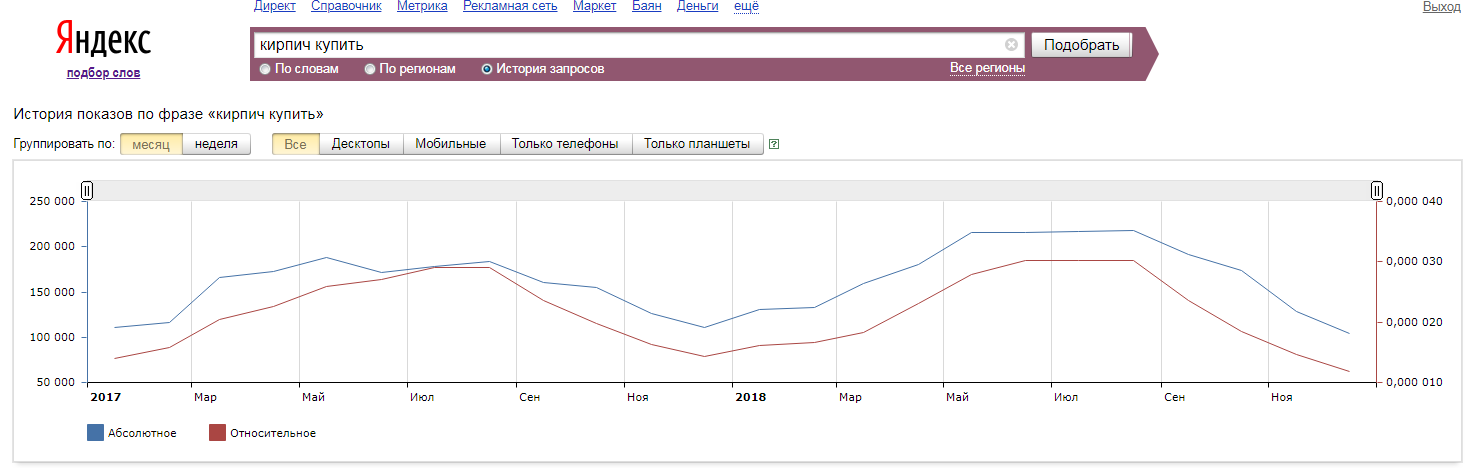
Спрос на многие тематики не постоянен. Даже такой запрос, как «ключевое слово» имеет колебания популярности в 2 раза в разные периоды (график ниже). Попробуйте посмотреть исторический график по запросам «купить зимние шины» или «доставка цветов». Чтобы взглянуть на график из прошлого ставим точку на “История запросов”:
С первого взгляда все кажется простым и понятным, но если вы будете пользоваться wordstat.yandex.ru вот так в лоб, то вы получите существенно завышенные цифры, так как в примерах выше, показаны данные не по точным запросам, а по всем фразам, в которые они входят.
Парсеры Вордстата
Для экономии времени при подборе ключевых слов часто пользуются специально предназначенными для этого автоматическими программами – парсерами, которые могут быть как платными, так и бесплатными.
Лучший платный парсер Wordstat – KeyCollector. Используют его в основном те, кто профессионально занимается составлением семантики. Бесплатным аналогом КейКоллектора является программа Словоеб. Функции его урезаны, но составлять небольшие ядра с его помощью вполне реально.
Магадан тоже достаточно популярный парсер Вордстат, который тоже можно бесплатно скачать. Подбирает и анализирует запросы, есть поддержка регионов, предназначен для парсинга фраз Яндекс Директа.
Под конец хочу отметить, что Вордстат дает только те данные, которыми располагает Яндекс. Поэтому например частотность в Гугле и других поисковиках может быть совсем другая.
World Population Milestones
8 Billion (2023)
World population is expected to reach 8 billion people in 2023 according to the United Nations (in 2026 according to the U.S. Census Bureau).
7.9 Billion (2021)
The current world population is 7.9 billion as of April 2021 [] according to the most recent United Nations estimates elaborated by Worldometer. The term «World Population» refers to the human population (the total number of humans currently living) of the world.
Summary Table
1 — 1804 (1803 years): 0.2 to 1 bil.
1804 — 2011 (207 years): from 1 billion to 7 billion
| Year | 1 | 1000 | 1500 | 1650 | 1750 | 1804 | 1850 | 1900 | 1930 | 1950 | 1960 | 1974 | 1980 | 1987 | 1999 | 2011 | 2020 | 2023 | 2030 | 2037 | 2046 | 2057 | 2100 |
| Population | 0.2 | 0.275 | 0.45 | 0.5 | 0.7 | 1 | 1.2 | 1.6 | 2 | 2.55 | 3 | 4 | 4.5 | 5 | 6 | 7 | 7.8 | 8 | 8.5 | 9 | 9.5 | 10 | 10.9 |
Society & Media
New book titles published this year
Sources and info:
- Bowker Book Industry Statistics
- World Economic Outlook (WEO) — International Monetary Fund (IMF)
- UNESCO Institute for Statistics (UIS)- (United Nations Educational, Scientific and Cultural Organization)
Newspapers circulated Today
Sources and info:
World Press Trends — World Association of Newspapers and News Publishers (WAN-IFRA)
TV sets sold worldwide Today
Sources and info:
World Press Trends — World Association of Newspapers and News Publishers (WAN-IFRA)
Cellular phones sold Today
Sources and info:
- Gartner
- IDC Telecom and Networks
$
Money spent on videogames Today
Sources and info:
- Gartner
- DFC Intelligence
- NDP Group — Entertainment Market Research
Internet users in the world today
Sources and info:
- World Development Indicators (WDI) — World Bank
- Measuring the Information Society — International Telecommunications Union (ITU)
- comScore
- GfK group
Sources and info:
The Radicati Group
Blog posts written Today
Sources and info:
- Technorati on State of the Blogosphere reports and elaboration of other data
- WordPress Stats — Automattic Inc.
Tweets sent Today
Sources and info:
Internet Live Stats (InternetLiveStats.com)
Google searches Today
Environment
Forest loss this year (hectares)
Quick Facts:
The number shown up above is net of reforestation
Sources and info:
Global Forest Resources Assessment (2010) — FAO
Land lost to soil erosion this year (ha)
Sources and info:
Dimensions of need: Restoring the land — FAO
CO2 emissions this year (tons)
Quick Facts:
CO2 Emissions shown are from Fossil Fuel Combustion
Sources and info:
- International Energy Agency (IEA) Statistics — CO2 Emissions from Fuel Combustion
- Emission Database for Global Atmospheric Research (EDGAR)
- Carbon Dioxide Information Analysis Center (CDIAC) — United States Department of Energy
- U.S. Energy Information Administration (EIA)
Desertification this year (hectares)
Sources and info:
United Nations Convention to Combat Desertification
Toxic chemicals released in the environment this year (tons)
Как работать с сервисом?
Войти (правый верхний угол) > Регистрация
Инструмент «По словам»
При входе в систему, у вас по умолчанию отображается инструмент «По словам».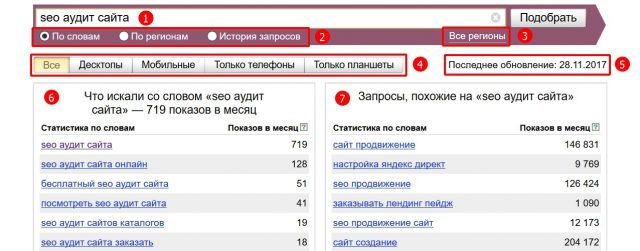
- Поле ввода запроса — в эту строчку мы вводим слово или фразу по которой хотим увидеть данные.
- Инструменты сервиса — отображение слов по регионам и истории(тренд) запроса.
- Все регионы — выбор региона по которому будет отображаться статистика.
- Платформа — выбор платформы по которой будет отображаться статистика.
- Последнее обновление — дата последнего обновления данных в сервисе.
- Левая колонка Wordstat — показывается список запросов в которой содержится введенное в пункте(1) слово или фраза.
- Правая колонка Wordstat — показывается список фраз, которые еще могли искать люди вводившие наше слово или фразу.
Разберем подробнее, как работает левая и правая колонка Яндекс Вордстат.
Левая колонка
В левой колонке отображаются все фразы, которые содержат наш введенный запрос.
Например, мы вводим запрос яндекс вордстат. Нам покажутся все фразы, которые содержат наш запрос, при этом порядок слов не будет иметь значения.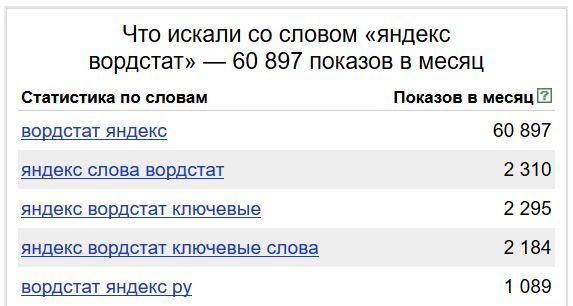
Это надо запомнить! Цифра напротив запроса — количество показов этой фразы в месяц, а не количество переходов по этой фразе! Например, если мы зайдем в поисковую систему https://www.yandex.ru/, наберем фразу яндекс вордстат и нажмем найти — это и будет 1 показ по этой фразе.
Цифра отображает все входящие в него запросы.
Например: В число показов 60 897 по запросу вордстат яндекс входят все числа запросов ниже, которые содержат фразу яндекс вордстат или вордстат яндекс порядок слов не имеет значения.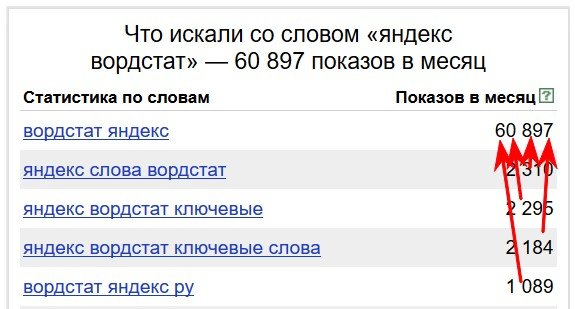
А в число показов 2295 по фразе яндекс вордстат ключевые входит число показов по фразе яндекс вордстат ключевые слова.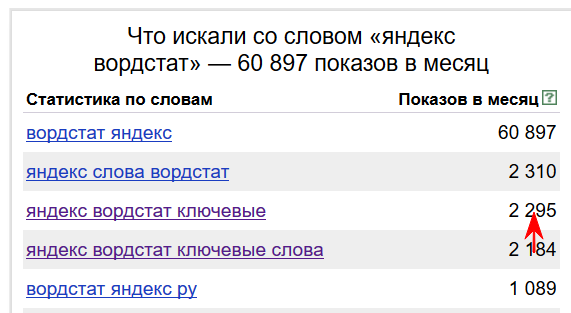
Если мы нажмем на фразу яндекс вордстат ключевые, то мы в этом убедимся. Нам отобразятся все фразы, которые входят в этот запрос.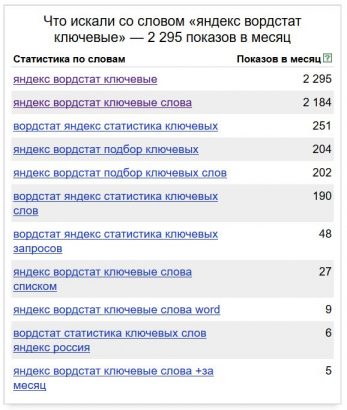
Это основной принцип и логика работы инструмента «По словам» и левой колонки Wordstat. Для более расширенного отображения статистики, существуют операторы подбора слов.
Еще показы называют частотностью (частоткой). Прям так и говорят, частотность фразы яндекс вордстат равна 60 897.
Why Worldometer clocks are the most accurate
The above world population clock is based on the latest estimates released in June of 2019 by the United Nations and will show the same number wherever you are in the world and whatever time you set on your PC. Worldometer is the only website to show live counters that are based on U.N. data and that do not follow the user’s PC clock.Visitors around the world visiting a PC clock based counter, see different numbers depending on where they are located, and in the past have seen other world population clocks — such as the one hosted on a United Nations website and on National Geographic — reaching 7 billion whenever their locally set PC clocks reached 4:21:10 AM on October 31, 2011.
Obviously, the UN data is based on estimates and can’t be 100% accurate, so in all honesty nobody can possibly say with any degree of certainty on which day world population reached 7 billion (or any other exact number), let alone at what time. But once an estimate is made (based on the best data and analysis available), the world population clock should be showing the same number at any given time anywhere around the world.
Другие особенности работы операторов
Выше мы перечислили далеко не все возможности, которые способно предоставить оптимизатору применение операторов в Yandex Wordstat. Вот ещё несколько примеров и правил работы с ними:
В запросе в кавычках » » или прямых скобках местоимения, предлоги и союзы по умолчанию включены, поэтому не обязательно писать перед ними оператор «+».

Важно однако понимать, что операторы минус-слова «-», вертикальная черта «|», группировка запросов «()» не получится использовать внутри операторов кавычки » » или прямые скобки []

Но прямые скобки [] внутри круглых () использовать можно:

В квадратных скобках слова не объединяются:

Оператор » » нельзя применить к отдельной фразе:

Кейс №2
Второй практический пример – нам надо получить маркерные запросы для категории «Стиральные машины Samsung», по которым мы в дальнейшем будем собирать облако запросов и делать теговые страницы. Так как искать данную категорию могут по разным написаниям запросов – стиральная машина, стиральная машинка, Samsung, Самсунг – нам нужно сделать соответствующую регулярку в Вордстате и в 1 клик получить все запросы для данной категории:
стиральные (машины|машинки) (samsung|самсунг) -ремонт -ошибки -отзыв -коды -видео -запчасти –неисправности
Также были добавлены базовые стоп слова, чтобы не получать мусорные запросы.
Отчет «Поисковые запросы»
Один из стандартных отчетов группы «Источники».
В нем – запросы, по которым люди переходят из Яндекса и Google на ваш сайт, и все показатели по ним.
Обратите внимание, соответствует ли каждый запрос (то есть потребность) информации на странице. Если у вас кампания в Яндекс.Директ настроена и синхронизирована с Метрикой, вы можете отфильтровать информационные интересы от коммерческих
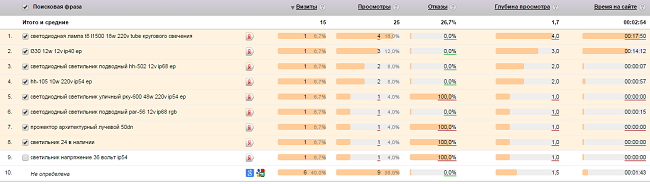
Если вы посмотрите статистику за год, то обнаружите от 500 до 1 000 запросов, по которым вас находят. И многие из них вне семантического ядра. Необходимо включить эти запросы в семантику, чтобы увеличить количество переходов.
World Population clock: sources and methodology
The world population counter displayed on Worldometer takes into consideration data from two major sources: the United Nations and the U.S. Census Bureau.
- The United Nations Population Division of the Department of Economic and Social Affairs every two years calculates, updates, and publishes estimates of total population in its World Population Prospects series. These population estimates and projections provide the standard and consistent set of population figures that are used throughout the United Nations system. The World Population Prospect: the 2019 Revision provides the most recent data available (released in June of 2019). Estimates and projected world population and country specific populations are given from 1950 through 2100 and are released every two years. Worldometer, as it is common practice, utilizes the medium fertility estimates. Data underlying the population estimates are national and sub national census data and data on births, deaths, and migrants available from national sources and publications, as well as from questionnaires. For all countries, census and registration data are evaluated and, if necessary, adjusted for incompleteness by the Population Division as part of its preparations of the official United Nations population estimates and projections.
- The International Programs Center at the U.S. Census Bureau, Population Division also develops estimates and projections based on analysis of available data (based on census, survey, and administrative information) on population, fertility, mortality, and migration for each country or area of the world. According to the U.S. Census Bureau, world population reached 7 billion on March 12, 2012. For most countries adjustment of the data is necessary to correct for errors, omissions, and inconsistencies in the data. Finally, since most recent data for a single country is often at least two years old, the current world population figure is necessarily a projection of past data based on assumed trends. As new data become available, assumptions and data are reevaluated and past conclusions and current figures may be modified. For information about how these estimates and projections are made by the U.S. Census Bureau, see the .
Yandex Wordstat Assistant
Yandex Wordstat Assistant – это расширение для браузера, которое при установке будет появляться только если вы будете находится на по адресу Вордстат Яндекса (wordstat.yandex.ru). Данный плагин дает нам возможность ускорить парсинг ключевых слов к себе в таблицу или текстовый файл.
Напротив каждого ключевого слова появится плюсик, и вы можете нажимая на «плюс» добавлять все интересующие ключевые слова в данное расширение, которое появится слева после установки его из магазина расширений.
Далее вы просто нажимаете на кнопку копировать все запросы, они копируются в буфер обмена вашей операционной системы, и далее вы их можете вставить в текстовый документ.
Таким образом, вам не нужно будет каждое ключевое слова выделять вручную и копировать в текстовый документ. Вы просто выделяете все необходимые ключевые слова, одним нажатием нажимаете «копировать» и вставляете в текстовый документ.
Очень удобно и экономит время на данный рутинный, но крайне необходимый и важны процесс.
Далее вбиваете название расширения — Yandex Wordstat Assistant и устанавливаете его.
После установки и активации расширения, оно сразу появится на страницу https://wordstat.yandex.ru слева, и вы сможете им начать пользоваться.

В плагине вы сможете интуитивно довольно быстро разобраться, поскольку он простой в использовании.
В плагине имеется всего 5 кнопок, и давайте каждую из них более подробно разберём:
- Добавить фразы – дает возможность добавить ключевые слова вручную в плагин. Данной опцией я сам не пользуюсь, поскольку не вижу в ней практического применения.
- Копировать список в буфер обмена – все фразы что были добавлены в плагин, за счет данной кнопки можно скопировать в буфер обмена операционной системы, и вставить в текстовый документ. Копирование происходит только ключевых фраз, без частотностей.
- Копировать список с частотностью в буфер обмена – тоже самое что и предыдущая кнопка, только с копированием частотности к каждой ключевой фразе, которые вы добавили в плагин.
- Сортировка – позволяет отсортировать фразы по частотности, алфавиту, порядку добавления и т. д.
- Очистить список – очищает поле плагина от всех добавленных запросов.
Как я писал выше, у списка ключевых фраз при установленном плагине, появляется плюсик слева от каждого запроса, а также появляется ссылка над всеми запросами «Добавить всё».
Если вам необходимо добавить все слова в плагин, то нажимайте данную ссылку, и все ключевые фразы добавятся в плагин. Оттуда вы их может одним нажатием кнопки скопировать в буфер обмена, и вставить в свой текстовый документ или exel.

Что такое Яндекс Wordstat
Яндекс Wordstat — бесплатный сервис, предназначенный для сбора статистики поисковых запросов в Яндексе. Он помогает рекламодателям и веб-мастерам понять популярность тех или иных ключей, выявить тренды, а также спрос на товары и услуги.
На деле Wordstat отображает прогнозное количество показов ключа в месяц на основе существующей статистики поиска, не включая РСЯ. В списках приводятся как различные вариации исследуемой фразы, так и те, которые наиболее часто ей сопутствуют. На этой основе можно делать выводы о смежных сферах интересов пользователей, которые затем использовать в кампании.
Благодаря сервису у специалиста появляется возможность:
- Собрать основу семантического ядра;
- Ранжировать популярность запросов по регионам;
- По устройствам;
- Выявить сезонность.
А с Calltouch можно анализировать результаты проделанной работы.
Сквозная аналитика
от 990 рублей в месяц
- Автоматически собирайте данные с рекламных площадок, сервисов и CRM в удобные отчеты
- Анализируйте воронку продаж от показов до ROI
- Настройте интеграции c CRM и другими сервисами: более 50 готовых решений
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Кастомизируйте таблицы, добавляйте свои метрики. Стройте отчеты моментально за любые периоды
Узнать подробнее
Между тем, существует ряд ограничений на работу с сервисом. Так, для качественного парсинга и анализа всех ключевых слов специалисту придётся использовать дополнительное программное обеспечение или плагины. Дело в том, что поиск по статистике Яндекса возможен только в ручном режиме. Процесс отсеивания и сбора ключевых фраз становится рутинным и трудоёмким в связи с невозможностью их загрузки на компьютер стандартными средствами сервиса. Из-за этого сбор семантического ядра через Wordstat не может быть произведён в полном объёме, если не прибегать к сторонним инструментам.
Вместе с этим, составление ядра затрудняется и ограничением по объёму выдачи. Если ваш запрос имеет много вариаций и весьма популярен в различных формах, вы вероятно не сможете проанализировать и использовать их все. Вордстат позволяет просмотреть лишь 2000 строк результата — 40 страниц по 50 фраз. Если за пределами остаются важные низкочастотные ключи, вы с трудом сможете их достать стандартными средствами.
Более того, для пользования Wordstat вы должны войти в Яндекс аккаунт. Уже в процессе работы с сервисом вы рискуете постоянно вводить капчу и даже быть забаненными в случае злоупотребления поиском однотипных запросов. Чтобы продолжать пользоваться сервисом в нормальном режиме, вы можете попробовать вводить слова в разных падежах. Например: вордстат Яндекс, вордстата Яндекса.
Проверка частотности: 80 lvl
Переходим к более сложным тонкостям сбора статистики по запросам из Яндекса.
Пример #1
Начнем с оператора » » и сформулируем одно правило его использования: если во фразе, заключенной в кавычки, присутствуют одинаковые предлоги или слова, то одно из них заменяется на существующее слово во вложенном запросе. Для примера рассмотрим запрос «автомобиль в кредит москва».

Если добавить в данное ключевое слово еще один предлог «в» перед словом «москва», то получим следующие данные.

Таким образом повторяющиеся предлоги «в» были объединены, и к запросам добавилось еще одно слово. Для разных запросов это слова «купить», «бу», «новый», «залог», подержанные». «оформить».
Этот прием — невероятный инструмент для информационный сайтов, основной целью которых является рост трафика. Он позволяет выбрать из тематики весь диапазон запросов, которые включают в себя заданное количество слов, например, все запросы по тематике из 5 слов. Как правило, очень расширенные запросы из 5-7 слов бывают менее конкурентными, соответственно привлечь трафик и занять высокие позиции по ним легче. А если эти запросы не уступают в показах высокочастотным запросам? Выборка наиболее высокочастотных и наименее конкурентных запросов позволит вам быстро добиться результата. Давайте рассмотрим пример.

В данном запросе мы просим WordStat показать диапазон запросов, который включает в себя 7 слов, обязательно содержащих слова «инструкция по применения». 5 слов «инструкция» объединяются, остается одно, 4 слова заменяются на новые вложенные запросы. Смотрим один из сотен вложенных запросов, частотность запроса из 7 слов — 8090 показов в месяц. Для сравнению запрос «купить автомобиль в москве» имеет 647 показов в месяц. Разрыв шаблона еще не произошел? Тогда идем дальше.

Пример #2
Сейчас пойдет в бой более сложный оператор () и |, с его помощью мы соберем пул запросов, из которого в дальнейшем сможем сделать теговые страницы. Возьмем для примера запрос «купить автомобиль bmw». Данную марку авто, ее серии могут искать по самым разным запросам: «купить машину бмв», «купить bmw икс 6», «купить автомобиль бмв 5» и т.п. Для того чтобы получить пул запросов без повторений, используем регулярное выражение:
купить (автомобиль|машина) (бмв|bmw) -пробегом -фото -не -заводится -скачать -бу -какая
Добавим в него сразу ряд нерелевантных минус-слов, которые не подходят для нашего бизнеса. Получаем следующие данные, которые впоследствие проще структурировать.

Данная выборка поможет вам проще собрать данные для теговых страниц и кластеризации данных.
Обратите внимание, нельзя в одном выражении использовать операторы » » и ( ) |. Логика работы одного оператора нарушает логику работы другого
Пример #3
рыбалка (+с|+на) -игра -бесплатная -скачать -русские -охота
Минус-слова, конечно же, нужно добавить, но в данном случае это просто пример. Получаем вот такой результат:

Пример #4
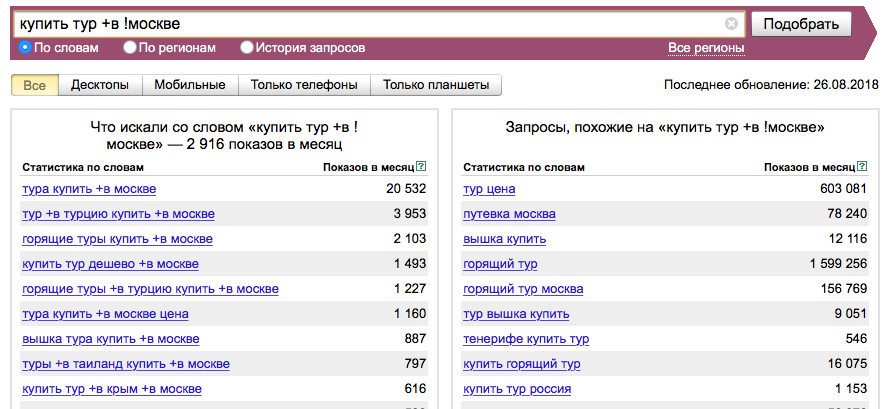
Совместное использование операторов поможет вам разграничить похожие по написанию, но разные по смыслу запросы. Например, запрос «купить тур в москвУ» подразумевает экскурсионную поезду в Москву.

Запрос «купить тур в москвЕ» подразумевает учет геопозиции пользователя для покупки тура из Москвы.
Пример #5
Еще один пример регулярного выражения, которое поможет вам собрать запросы для теговых страниц или фильтров каталога в нише купальников.

Даже если данные примеры не относятся к вашей нише, надеемся они помогут вам улучшить свои навыки работы с WordStat. Если у вас возникли вопросы, вы нашли ошибки, либо хотите дополнить статью, пожалуйста, пишите в комментарии, мы с радостью ответим вам!
Особенности использования Яндекс.Wordstat
При использовании сервиса помните:
- Яндекс.Wordstat не показывает тренды. Здесь можно узнать статистику показов в течение последнего месяца.
- Есть возможность оценить сезонность запросов с помощью «Истории запросов».
- В «Истории запросов» операторы не используются.
- Данные в «Истории запросов» показывают в абсолютных и относительных цифрах. В первом случае количество показов по рассматриваемой фразе. Во втором — соотношение показов по этому слову и всех запросов в течение этого же времени.
- Существуют ограничения на результаты выдачи. На странице может быть представлено не более 50 запросов. При этом максимальное количество страниц — 40.
Яндекс Вордстат — ключевые моменты
При игнорировании служебных команд Yandex Wordstat не отображает точное количество показов по заданной фразе. На это указывает фраза «Что искали со словом…», подразумевающая, что вместе с заданным Яндекс запросом отобразились запросы, в которых встречаются указанные ключевые слова.
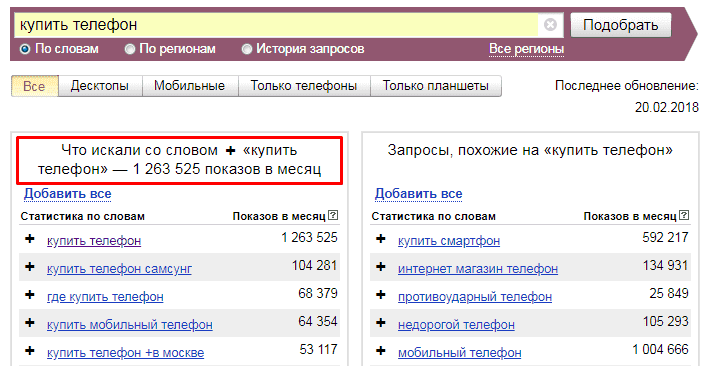
Для уточнения запросов в Яндексе применяются специальные символы и операторы.
Операторы Яндекса
Оператор «-» — предоставляет возможность исключить слова.
Оператор «+» — направлен на принудительное использование слова.
Оператор кавычки «» — отображает данные статистики исключительно для одного слова, без участия в иных сочетаниях.
Оператор «!» — предназначен для вывода статистических данных в точном вхождении.
Допустим, стоит задача определить количество запросов по конкретной ключевой фразе. В таком случае используйте операторы «» и!. Поместив запрос в кавычки, вы зададите команду показывать в результате выдачи только те слова и словосочетания, которые заключены в кавычки.
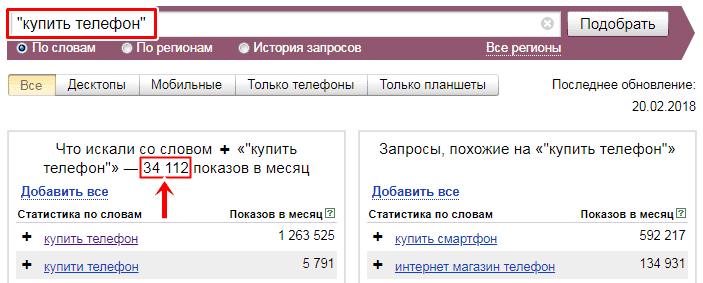
С помощью восклицательного знака предоставляется возможность исключить все ненужные словоформы. Для этого достаточно заключить Яндекс запрос в кавычки и перед каждым словом поставить восклицательный знак.
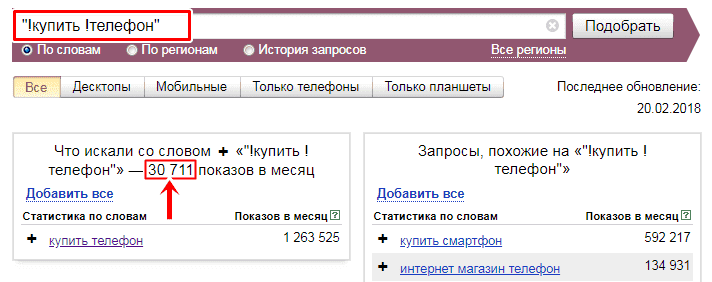
Итог
Подобрать ключевые слова для статьи не так уж и сложно и Яндекс Вордстат в этом деле станет незаменимым помощником. Не забывайте пользоваться операторами, которые позволят получить более конкретные данные по частоте использования интересующих вас запросов, что позволит подобрать наиболее релевантные ключевики.